XPoint: A Self-Supervised Visual-State-Space based Architecture for Multispectral Image Registration
作者: Ismail Can Yagmur, Hasan F. Ates, Bahadir K. Gunturk
分类: cs.CV
发布日期: 2024-11-11
备注: 13 pages, 11 figures, 1 table, Journal
🔗 代码/项目: GITHUB
💡 一句话要点
XPoint:一种基于自监督视觉状态空间的多光谱图像配准架构
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱六:视频提取与匹配 (Video Extraction)
关键词: 多光谱图像配准 自监督学习 视觉状态空间 VMamba 特征匹配 模块化设计 跨模态学习
📋 核心要点
- 现有方法在多光谱图像配准中,难以应对非线性强度变化和视角差异,且依赖昂贵的监督信息,泛化性差。
- XPoint采用自监督和模块化设计,通过可调整的检测器生成伪标签,并利用预训练的VMamba编码器提取鲁棒特征。
- 实验表明,XPoint在多种多光谱数据集上,特征匹配和图像配准性能优于或媲美现有最佳方法。
📝 摘要(中文)
由于跨光谱模态的非线性强度变化、极端的视角变化以及标记数据集的稀缺性,精确的多光谱图像匹配面临着重大挑战。目前最先进的方法通常专门针对单一光谱差异(如可见光-红外),并且由于依赖昂贵的监督(如深度图或相机姿态)而难以适应其他模态。为了满足跨模态快速适应的需求,我们引入了XPoint,这是一个自监督、模块化的图像匹配框架,专为对齐的多光谱数据集上的自适应训练和微调而设计,允许用户根据其特定任务自定义关键组件。XPoint采用模块化和自监督来调整诸如基础检测器之类的元素,该检测器生成对视角和光谱变化不变的伪地面真值关键点。该框架集成了在分割任务上预训练的VMamba编码器,用于鲁棒的特征提取,并包括三个联合解码器头:两个专用于兴趣点和描述符提取;以及一个特定于任务的单应性回归头,用于施加几何约束,从而在图像配准等任务中实现卓越的性能。这种灵活的架构能够快速适应各种模态,通过在光学-热数据上进行训练并在诸如可见光-近红外、可见光-红外、可见光-长波红外和可见光-合成孔径雷达等设置上进行微调来证明。实验结果表明,XPoint在五个不同的多光谱数据集上的特征匹配和图像配准任务中始终优于或匹配最先进的方法。我们的源代码可在https://github.com/canyagmur/XPoint获得。
🔬 方法详解
问题定义:多光谱图像配准旨在对齐来自不同光谱模态的图像,由于各模态间存在非线性强度差异、视角变化以及缺乏标注数据,现有方法难以有效匹配。现有方法通常针对特定模态设计,依赖深度图或相机位姿等昂贵的监督信息,泛化能力较弱。
核心思路:XPoint的核心在于利用自监督学习和模块化设计,实现跨模态的快速适应。通过自监督的方式生成伪标签,避免对昂贵标注的依赖。模块化设计允许针对特定任务定制关键组件,提高灵活性和适应性。
