CameraHMR: Aligning People with Perspective
作者: Priyanka Patel, Michael J. Black
分类: cs.CV
发布日期: 2024-11-12
备注: 3DV 2025
💡 一句话要点
CameraHMR:通过透视对齐提升单目图像人体姿态和形状估计精度
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction)
关键词: 3D人体姿态估计 3D人体形状估计 单目图像 伪标签生成 相机内参估计
📋 核心要点
- 现有方法依赖简化相机模型和稀疏2D关节,导致伪标签质量不高,限制了3D人体姿态和形状估计的精度。
- 论文提出HumanFoV模型预测相机内参,并利用密集表面关键点检测器优化SMPLify拟合,从而生成更准确的伪标签。
- 通过迭代训练和SMPLify拟合,CameraHMR模型在人体姿态和形状估计方面达到了最先进的精度。
📝 摘要(中文)
本文旨在解决从单目图像中进行精确3D人体姿态和形状估计的挑战。准确性和鲁棒性的关键在于高质量的训练数据。现有的包含真实图像和伪标签(pGT)的训练数据集使用SMPLify将SMPL模型拟合到稀疏的2D关节位置,并假设一个具有默认内参的简化相机模型。本文提出了两点改进,以提高pGT的准确性。首先,为了估计相机内参,我们开发了一个视场预测模型(HumanFoV),该模型在一个包含人物图像的数据集上进行训练。我们使用估计的内参,在SMPLify拟合过程中加入完整的透视相机模型,从而增强了4D-Humans数据集。其次,2D关节对3D身体形状的约束有限,导致身体形状趋于平均。为了解决这个问题,我们使用BEDLAM数据集训练了一个密集的表面关键点检测器。我们将此检测器应用于4D-Humans数据集,并修改SMPLify以拟合检测到的关键点,从而产生更逼真的身体形状。最后,我们升级了HMR2.0架构,以包含估计的相机参数。我们迭代模型训练和SMPLify拟合,并使用先前训练的模型进行初始化。这带来了更准确的pGT和一个新的模型CameraHMR,具有最先进的精度。代码和pGT可用于研究目的。
🔬 方法详解
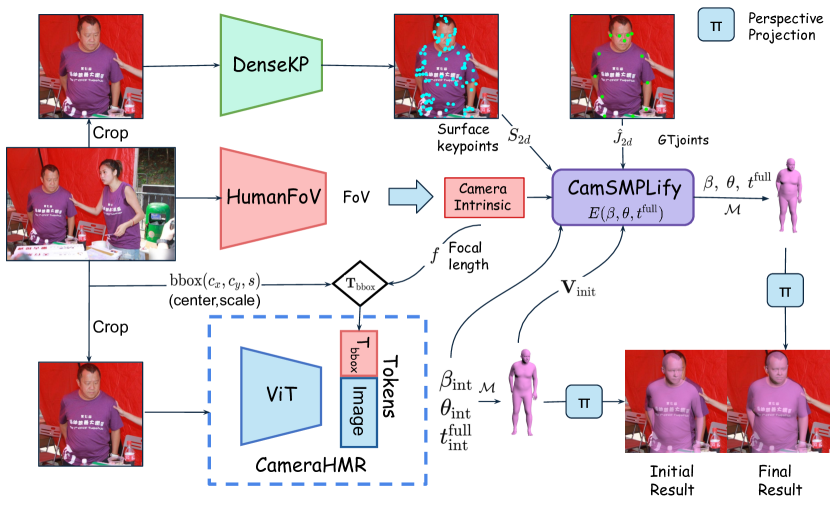
问题定义:论文旨在解决单目图像3D人体姿态和形状估计中,由于训练数据伪标签(pGT)质量不高导致的模型精度瓶颈问题。现有方法通常使用SMPLify拟合SMPL模型到2D关节,但依赖于简化的相机模型和稀疏的2D关节信息,这限制了pGT的准确性,特别是相机内参估计和身体形状的真实性。
核心思路:论文的核心思路是通过更精确的相机内参估计和更丰富的身体形状信息来提升pGT的质量。具体来说,首先训练一个视场预测模型(HumanFoV)来估计相机内参,然后利用该内参改进SMPLify拟合过程。其次,使用密集表面关键点检测器提供更强的身体形状约束,进一步优化SMPLify拟合结果。
技术框架:整体框架包含以下几个主要阶段:1) 使用包含人物图像的数据集训练HumanFoV模型,用于预测相机内参。2) 利用预测的相机内参,修改SMPLify拟合过程,增强4D-Humans数据集。3) 使用BEDLAM数据集训练密集表面关键点检测器。4) 将检测器应用于4D-Humans数据集,并修改SMPLify以拟合检测到的关键点。5) 升级HMR2.0架构,加入估计的相机参数,并进行迭代训练和SMPLify拟合。
关键创新:论文的关键创新在于:1) 提出了HumanFoV模型,用于从图像中直接预测相机内参,从而避免了使用默认内参带来的误差。2) 利用密集表面关键点检测器,为SMPLify拟合提供了更强的身体形状约束,从而生成更真实的身体形状。3) 迭代模型训练和SMPLify拟合,使得模型和pGT能够相互促进,从而达到更高的精度。
关键设计:HumanFoV模型的具体网络结构未知,但其目标是预测相机的视场角,从而推导出相机内参。密集表面关键点检测器的训练使用了BEDLAM数据集,该数据集包含高质量的3D人体扫描数据。SMPLify拟合过程被修改为同时考虑2D关节和密集表面关键点,损失函数可能包含2D关节误差、3D顶点误差和形状正则化项。HMR2.0架构的升级主要体现在输入中加入了估计的相机参数,具体的网络结构修改未知。
🖼️ 关键图片


📊 实验亮点
CameraHMR模型通过引入相机内参估计和密集表面关键点约束,显著提升了3D人体姿态和形状估计的精度。虽然论文中没有给出具体的性能数据,但声明该模型达到了state-of-the-art的精度,表明其性能优于现有的HMR2.0等基线方法。通过迭代训练和SMPLify拟合,模型和pGT能够相互促进,进一步提升了性能。
🎯 应用场景
该研究成果可广泛应用于虚拟现实、增强现实、游戏、动画制作、运动分析、人机交互等领域。更精确的3D人体姿态和形状估计能够提升这些应用的用户体验和功能性,例如,在VR/AR中实现更逼真的人物建模和交互,在运动分析中提供更准确的运动数据。
📄 摘要(原文)
We address the challenge of accurate 3D human pose and shape estimation from monocular images. The key to accuracy and robustness lies in high-quality training data. Existing training datasets containing real images with pseudo ground truth (pGT) use SMPLify to fit SMPL to sparse 2D joint locations, assuming a simplified camera with default intrinsics. We make two contributions that improve pGT accuracy. First, to estimate camera intrinsics, we develop a field-of-view prediction model (HumanFoV) trained on a dataset of images containing people. We use the estimated intrinsics to enhance the 4D-Humans dataset by incorporating a full perspective camera model during SMPLify fitting. Second, 2D joints provide limited constraints on 3D body shape, resulting in average-looking bodies. To address this, we use the BEDLAM dataset to train a dense surface keypoint detector. We apply this detector to the 4D-Humans dataset and modify SMPLify to fit the detected keypoints, resulting in significantly more realistic body shapes. Finally, we upgrade the HMR2.0 architecture to include the estimated camera parameters. We iterate model training and SMPLify fitting initialized with the previously trained model. This leads to more accurate pGT and a new model, CameraHMR, with state-of-the-art accuracy. Code and pGT are available for research purposes.