OmniEdit: Building Image Editing Generalist Models Through Specialist Supervision
作者: Cong Wei, Zheyang Xiong, Weiming Ren, Xinrun Du, Ge Zhang, Wenhu Chen
分类: cs.CV, cs.AI
发布日期: 2024-11-11 (更新: 2025-04-28)
备注: 21 pages
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
OmniEdit:通过专家监督构建通用图像编辑模型,实现任意宽高比的七种编辑任务。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图像编辑 扩散模型 多任务学习 专家监督 数据质量 任意宽高比 GPT-4o
📋 核心要点
- 现有图像编辑模型受限于有偏的数据合成、高噪声数据和固定的图像宽高比,导致其在实际应用中表现不佳。
- OmniEdit通过利用多个专家模型的监督、基于GPT-4o评分的重要性采样和新的EditNet架构,提升了编辑能力和数据质量。
- 实验证明,OmniEdit在不同宽高比的图像上,针对多种编辑任务,显著优于现有模型,展现了其通用性。
📝 摘要(中文)
本文提出OmniEdit,一个能够无缝处理任意宽高比图像并执行七种不同图像编辑任务的通用编辑器。现有指令引导的图像编辑方法虽然展示了潜力,但由于合成过程的偏差导致编辑技能有限,数据集噪声大,以及仅限于单一低分辨率和固定宽高比,距离实际应用仍有差距。OmniEdit的贡献包括:利用七个不同专家模型的监督来确保任务覆盖;使用基于大型多模态模型(如GPT-4o)的评分进行重要性采样,以提高数据质量;提出一种名为EditNet的新编辑架构,以显著提高编辑成功率;以及提供不同宽高比的图像,以确保模型可以处理任何实际图像。实验结果表明,OmniEdit显著优于所有现有模型。
🔬 方法详解
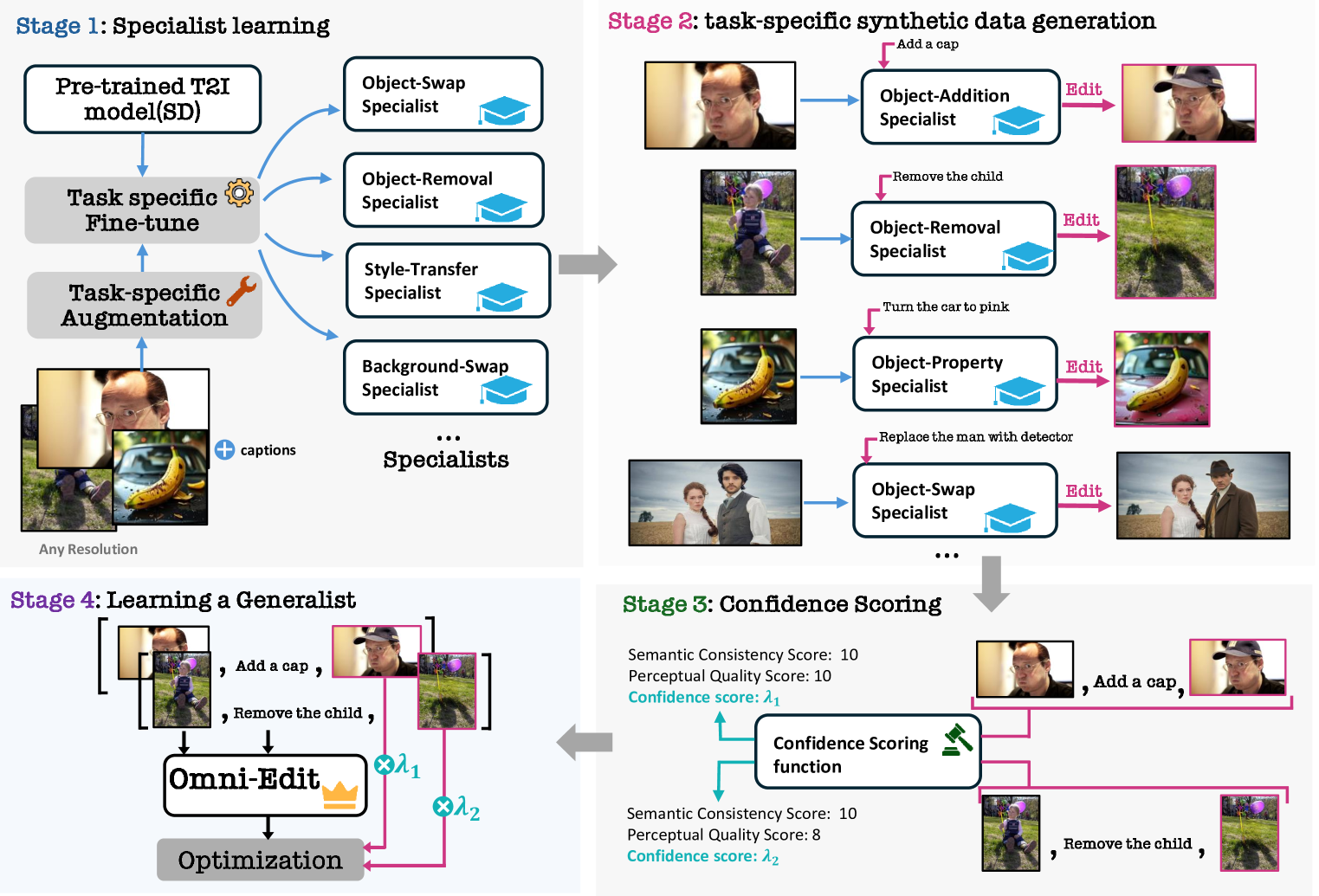
问题定义:现有指令引导的图像编辑方法在实际应用中面临三个主要问题:一是由于数据合成过程的偏差,模型的编辑技能有限;二是训练数据集中存在大量噪声和伪影,这是由于使用了简单的过滤方法(如CLIP-score);三是所有数据集都限制为单一低分辨率和固定宽高比,限制了模型处理实际用例的通用性。
核心思路:OmniEdit的核心思路是通过利用多个专家模型的监督来提升模型的编辑能力,使用大型多模态模型(如GPT-4o)进行更有效的数据过滤,并设计新的编辑架构来提高编辑成功率。同时,通过使用不同宽高比的图像进行训练,增强模型的通用性。
技术框架:OmniEdit的整体框架包括数据收集与清洗、模型训练和评估三个主要阶段。数据收集阶段利用七个不同的专家模型生成编辑指令和对应的图像对。数据清洗阶段使用基于GPT-4o评分的重要性采样来过滤低质量数据。模型训练阶段使用EditNet架构,并结合专家模型的监督信号进行训练。评估阶段使用包含不同宽高比图像和多样化指令的测试集进行评估。
