MIRe: Enhancing Multimodal Queries Representation via Fusion-Free Modality Interaction for Multimodal Retrieval
作者: Yeong-Joon Ju, Ho-Joong Kim, Seong-Whan Lee
分类: cs.CV, cs.AI, cs.IR, cs.MM
发布日期: 2024-11-13 (更新: 2025-05-21)
备注: Accepted to ACL 2025 (Findings)
🔗 代码/项目: GITHUB
💡 一句话要点
MIRe:通过无融合模态交互增强多模态查询表示,用于多模态检索
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态检索 模态交互 文本主导问题 无融合 预训练 视觉-文本对齐 零样本学习
📋 核心要点
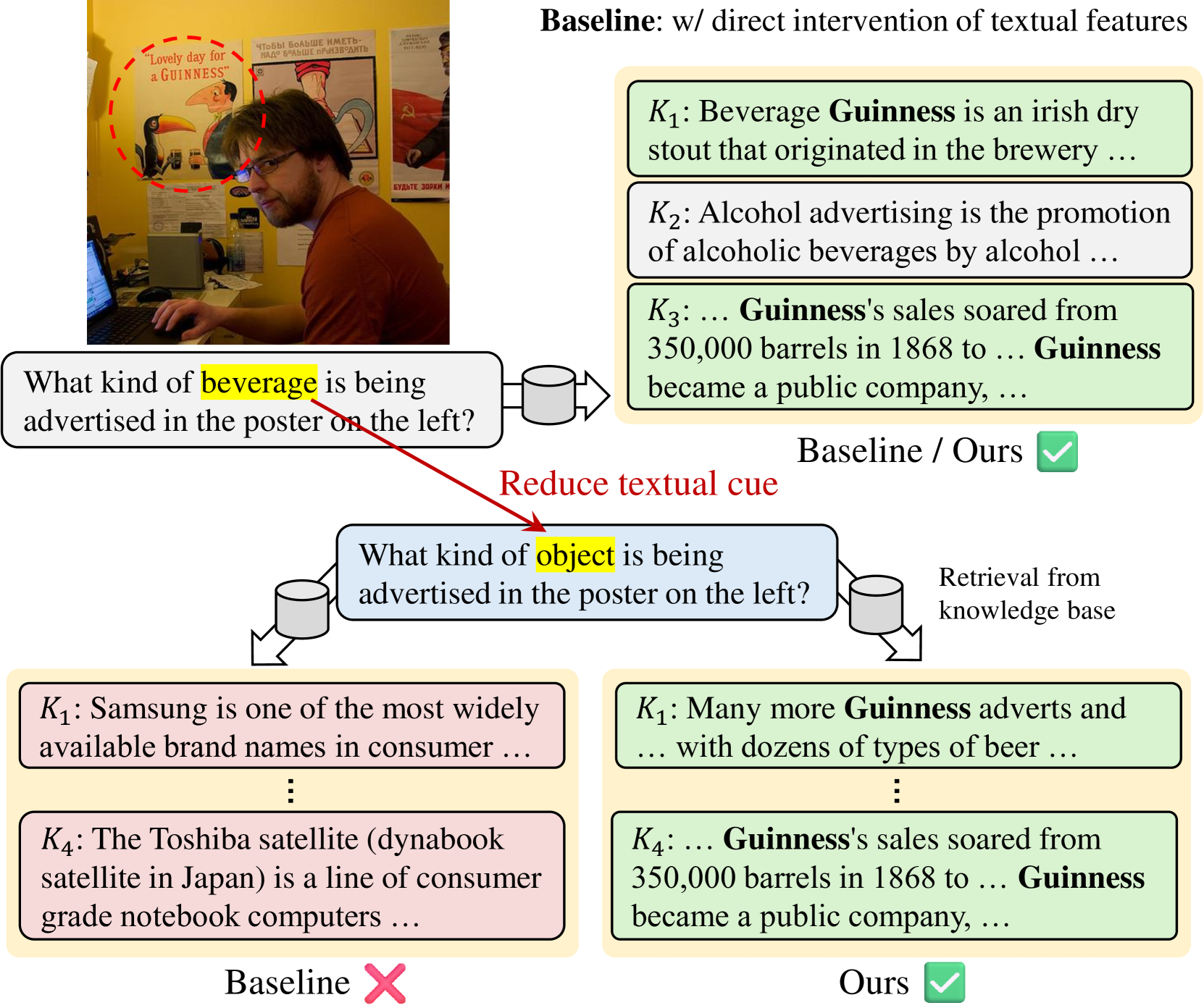
- 现有方法在多模态检索中存在文本主导问题,过度依赖文本信息,忽略了视觉信息。
- MIRe通过无融合的模态交互,允许文本查询关注视觉信息,同时避免文本信息反向影响视觉表示。
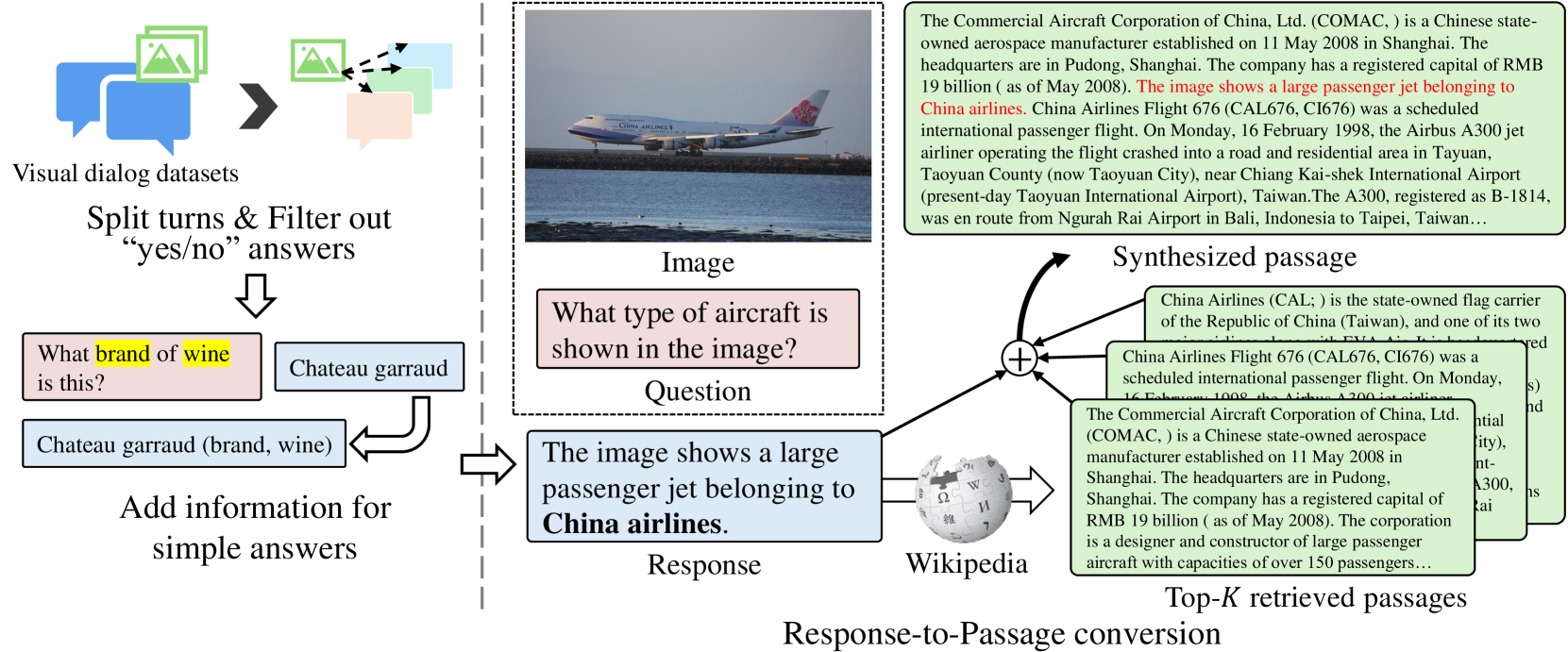
- 通过构建新的预训练数据集,将问答对扩展为段落,显著提升了模型在多模态检索任务上的零样本性能。
📝 摘要(中文)
本文提出了一种名为MIRe的检索框架,旨在通过无融合的模态交互来增强多模态查询表示,从而提升多模态检索的性能。现有方法在视觉-文本对齐过程中直接融合两种模态,但容易产生文本主导问题,过度依赖文本驱动的信号,忽略了关键的视觉信息。MIRe允许文本查询关注视觉嵌入,同时避免将文本驱动的信号反馈到视觉表示中。此外,本文还构建了一个多模态查询检索的预训练数据集,通过将简洁的问答对转换为扩展的段落来增强模型对多模态查询的理解。实验结果表明,该预训练策略显著提升了模型在四个多模态检索基准测试上的零样本性能。消融实验和分析验证了该框架在缓解文本主导问题方面的有效性。代码已公开。
