The VLLM Safety Paradox: Dual Ease in Jailbreak Attack and Defense
作者: Yangyang Guo, Fangkai Jiao, Liqiang Nie, Mohan Kankanhalli
分类: cs.CR, cs.CV
发布日期: 2024-11-13 (更新: 2025-03-06)
备注: Logic smoothing and language polishing
💡 一句话要点
揭示VLLM安全悖论:越狱攻击与防御的双重易用性,提出LLM-Pipeline防御方法。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉大语言模型 越狱攻击 安全防御 LLM-Pipeline 安全评估
📋 核心要点
- 现有VLLM防御机制在基准测试中表现出近乎饱和的性能,但同时也容易受到越狱攻击,这种“双重高性能”现象构成安全悖论。
- 论文提出LLM-Pipeline方法,利用现有LLM的护栏机制,在VLLM响应前进行安全检测,以提高防御的可靠性。
- 研究发现现有越狱攻击评估方法存在偶然一致性问题,可能误导对攻击策略和防御机制的评估。
📝 摘要(中文)
视觉大语言模型(VLLM)易受越狱攻击并不令人意外。然而,针对这些攻击的最新防御机制在基准评估中已接近饱和性能,且通常只需极少的努力。这种攻击和防御的“双重高性能”提出了一个根本且令人困惑的悖论。为了深入理解这个问题,从而进一步加强VLLM的可信度,本文做出了三个关键贡献:i) 对VLLM易受越狱攻击的一种初步解释——包含视觉输入,并对其进行了深入分析。ii) 认识到现有防御机制中一个被严重忽略的问题——过度谨慎。这个问题导致这些防御方法表现出无意的弃权,即使在存在良性输入的情况下也是如此,从而损害了它们在忠实防御攻击方面的可靠性。iii) 一种简单的安全感知方法——LLM-Pipeline。我们的方法重新利用了现成的更高级的LLM护栏,作为VLLM响应之前的有效替代检测器。最后但并非最不重要的一点是,我们发现两种具有代表性的越狱评估方法通常表现出偶然的一致性。这种局限性使得在评估攻击策略或防御机制时可能具有误导性。我们相信本文的研究结果为重新思考VLLM安全的基础开发(关于基准数据集、防御策略和评估方法)提供了有用的见解。
🔬 方法详解
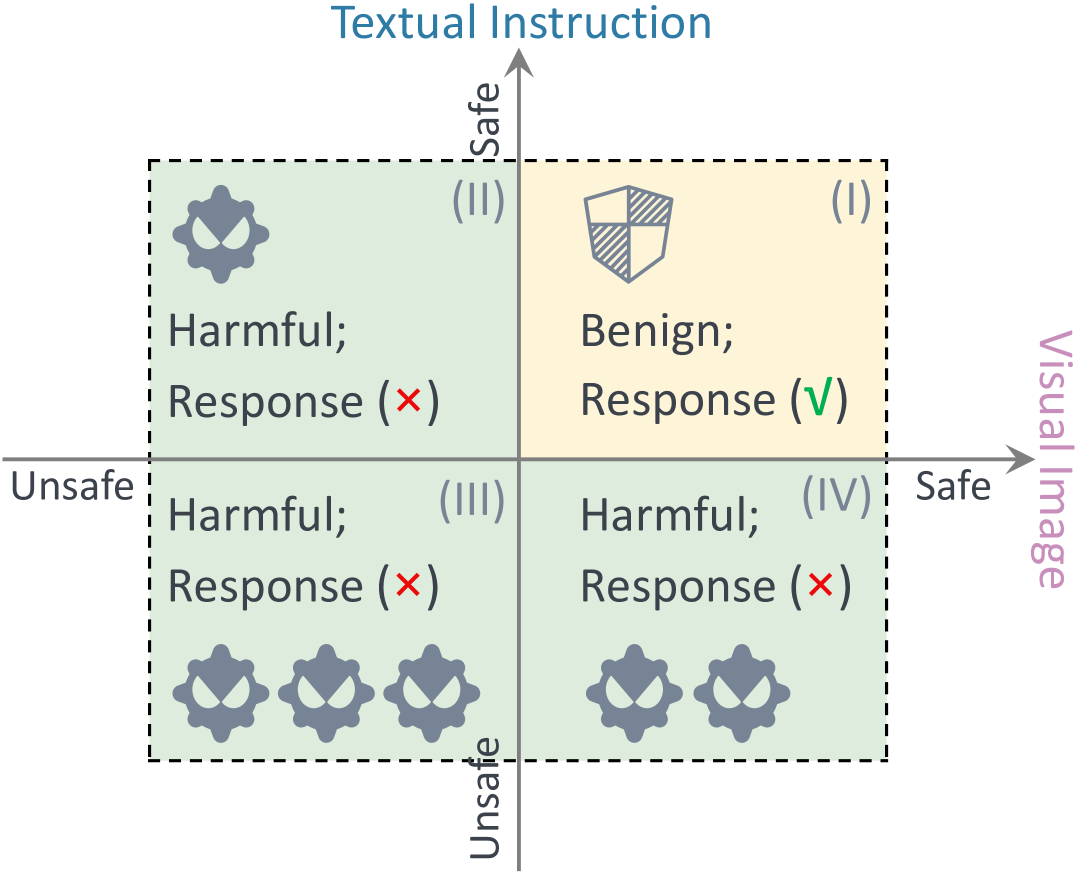
问题定义:VLLM在越狱攻击和防御上同时表现出高性能,即VLLM既容易被攻击绕过安全限制,现有的防御机制又能轻易达到很高的防御准确率。这种现象的背后原因尚不明确,现有的防御机制可能存在过度谨慎的问题,导致对正常输入也产生误判。
核心思路:论文的核心思路是利用现有的、更成熟的LLM的安全机制,构建一个pipeline,在VLLM响应之前进行安全检测。这样可以避免VLLM自身安全机制的不足,提高防御的可靠性。同时,论文还分析了视觉输入对VLLM安全性的影响,以及现有评估方法的局限性。
技术框架:LLM-Pipeline方法包含两个主要阶段:首先,接收到用户输入(包含视觉信息)后,不直接交给VLLM处理,而是先将输入传递给一个预先训练好的、具有更强安全护栏的LLM。这个LLM作为安全检测器,判断输入是否存在潜在的恶意或越狱企图。如果检测器认为输入安全,则将其传递给VLLM进行处理并生成响应;否则,拒绝响应或采取其他安全措施。
关键创新:关键创新在于将LLM的安全护栏机制前置于VLLM,形成一个pipeline。这种方法避免了直接依赖VLLM自身可能存在缺陷的安全机制,而是利用了更成熟、更可靠的LLM安全能力。此外,论文还指出了现有越狱攻击评估方法的局限性,并分析了视觉输入对VLLM安全性的影响。
关键设计:LLM-Pipeline的关键设计在于选择合适的LLM作为安全检测器。需要选择具有强大安全护栏、能够有效识别恶意输入的LLM。此外,还需要设计合适的prompt,引导LLM进行安全判断。具体的参数设置和损失函数取决于所选LLM的特性和训练方式。论文中没有明确给出具体的参数设置和损失函数,这部分可能需要根据实际情况进行调整。
🖼️ 关键图片


📊 实验亮点
