LG-Gaze: Learning Geometry-aware Continuous Prompts for Language-Guided Gaze Estimation
作者: Pengwei Yin, Jingjing Wang, Guanzhong Zeng, Di Xie, Jiang Zhu
分类: cs.CV
发布日期: 2024-11-13
备注: Accepted to ECCV 2024
💡 一句话要点
提出LG-Gaze,利用几何感知连续提示学习进行语言引导的注视估计
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 注视估计 视觉-语言模型 领域泛化 对比学习 几何感知 连续提示学习 人机交互
📋 核心要点
- 现有注视估计模型在数据有限时泛化能力差,且领域泛化方法易过拟合。
- LG-Gaze将注视估计视为视觉-语言对齐问题,利用预训练模型的语义信息。
- 通过多模态对比回归损失和几何感知插值,LG-Gaze在跨域评估中表现出色。
📝 摘要(中文)
注视估计模型的泛化能力常常受到与注视无关的因素的严重阻碍,尤其是在训练数据集有限的情况下。现有的策略旨在通过不同的领域泛化技术来解决这一挑战,但由于仅仅依赖于回归的值标签时存在过拟合的风险,因此收效甚微。预训练的视觉-语言模型的最新进展促使我们利用丰富的语义信息。在本文中,我们提出了一种新颖的方法,将注视估计任务重新定义为视觉-语言对齐问题。我们提出的框架,名为语言引导的注视估计(LG-Gaze),学习连续的和几何敏感的特征用于注视估计,受益于视觉-语言模型的丰富先验知识。具体来说,LG-Gaze通过我们提出的多模态对比回归损失将注视特征与连续语言特征对齐,该损失为不同的负样本定制自适应权重。此外,为了更好地适应注视估计任务的标签,我们提出了一种几何感知插值方法来获得更精确的注视嵌入。通过大量的实验,我们验证了我们的框架在四个不同的跨域评估任务中的有效性。
🔬 方法详解
问题定义:现有的注视估计模型在跨域泛化能力上存在不足,尤其是在训练数据有限的情况下。传统的领域泛化方法容易过拟合,无法充分利用图像中蕴含的丰富语义信息。因此,如何有效地利用先验知识,提升模型的泛化能力,是注视估计领域面临的一个重要挑战。
核心思路:LG-Gaze的核心思路是将注视估计问题转化为一个视觉-语言对齐问题。通过利用预训练的视觉-语言模型,可以有效地利用图像中的语义信息,从而提升模型的泛化能力。此外,通过设计几何感知的连续提示学习方法,可以更好地适应注视估计任务的特点。
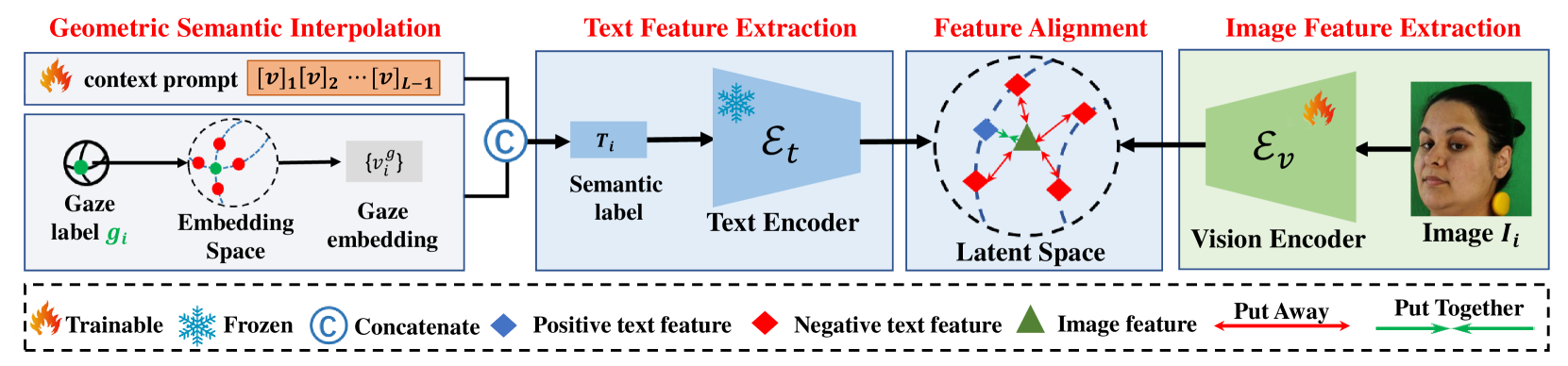
技术框架:LG-Gaze框架主要包含以下几个模块:1) 视觉特征提取模块:用于提取人脸图像的视觉特征。2) 语言特征生成模块:用于生成与注视方向相关的语言特征。3) 多模态对比回归模块:用于将视觉特征和语言特征对齐,并进行注视方向的回归。4) 几何感知插值模块:用于优化注视嵌入,提高精度。整体流程是,首先输入人脸图像,经过视觉特征提取模块得到视觉特征,然后通过语言特征生成模块得到语言特征,接着利用多模态对比回归模块进行对齐和回归,最后通过几何感知插值模块优化结果。
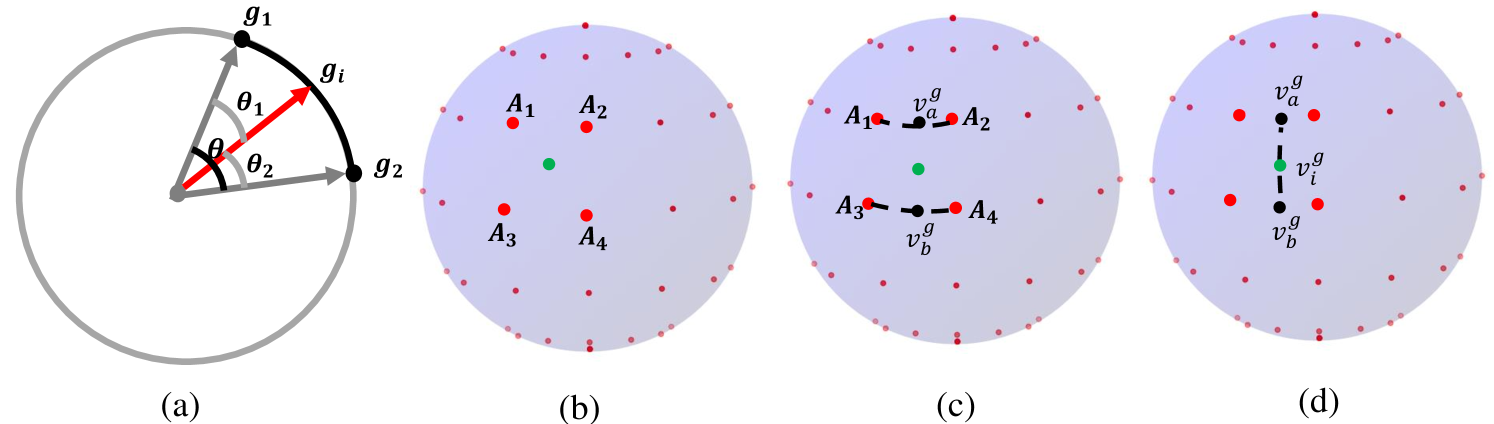
关键创新:LG-Gaze的关键创新在于以下几个方面:1) 将注视估计问题转化为视觉-语言对齐问题,充分利用了预训练模型的语义信息。2) 提出了多模态对比回归损失,能够自适应地调整不同负样本的权重,从而提高模型的性能。3) 提出了几何感知插值方法,能够更好地适应注视估计任务的特点,提高注视估计的精度。与现有方法相比,LG-Gaze能够更好地利用图像中的语义信息,并且能够更好地适应注视估计任务的特点。
关键设计:在多模态对比回归损失中,采用了自适应权重策略,根据负样本与正样本的相似度来调整权重。几何感知插值方法利用了注视方向的几何信息,通过插值的方式来优化注视嵌入。具体的网络结构和参数设置在论文中有详细描述。