🔬 方法详解
问题定义:现有基于视觉-文本对齐的多模态检索方法,通常直接融合文本和视觉特征进行交叉引用,以理解多模态查询。然而,这种融合方式容易导致“文本主导”问题,即模型过度依赖文本信息,而忽略了重要的视觉信息,从而影响检索性能。
核心思路:MIRe的核心思路是在模态交互过程中避免直接融合文本特征。具体来说,允许文本查询去关注视觉嵌入,但阻止文本驱动的信号反馈到视觉表示中。这样可以减轻文本主导问题,使模型更平衡地利用文本和视觉信息。
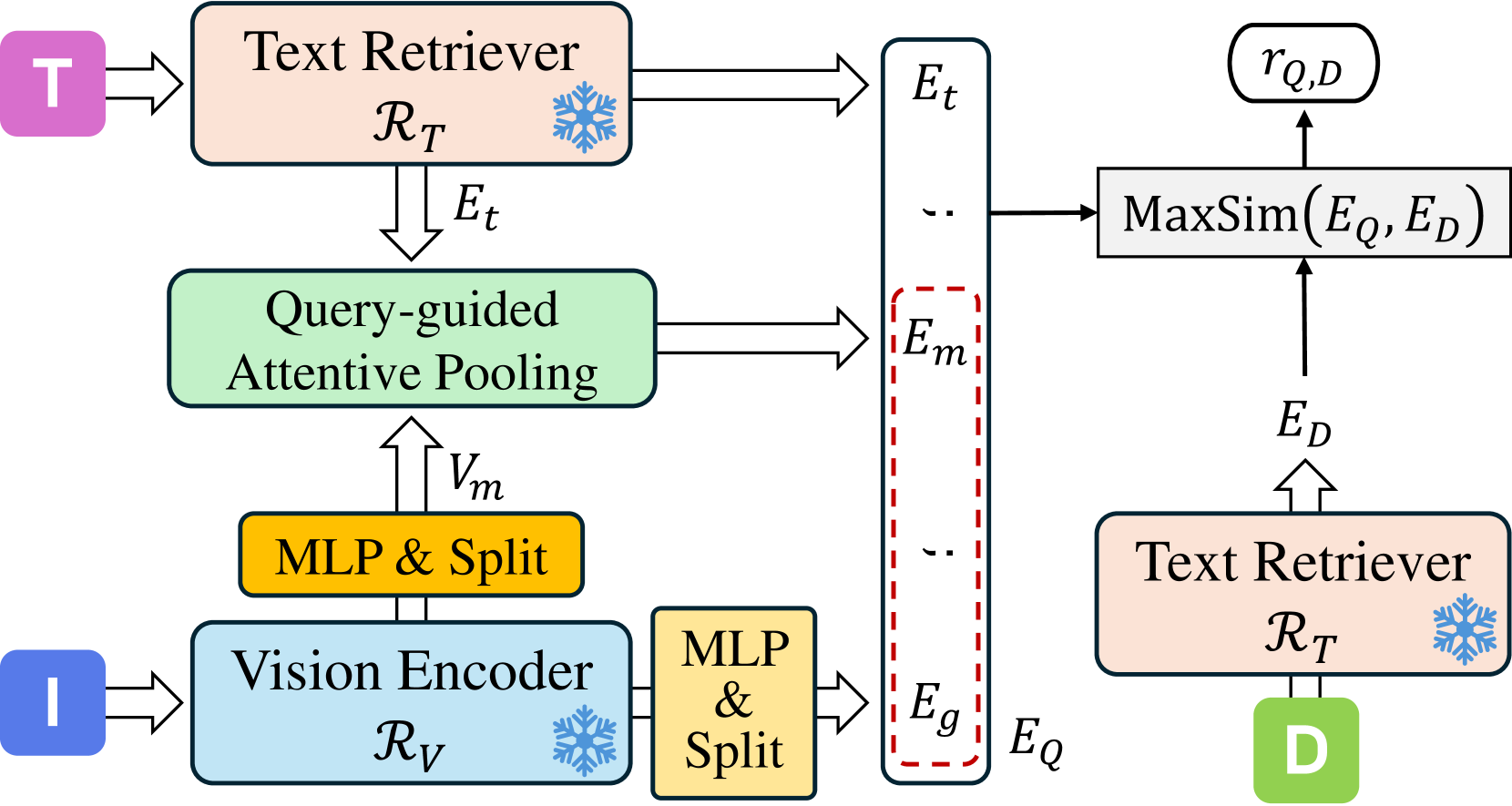
技术框架:MIRe框架主要包含以下几个阶段:1) 视觉特征提取:使用预训练的视觉模型提取图像的视觉特征。2) 文本特征提取:使用预训练的文本模型提取文本查询的文本特征。3) 无融合模态交互:文本特征作为query,对视觉特征进行attention操作,得到融合后的表示,但视觉特征不反向接收文本信息。4) 检索:使用融合后的表示进行检索,找到与查询最相关的图像。
关键创新:MIRe的关键创新在于提出了“无融合模态交互”机制。与现有方法直接融合文本和视觉特征不同,MIRe通过单向的attention机制,允许文本查询关注视觉信息,但阻止文本信息反向影响视觉表示。这种设计有效地缓解了文本主导问题。此外,构建了新的预训练数据集,通过将问答对扩展为段落,增强模型对多模态查询的理解。
关键设计:MIRe的关键设计包括:1) 使用预训练的视觉和文本模型,例如CLIP等,以获得高质量的特征表示。2) 使用单向的attention机制进行模态交互,避免文本信息反向影响视觉表示。3) 构建新的预训练数据集,通过将问答对扩展为段落,增强模型对多模态查询的理解。具体的损失函数和网络结构细节在论文中进行了详细描述。
