GaussianAnything: Interactive Point Cloud Flow Matching For 3D Object Generation
作者: Yushi Lan, Shangchen Zhou, Zhaoyang Lyu, Fangzhou Hong, Shuai Yang, Bo Dai, Xingang Pan, Chen Change Loy
分类: cs.CV, cs.AI, cs.GR
发布日期: 2024-11-12 (更新: 2025-04-10)
备注: ICLR 2025 project page: https://nirvanalan.github.io/projects/GA/
💡 一句话要点
GaussianAnything:交互式点云流匹配用于三维物体生成
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 三维物体生成 点云 流匹配 变分自编码器 多模态条件生成
📋 核心要点
- 现有3D内容生成方法在输入格式、潜在空间设计和输出表示上存在挑战,限制了生成质量和交互性。
- GaussianAnything提出了一种基于点云结构化潜在空间的3D生成框架,利用VAE和流模型实现高质量、可交互的3D内容生成。
- 实验结果表明,GaussianAnything在文本和图像条件下的3D生成任务中,性能优于现有方法,并支持3D感知编辑。
📝 摘要(中文)
本文提出了一种新颖的3D生成框架,旨在解决现有方法在输入格式、潜在空间设计和输出表示方面面临的挑战。该框架通过交互式的点云结构化潜在空间,实现了可扩展的、高质量的3D生成。该方法采用变分自编码器(VAE),以多视角、带姿态的RGB-D-N渲染图作为输入,并设计了一种独特的潜在空间,以保留3D形状信息。此外,还引入了级联的基于潜在流的模型,以改进形状和纹理的解耦。所提出的方法GaussianAnything支持多模态条件3D生成,允许使用点云、文本描述和单张图像作为输入。值得注意的是,新提出的潜在空间自然地实现了几何和纹理的解耦,从而支持3D感知的编辑。实验结果表明,该方法在多个数据集上都表现出色,在文本和图像条件下的3D生成方面均优于现有的原生3D方法。
🔬 方法详解
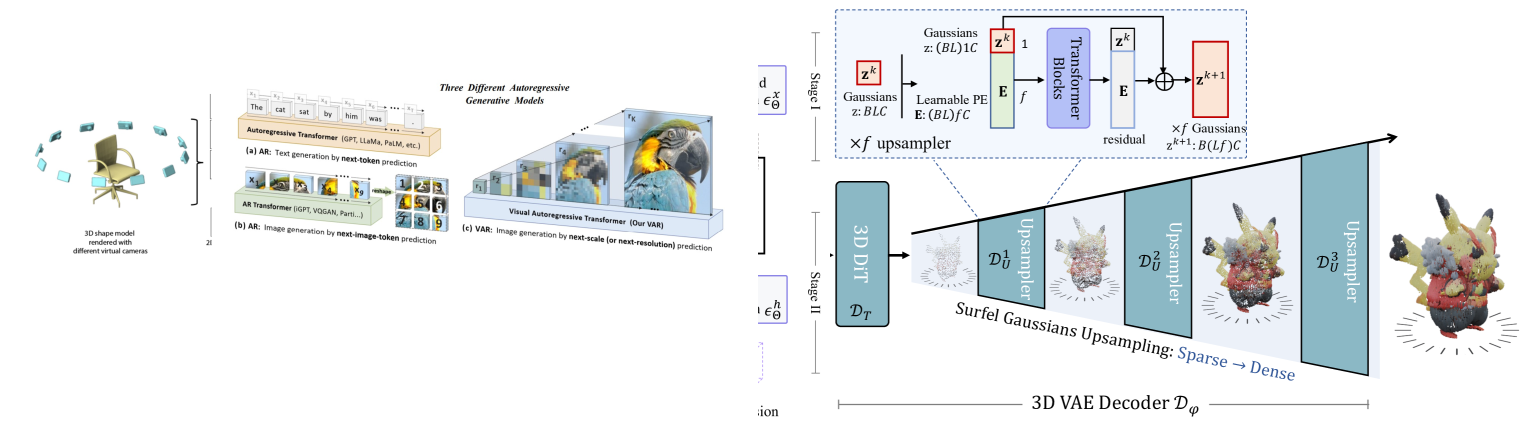
问题定义:现有3D生成方法通常面临输入格式的限制(例如,需要特定格式的3D模型),潜在空间难以解耦形状和纹理,以及输出表示不够灵活等问题。这些问题限制了3D生成的可扩展性、质量和交互性。
核心思路:GaussianAnything的核心思路是构建一个基于点云的结构化潜在空间,该空间能够自然地解耦形状和纹理信息。通过使用变分自编码器(VAE)学习多视角RGB-D-N渲染图的潜在表示,并结合流模型来进一步解耦潜在空间,从而实现高质量、可控的3D生成。
技术框架:GaussianAnything框架主要包含以下几个模块:1) 多视角RGB-D-N渲染模块:用于生成3D对象的不同视角的图像和深度信息。2) 变分自编码器(VAE):用于学习3D对象的潜在表示,将多视角渲染图编码到点云结构的潜在空间中。3) 级联潜在流模型:用于进一步解耦潜在空间中的形状和纹理信息,提高生成质量和可控性。4) 3D生成模块:基于潜在空间中的表示,生成最终的3D对象。
关键创新:GaussianAnything的关键创新在于其独特的点云结构化潜在空间设计,该设计能够自然地解耦形状和纹理信息,从而支持3D感知的编辑。此外,使用级联潜在流模型进一步提高了形状和纹理的解耦效果,使得生成结果更加逼真和可控。
关键设计:GaussianAnything使用VAE学习潜在表示,并采用多视角RGB-D-N渲染图作为输入,以提供更丰富的3D信息。级联潜在流模型采用多个连续的流变换,逐步解耦潜在空间中的形状和纹理信息。损失函数包括重构损失、KL散度和对抗损失,以保证生成结果的质量和多样性。具体的网络结构和参数设置在论文中有详细描述。
🖼️ 关键图片


📊 实验亮点
实验结果表明,GaussianAnything在多个数据集上都取得了优异的性能,在文本和图像条件下的3D生成任务中均优于现有的原生3D方法。该方法能够生成高质量、逼真的3D模型,并支持3D感知的编辑,例如改变物体的形状、纹理和姿态。具体的性能数据和对比结果在论文中有详细展示。
🎯 应用场景
GaussianAnything具有广泛的应用前景,包括游戏开发、虚拟现实、增强现实、3D内容创作等领域。它可以用于快速生成高质量的3D模型,并支持用户进行交互式编辑和定制。该研究的成果有助于降低3D内容创作的门槛,促进3D技术的普及和应用。
📄 摘要(原文)
While 3D content generation has advanced significantly, existing methods still face challenges with input formats, latent space design, and output representations. This paper introduces a novel 3D generation framework that addresses these challenges, offering scalable, high-quality 3D generation with an interactive Point Cloud-structured Latent space. Our framework employs a Variational Autoencoder (VAE) with multi-view posed RGB-D(epth)-N(ormal) renderings as input, using a unique latent space design that preserves 3D shape information, and incorporates a cascaded latent flow-based model for improved shape-texture disentanglement. The proposed method, GaussianAnything, supports multi-modal conditional 3D generation, allowing for point cloud, caption, and single image inputs. Notably, the newly proposed latent space naturally enables geometry-texture disentanglement, thus allowing 3D-aware editing. Experimental results demonstrate the effectiveness of our approach on multiple datasets, outperforming existing native 3D methods in both text- and image-conditioned 3D generation.