ALOcc: Adaptive Lifting-Based 3D Semantic Occupancy and Cost Volume-Based Flow Predictions
作者: Dubing Chen, Jin Fang, Wencheng Han, Xinjing Cheng, Junbo Yin, Chenzhong Xu, Fahad Shahbaz Khan, Jianbing Shen
分类: cs.CV
发布日期: 2024-11-12 (更新: 2025-09-10)
备注: ICCV 2025
💡 一句话要点
提出基于自适应提升的3D语义占据和基于代价体的光流预测方法
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱八:物理动画 (Physics-based Animation)
关键词: 3D语义占据 光流预测 自适应提升 代价体 时空场景理解
📋 核心要点
- 现有方法在2D到3D特征转换时鲁棒性不足,且依赖深度先验,限制了其在复杂场景下的性能。
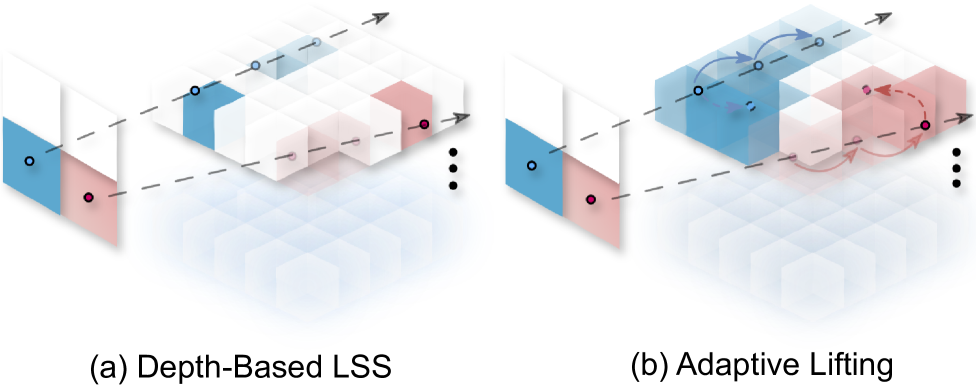
- 提出一种自适应提升机制,结合深度去噪,增强特征转换的鲁棒性,并减轻对深度先验的依赖。
- 该方法在多个基准测试中取得了SOTA性能,并且实时版本在速度和准确性上超过了现有实时方法。
📝 摘要(中文)
本文提出了一种基于视觉的框架,用于3D语义占据和光流预测,旨在提升时空场景理解能力。该框架包含三个关键改进:首先,引入了结合深度去噪的、具有遮挡感知能力的自适应提升机制,增强了2D到3D特征转换的鲁棒性,并减轻了对深度先验的依赖。其次,通过联合优化的原型强制执行3D-2D语义一致性,并使用置信度和类别感知的采样来解决长尾类问题。第三,为了简化联合预测,设计了一个以BEV为中心的代价体,以显式地关联语义和光流特征,并采用混合分类-回归方案进行监督,以处理不同的运动尺度。该纯卷积架构在语义占据和联合占据语义-光流预测的多个基准测试中建立了新的SOTA性能。此外,还提供了一系列模型,以提供效率-性能的权衡。实时版本在速度和准确性方面均超过了所有现有的实时方法,确保了其在实际应用中的可行性。
🔬 方法详解
问题定义:现有方法在3D语义占据和光流预测任务中,存在2D到3D特征转换鲁棒性不足、依赖深度先验、以及难以有效处理长尾类问题等痛点。此外,如何高效地进行语义和光流的联合预测也是一个挑战。
核心思路:本文的核心思路是通过引入自适应提升机制增强特征转换的鲁棒性,利用3D-2D语义一致性约束解决长尾类问题,并设计BEV视角的代价体来显式关联语义和光流特征,从而实现高效的联合预测。这样设计的目的是为了克服现有方法的不足,提升整体性能。
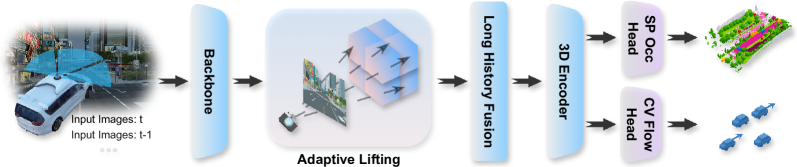
技术框架:该框架主要包含三个模块:1) 遮挡感知自适应提升模块,用于将2D特征转换为3D特征;2) 3D-2D语义一致性模块,通过联合优化的原型和置信度/类别感知的采样来解决长尾类问题;3) BEV视角的代价体构建模块,用于关联语义和光流特征,并进行联合预测。整体流程是从2D图像提取特征,经过自适应提升得到3D特征,然后利用语义一致性约束和代价体进行语义和光流的联合预测。
关键创新:最重要的技术创新点在于:1) 提出了遮挡感知的自适应提升机制,有效提升了2D到3D特征转换的鲁棒性,并减轻了对深度先验的依赖;2) 提出了基于BEV视角的代价体,能够显式地关联语义和光流特征,从而实现高效的联合预测。与现有方法相比,该方法在特征转换、语义一致性和联合预测方面都有显著改进。
关键设计:在自适应提升模块中,使用了深度去噪技术来提高深度信息的质量。在语义一致性模块中,使用了置信度和类别感知的采样策略来缓解长尾类问题。在代价体构建模块中,使用了混合分类-回归损失函数来监督语义和光流的预测,以处理不同的运动尺度。网络结构主要采用纯卷积架构,以提高计算效率。
🖼️ 关键图片

📊 实验亮点
该方法在多个基准测试中取得了SOTA性能,例如在nuScenes数据集上,语义占据预测的性能显著优于现有方法。此外,该方法的实时版本在速度和准确性方面均超过了所有现有的实时方法,使其具有实际应用价值。具体性能数据需要在论文中查找。
🎯 应用场景
该研究成果可应用于自动驾驶、机器人导航、增强现实等领域。通过准确地预测3D语义占据和光流信息,可以帮助自动驾驶系统更好地理解周围环境,从而做出更安全、更合理的决策。在机器人导航中,可以帮助机器人更好地感知环境,规划路径。在增强现实中,可以实现更逼真的虚拟场景与真实世界的融合。
📄 摘要(原文)
3D semantic occupancy and flow prediction are fundamental to spatiotemporal scene understanding. This paper proposes a vision-based framework with three targeted improvements. First, we introduce an occlusion-aware adaptive lifting mechanism incorporating depth denoising. This enhances the robustness of 2D-to-3D feature transformation while mitigating reliance on depth priors. Second, we enforce 3D-2D semantic consistency via jointly optimized prototypes, using confidence- and category-aware sampling to address the long-tail classes problem. Third, to streamline joint prediction, we devise a BEV-centric cost volume to explicitly correlate semantic and flow features, supervised by a hybrid classification-regression scheme that handles diverse motion scales. Our purely convolutional architecture establishes new SOTA performance on multiple benchmarks for both semantic occupancy and joint occupancy semantic-flow prediction. We also present a family of models offering a spectrum of efficiency-performance trade-offs. Our real-time version exceeds all existing real-time methods in speed and accuracy, ensuring its practical viability.