🖼️ 关键图片
📊 实验亮点
实验结果表明,MIRe在四个多模态检索基准测试上取得了显著的性能提升。在零样本设置下,MIRe优于现有的方法,证明了其在缓解文本主导问题方面的有效性。消融实验进一步验证了无融合模态交互和预训练策略的有效性。具体性能数据和对比基线在论文中进行了详细展示。
🎯 应用场景
MIRe框架可应用于各种多模态检索场景,例如图像搜索、视频搜索、商品搜索等。通过提升模型对多模态查询的理解能力,可以更准确地找到用户所需的内容。该研究对于提升多模态信息检索的效率和用户体验具有重要价值,未来可应用于智能客服、智能助手等领域。
📄 摘要(原文)
Recent multimodal retrieval methods have endowed text-based retrievers with multimodal capabilities by utilizing pre-training strategies for visual-text alignment. They often directly fuse the two modalities for cross-reference during the alignment to understand multimodal queries. However, existing methods often overlook crucial visual information due to a text-dominant issue, which overly depends on text-driven signals. In this paper, we introduce MIRe, a retrieval framework that achieves modality interaction without fusing textual features during the alignment. Our method allows the textual query to attend to visual embeddings while not feeding text-driven signals back into the visual representations. Additionally, we construct a pre-training dataset for multimodal query retrieval by transforming concise question-answer pairs into extended passages. Our experiments demonstrate that our pre-training strategy significantly enhances the understanding of multimodal queries, resulting in strong performance across four multimodal retrieval benchmarks under zero-shot settings. Moreover, our ablation studies and analyses explicitly verify the effectiveness of our framework in mitigating the text-dominant issue. Our code is publicly available: https://github.com/yeongjoonJu/MIRe