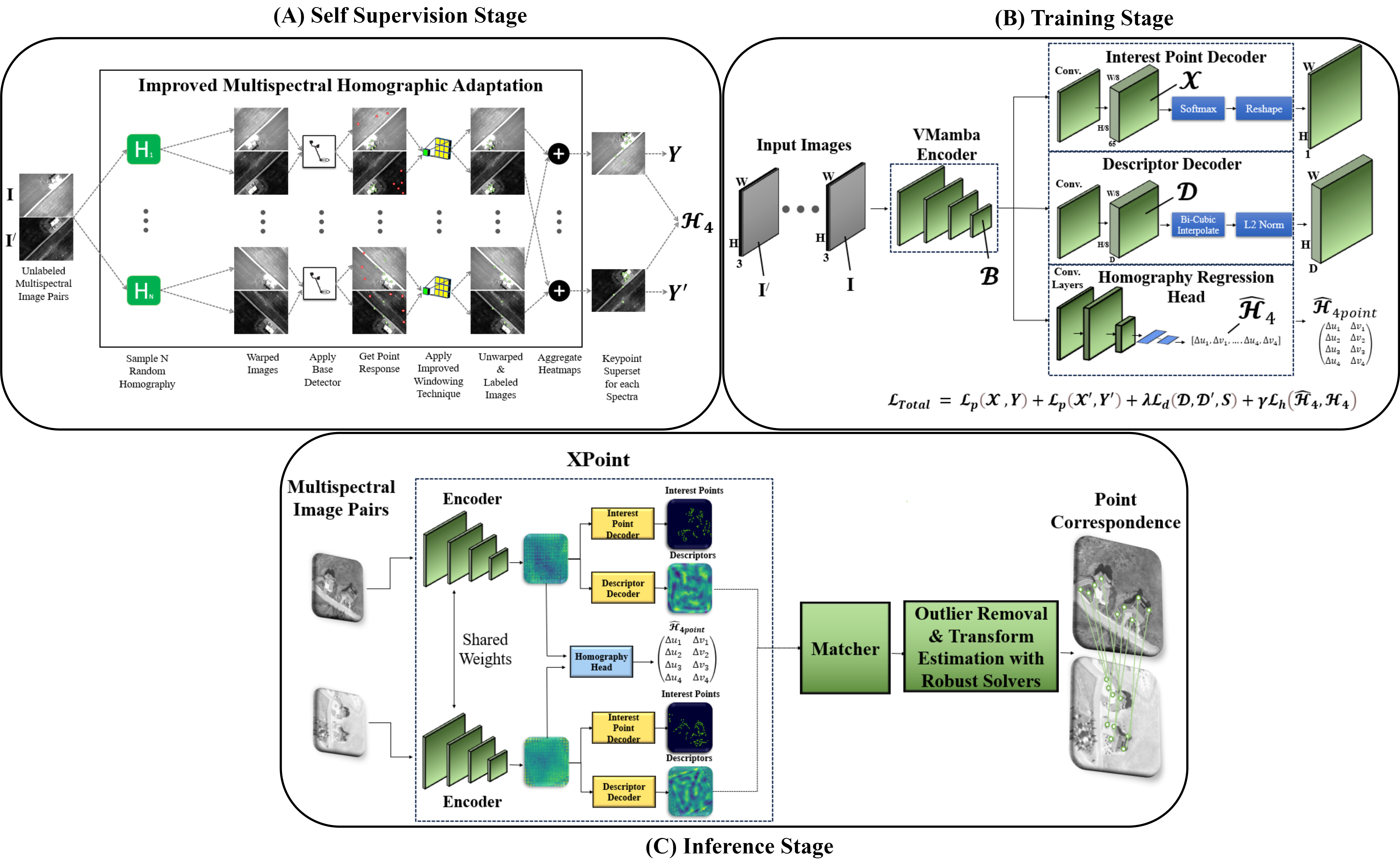
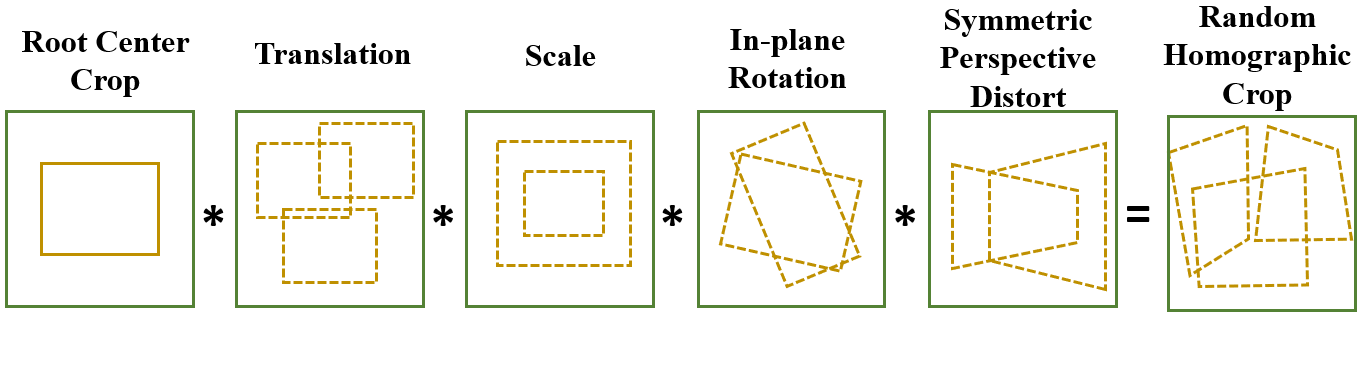
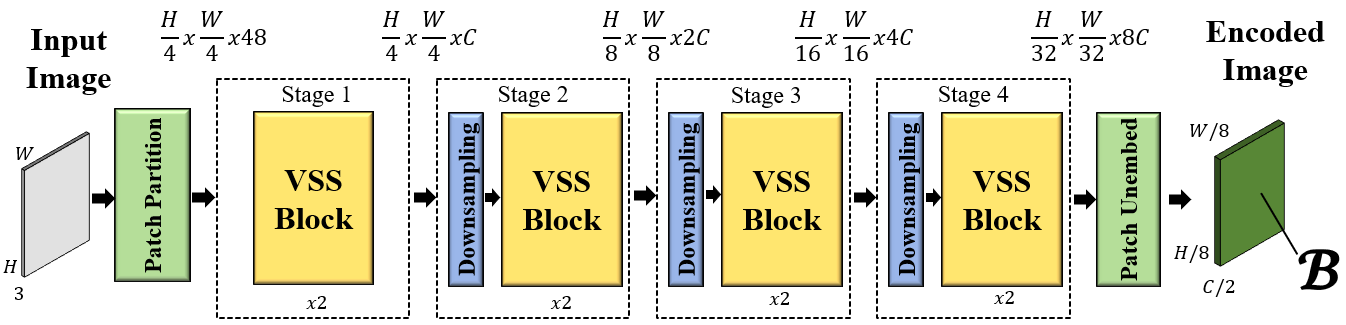
技术框架:XPoint框架包含以下主要模块:1) 基础检测器:生成对视角和光谱变化具有不变性的伪地面真值关键点。2) VMamba编码器:利用在分割任务上预训练的VMamba编码器提取鲁棒的特征表示。3) 联合解码器:包含兴趣点提取头、描述符提取头和单应性回归头,其中单应性回归头用于施加几何约束。整个流程通过自监督的方式进行训练和微调。
关键创新:XPoint的关键创新在于其自监督的训练方式和模块化的架构设计。自监督训练避免了对昂贵标注数据的依赖,提高了模型的泛化能力。模块化设计允许用户根据特定任务定制关键组件,提高了模型的灵活性和适应性。VMamba编码器的使用也提升了特征提取的鲁棒性。
关键设计:基础检测器采用自监督的方式生成伪标签,具体实现细节未知。VMamba编码器使用在分割任务上预训练的模型,以提高特征提取的鲁棒性。联合解码器包含三个头,分别用于兴趣点提取、描述符提取和单应性回归。损失函数的设计未知,但可能包含用于约束兴趣点、描述符和单应性矩阵的损失项。
🖼️ 关键图片
📊 实验亮点
XPoint在五个不同的多光谱数据集上进行了实验,包括光学-热数据、可见光-近红外、可见光-红外、可见光-长波红外和可见光-合成孔径雷达。实验结果表明,XPoint在特征匹配和图像配准任务中始终优于或匹配最先进的方法,证明了其在跨模态图像配准方面的有效性和泛化能力。具体性能提升数据未知。
🎯 应用场景
XPoint在遥感图像配准、医学图像配准、自动驾驶等多光谱图像处理领域具有广泛的应用前景。该方法能够有效解决跨模态图像配准难题,提高配准精度和效率,为相关领域的智能化应用提供技术支撑。未来,XPoint有望应用于更复杂的场景,例如三维重建、目标检测等。
📄 摘要(原文)
Accurate multispectral image matching presents significant challenges due to non-linear intensity variations across spectral modalities, extreme viewpoint changes, and the scarcity of labeled datasets. Current state-of-the-art methods are typically specialized for a single spectral difference, such as visibleinfrared, and struggle to adapt to other modalities due to their reliance on expensive supervision, such as depth maps or camera poses. To address the need for rapid adaptation across modalities, we introduce XPoint, a self-supervised, modular image-matching framework designed for adaptive training and fine-tuning on aligned multispectral datasets, allowing users to customize key components based on their specific tasks. XPoint employs modularity and self-supervision to allow for the adjustment of elements such as the base detector, which generates pseudoground truth keypoints invariant to viewpoint and spectrum variations. The framework integrates a VMamba encoder, pretrained on segmentation tasks, for robust feature extraction, and includes three joint decoder heads: two are dedicated to interest point and descriptor extraction; and a task-specific homography regression head imposes geometric constraints for superior performance in tasks like image registration. This flexible architecture enables quick adaptation to a wide range of modalities, demonstrated by training on Optical-Thermal data and fine-tuning on settings such as visual-near infrared, visual-infrared, visual-longwave infrared, and visual-synthetic aperture radar. Experimental results show that XPoint consistently outperforms or matches state-ofthe-art methods in feature matching and image registration tasks across five distinct multispectral datasets. Our source code is available at https://github.com/canyagmur/XPoint.