论文提出了LLM-Pipeline方法,利用现有的LLM安全护栏机制,有效提高了VLLM的安全性。实验结果表明,该方法能够有效防御越狱攻击,并且避免了过度谨慎的问题,提高了防御的可靠性。此外,论文还指出了现有越狱攻击评估方法存在偶然一致性问题,为未来的研究提供了重要的参考。
🎯 应用场景
该研究成果可应用于各种需要使用VLLM的场景,例如智能客服、图像内容审核、自动驾驶等。通过提高VLLM的安全性,可以防止恶意用户利用越狱攻击获取不当信息或执行恶意操作,从而保障系统的安全性和可靠性。未来的研究可以进一步探索更有效的防御机制和更可靠的评估方法。
📄 摘要(原文)
The vulnerability of Vision Large Language Models (VLLMs) to jailbreak attacks appears as no surprise. However, recent defense mechanisms against these attacks have reached near-saturation performance on benchmark evaluations, often with minimal effort. This \emph{dual high performance} in both attack and defense raises a fundamental and perplexing paradox. To gain a deep understanding of this issue and thus further help strengthen the trustworthiness of VLLMs, this paper makes three key contributions: i) One tentative explanation for VLLMs being prone to jailbreak attacks--\textbf{inclusion of vision inputs}, as well as its in-depth analysis. ii) The recognition of a largely ignored problem in existing defense mechanisms--\textbf{over-prudence}. The problem causes these defense methods to exhibit unintended abstention, even in the presence of benign inputs, thereby undermining their reliability in faithfully defending against attacks. iii) A simple safety-aware method--\textbf{LLM-Pipeline}. Our method repurposes the more advanced guardrails of LLMs on the shelf, serving as an effective alternative detector prior to VLLM response. Last but not least, we find that the two representative evaluation methods for jailbreak often exhibit chance agreement. This limitation makes it potentially misleading when evaluating attack strategies or defense mechanisms. We believe the findings from this paper offer useful insights to rethink the foundational development of VLLM safety with respect to benchmark datasets, defense strategies, and evaluation methods.