EgoVid-5M: A Large-Scale Video-Action Dataset for Egocentric Video Generation
作者: Xiaofeng Wang, Kang Zhao, Feng Liu, Jiayu Wang, Guosheng Zhao, Xiaoyi Bao, Zheng Zhu, Yingya Zhang, Xingang Wang
分类: cs.CV
发布日期: 2024-11-13
备注: Project Page: https://egovid.github.io/
💡 一句话要点
提出EgoVid-5M大规模第一人称视频数据集,用于提升主观视角视频生成效果。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱六:视频提取与匹配 (Video Extraction)
关键词: 第一人称视频生成 视频数据集 动作标注 数据清洗 运动学控制
📋 核心要点
- 现有数据集难以满足第一人称视角视频生成的需求,主要挑战在于视角动态性、动作多样性和场景复杂性。
- 论文核心在于构建大规模高质量数据集EgoVid-5M,并提供细粒度动作标注和数据清洗流程,保证数据质量。
- 论文提出了EgoDreamer模型,该模型能够根据动作描述和运动学控制信号生成第一人称视角视频。
📝 摘要(中文)
视频生成已成为一种有前景的世界模拟工具,它利用视觉数据来复制真实世界的环境。其中,以人为中心的第一人称视频生成在增强虚拟现实、增强现实和游戏等应用方面具有巨大的潜力。然而,由于第一人称视角的动态性、动作的复杂多样性以及场景的复杂性,第一人称视频的生成面临着巨大的挑战。现有的数据集不足以有效地应对这些挑战。为了弥合这一差距,我们提出了EgoVid-5M,这是第一个专门为第一人称视频生成而策划的高质量数据集。EgoVid-5M包含500万个第一人称视频片段,并包含详细的动作注释,包括细粒度的运动学控制和高级文本描述。为了确保数据集的完整性和可用性,我们实施了一个复杂的数据清理流程,旨在保持第一人称条件下的帧一致性、动作连贯性和运动平滑性。此外,我们还介绍了EgoDreamer,它能够生成由动作描述和运动学控制信号同时驱动的第一人称视频。EgoVid-5M数据集、相关的动作注释以及所有数据清理元数据将发布,以促进第一人称视频生成的研究。
🔬 方法详解
问题定义:现有第一人称视频生成数据集规模不足,难以覆盖真实世界中复杂多样的场景和动作。同时,缺乏细粒度的动作标注和有效的数据清洗流程,导致生成视频质量不高,难以满足实际应用需求。
核心思路:通过构建大规模、高质量的EgoVid-5M数据集,并提供详细的动作标注和数据清洗流程,为第一人称视频生成研究提供坚实的数据基础。同时,提出EgoDreamer模型,利用动作描述和运动学控制信号,实现更精确和可控的视频生成。
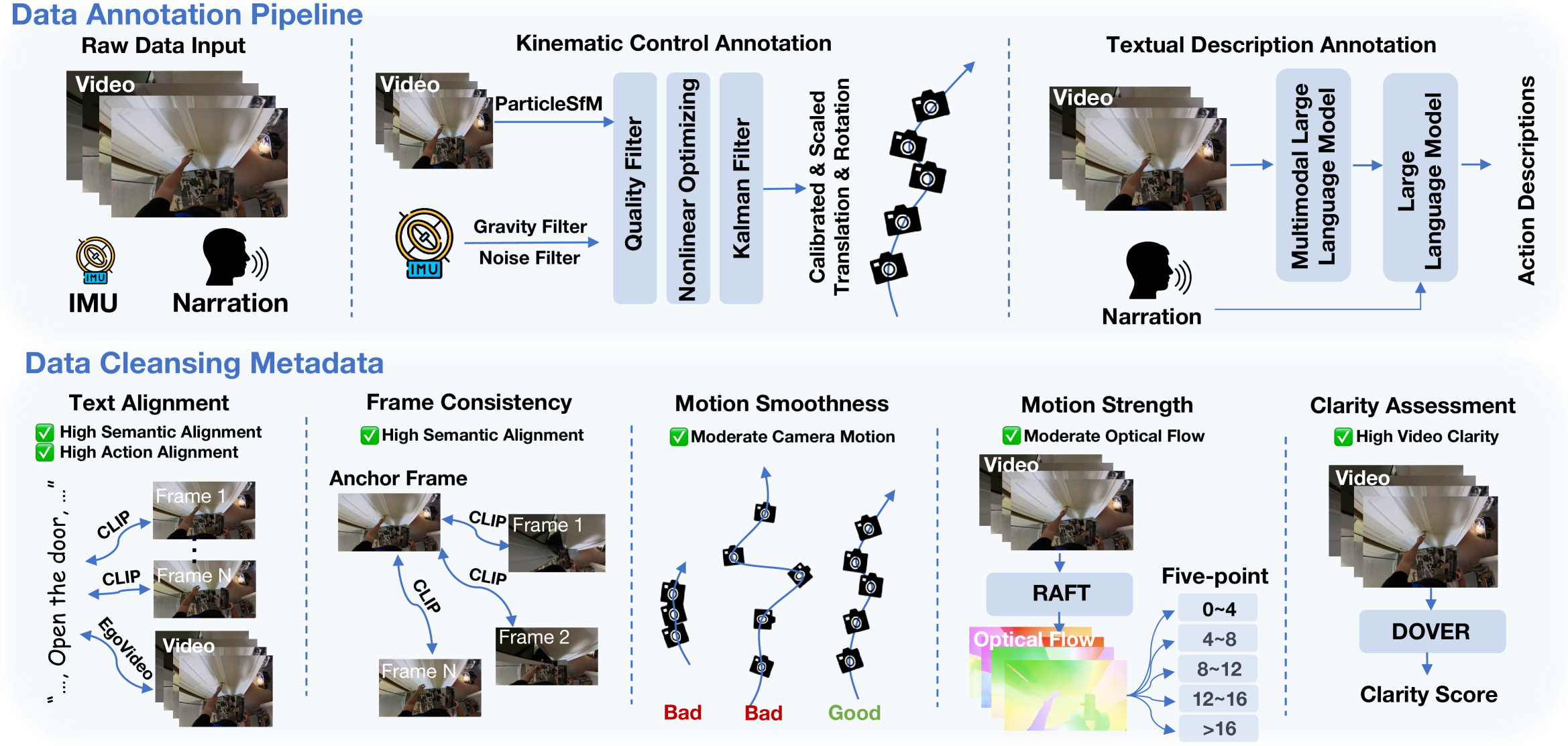
技术框架:整体框架包含数据收集、数据清洗、动作标注和模型训练四个主要阶段。数据收集阶段利用多种渠道获取大量第一人称视频数据。数据清洗阶段采用复杂的数据清洗流程,保证帧一致性、动作连贯性和运动平滑性。动作标注阶段提供细粒度的运动学控制和高级文本描述。模型训练阶段利用EgoVid-5M数据集训练EgoDreamer模型。
关键创新:EgoVid-5M数据集是首个专门为第一人称视频生成而策划的大规模高质量数据集。其创新之处在于数据集的规模、质量和标注的详细程度。EgoDreamer模型则创新性地结合了动作描述和运动学控制信号,实现了更精确和可控的视频生成。
关键设计:数据清洗流程包含多个步骤,例如重复帧删除、异常帧检测和运动平滑处理。动作标注采用人工标注和自动标注相结合的方式,保证标注的准确性和效率。EgoDreamer模型采用Transformer架构,利用注意力机制学习动作描述和运动学控制信号之间的关系。损失函数包括视频重建损失、动作预测损失和对抗损失等。
🖼️ 关键图片


📊 实验亮点