🖼️ 关键图片

📊 实验亮点
LG-Gaze在四个不同的跨域评估任务中都取得了显著的性能提升,验证了其有效性。具体的性能数据和对比基线在论文中有详细的展示。实验结果表明,LG-Gaze能够有效地利用图像中的语义信息,并且能够更好地适应注视估计任务的特点,从而提高注视估计的精度和泛化能力。
🎯 应用场景
LG-Gaze在人机交互、虚拟现实、驾驶辅助等领域具有广泛的应用前景。通过准确估计用户的注视方向,可以实现更自然、更智能的人机交互方式。在虚拟现实中,可以根据用户的注视方向来调整场景的渲染,从而提高用户的沉浸感。在驾驶辅助系统中,可以利用注视估计来判断驾驶员的注意力是否集中,从而提高驾驶安全性。
📄 摘要(原文)
The ability of gaze estimation models to generalize is often significantly hindered by various factors unrelated to gaze, especially when the training dataset is limited. Current strategies aim to address this challenge through different domain generalization techniques, yet they have had limited success due to the risk of overfitting when solely relying on value labels for regression. Recent progress in pre-trained vision-language models has motivated us to capitalize on the abundant semantic information available. We propose a novel approach in this paper, reframing the gaze estimation task as a vision-language alignment issue. Our proposed framework, named Language-Guided Gaze Estimation (LG-Gaze), learns continuous and geometry-sensitive features for gaze estimation benefit from the rich prior knowledges of vision-language models. Specifically, LG-Gaze aligns gaze features with continuous linguistic features through our proposed multimodal contrastive regression loss, which customizes adaptive weights for different negative samples. Furthermore, to better adapt to the labels for gaze estimation task, we propose a geometry-aware interpolation method to obtain more precise gaze embeddings. Through extensive experiments, we validate the efficacy of our framework in four different cross-domain evaluation tasks.