BLIP3-KALE: Knowledge Augmented Large-Scale Dense Captions
作者: Anas Awadalla, Le Xue, Manli Shu, An Yan, Jun Wang, Senthil Purushwalkam, Sheng Shen, Hannah Lee, Oscar Lo, Jae Sung Park, Etash Guha, Silvio Savarese, Ludwig Schmidt, Yejin Choi, Caiming Xiong, Ran Xu
分类: cs.CV, cs.AI
发布日期: 2024-11-12
🔗 代码/项目: HUGGINGFACE
💡 一句话要点
BLIP3-KALE:提出知识增强的大规模密集图像描述数据集,提升视觉语言模型性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 图像描述 知识增强 多模态学习 数据集构建
📋 核心要点
- 现有图像描述数据集在事实性知识方面存在不足,限制了视觉语言模型在需要知识推理任务上的表现。
- BLIP3-KALE通过融合合成密集描述和网络规模alt-text,生成知识增强的图像描述,提升模型的事实性。
- 实验表明,在BLIP3-KALE上训练的视觉语言模型在多个视觉语言任务上取得了显著的性能提升。
📝 摘要(中文)
本文介绍了BLIP3-KALE,一个包含2.18亿图像-文本对的数据集,旨在弥合描述性合成字幕和事实性网络规模alt-text之间的差距。KALE通过网络规模的alt-text增强合成密集图像字幕,从而生成基于事实的图像描述。该方法采用两阶段策略,利用大型视觉语言模型和语言模型创建知识增强的字幕,然后使用这些字幕训练专门的VLM以扩大数据集规模。在KALE上训练的视觉语言模型在视觉语言任务上表现出性能提升。实验结果表明,KALE对于训练更强大和更具知识性的多模态模型具有重要价值。KALE数据集已在https://huggingface.co/datasets/Salesforce/blip3-kale上发布。
🔬 方法详解
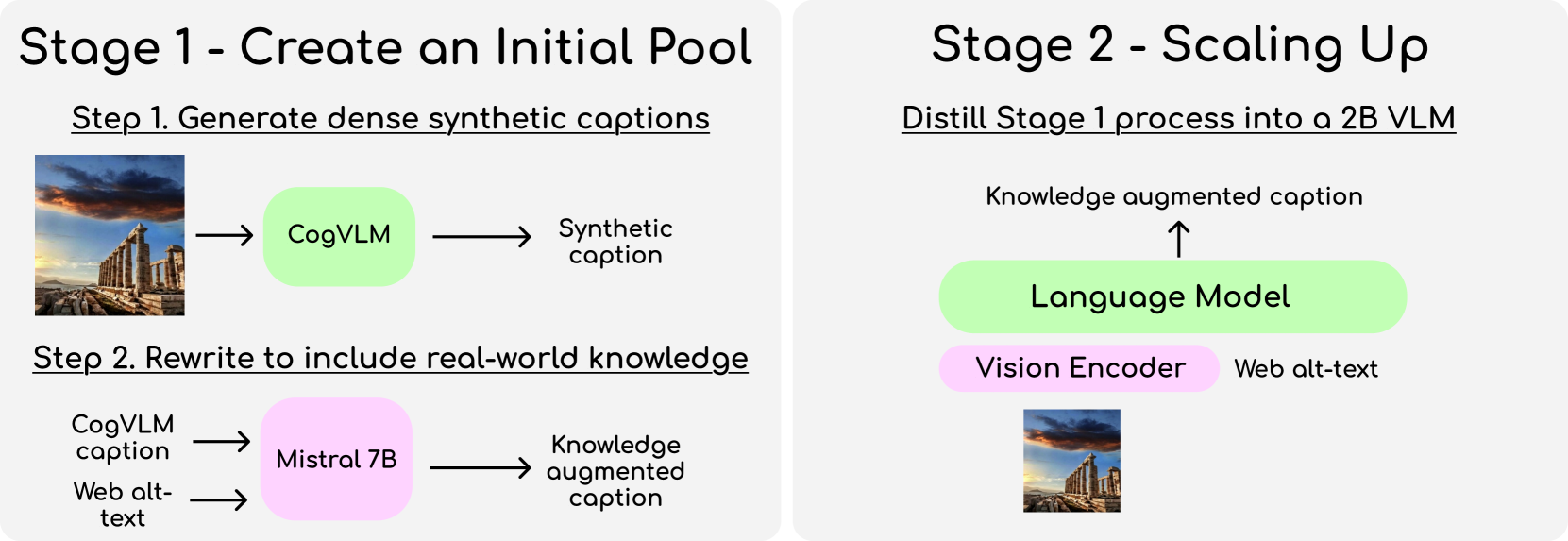
问题定义:现有的图像描述数据集,例如合成数据集,通常缺乏真实世界的事实性知识。而网络规模的alt-text虽然包含大量信息,但描述性较弱。因此,如何构建一个既具有丰富描述性又包含事实性知识的大规模图像描述数据集是一个挑战。
核心思路:BLIP3-KALE的核心思路是利用合成密集图像描述的详细性和网络规模alt-text的事实性,通过知识增强的方式将两者结合起来。具体来说,首先生成高质量的合成描述,然后利用大型语言模型从网络alt-text中提取相关的事实性知识,并将这些知识融入到合成描述中。
技术框架:BLIP3-KALE的构建分为两个阶段。第一阶段是知识增强阶段,利用大型视觉语言模型和语言模型,将网络规模的alt-text中的知识融入到合成密集图像描述中,生成知识增强的字幕。第二阶段是数据集扩展阶段,使用第一阶段生成的知识增强字幕训练一个专门的视觉语言模型,然后利用该模型生成更大规模的KALE数据集。
关键创新:BLIP3-KALE的关键创新在于其知识增强策略,它有效地结合了合成描述的详细性和网络alt-text的事实性。通过利用大型语言模型,能够从海量的alt-text中提取出与图像相关的知识,并将其融入到图像描述中,从而提升了数据集的质量和信息量。
关键设计:在知识增强阶段,论文可能使用了特定的prompt工程技术来指导大型语言模型生成更准确和相关的知识描述。此外,在训练专门的视觉语言模型时,可能采用了特定的损失函数或训练策略,以更好地利用KALE数据集的特性。具体的技术细节可能需要参考论文原文。
🖼️ 关键图片


📊 实验亮点
在BLIP3-KALE数据集上训练的视觉语言模型在多个视觉语言任务上取得了显著的性能提升。具体的性能数据和对比基线需要在论文原文中查找。总体而言,实验结果表明,KALE数据集对于提升视觉语言模型的知识性和泛化能力具有重要作用。
🎯 应用场景
BLIP3-KALE数据集可用于训练更强大、更具知识性的多模态模型,这些模型可以应用于图像搜索、视觉问答、图像编辑、机器人导航等领域。通过提升模型对图像内容的理解能力和知识推理能力,可以实现更智能、更人性化的应用。
📄 摘要(原文)
We introduce BLIP3-KALE, a dataset of 218 million image-text pairs that bridges the gap between descriptive synthetic captions and factual web-scale alt-text. KALE augments synthetic dense image captions with web-scale alt-text to generate factually grounded image captions. Our two-stage approach leverages large vision-language models and language models to create knowledge-augmented captions, which are then used to train a specialized VLM for scaling up the dataset. We train vision-language models on KALE and demonstrate improvements on vision-language tasks. Our experiments show the utility of KALE for training more capable and knowledgeable multimodal models. We release the KALE dataset at https://huggingface.co/datasets/Salesforce/blip3-kale