论文构建了包含500万个第一人称视频片段的EgoVid-5M数据集,并进行了详细的动作标注。提出的EgoDreamer模型能够根据动作描述和运动学控制信号生成高质量的第一人称视频。虽然论文中没有给出具体的性能数据,但数据集的发布将极大地促进第一人称视频生成领域的研究。
🎯 应用场景
该研究成果可广泛应用于虚拟现实、增强现实、游戏等领域。例如,可以用于生成逼真的虚拟环境,提升用户沉浸感;可以用于创建智能助手,根据用户指令生成相应的动作视频;还可以用于开发更具互动性的游戏体验。未来,该技术有望应用于机器人控制、自动驾驶等领域。
📄 摘要(原文)
Video generation has emerged as a promising tool for world simulation, leveraging visual data to replicate real-world environments. Within this context, egocentric video generation, which centers on the human perspective, holds significant potential for enhancing applications in virtual reality, augmented reality, and gaming. However, the generation of egocentric videos presents substantial challenges due to the dynamic nature of egocentric viewpoints, the intricate diversity of actions, and the complex variety of scenes encountered. Existing datasets are inadequate for addressing these challenges effectively. To bridge this gap, we present EgoVid-5M, the first high-quality dataset specifically curated for egocentric video generation. EgoVid-5M encompasses 5 million egocentric video clips and is enriched with detailed action annotations, including fine-grained kinematic control and high-level textual descriptions. To ensure the integrity and usability of the dataset, we implement a sophisticated data cleaning pipeline designed to maintain frame consistency, action coherence, and motion smoothness under egocentric conditions. Furthermore, we introduce EgoDreamer, which is capable of generating egocentric videos driven simultaneously by action descriptions and kinematic control signals. The EgoVid-5M dataset, associated action annotations, and all data cleansing metadata will be released for the advancement of research in egocentric video generation.