关键创新:OmniEdit的关键创新在于以下几点:1) 利用多个专家模型的监督,确保模型覆盖多种编辑任务;2) 使用基于GPT-4o评分的重要性采样,提高数据质量;3) 提出EditNet架构,显著提高编辑成功率;4) 支持任意宽高比的图像编辑。与现有方法相比,OmniEdit更注重模型的通用性和实际应用能力。
关键设计:EditNet架构的具体细节未知,论文中提到使用了基于GPT-4o的评分进行重要性采样,但具体采样策略和阈值未知。损失函数的设计可能结合了多个专家模型的输出,以实现多任务学习。图像宽高比的处理方式也未详细说明,可能使用了某种图像缩放或填充策略。
🖼️ 关键图片


📊 实验亮点
OmniEdit在包含不同宽高比图像和多样化指令的测试集上进行了评估,实验结果表明,OmniEdit显著优于所有现有模型。具体的性能数据和提升幅度在论文中未明确给出,但强调了在自动评估和人工评估中均取得了显著的提升。
🎯 应用场景
OmniEdit具有广泛的应用前景,可用于图像修复、风格迁移、对象替换、属性编辑等多种图像编辑任务。该模型可以应用于电商、社交媒体、游戏开发等领域,帮助用户快速便捷地编辑图像,提升用户体验和生产效率。未来,OmniEdit有望成为图像编辑领域的通用解决方案。
📄 摘要(原文)
Instruction-guided image editing methods have demonstrated significant potential by training diffusion models on automatically synthesized or manually annotated image editing pairs. However, these methods remain far from practical, real-life applications. We identify three primary challenges contributing to this gap. Firstly, existing models have limited editing skills due to the biased synthesis process. Secondly, these methods are trained with datasets with a high volume of noise and artifacts. This is due to the application of simple filtering methods like CLIP-score. Thirdly, all these datasets are restricted to a single low resolution and fixed aspect ratio, limiting the versatility to handle real-world use cases. In this paper, we present \omniedit, which is an omnipotent editor to handle seven different image editing tasks with any aspect ratio seamlessly. Our contribution is in four folds: (1) \omniedit is trained by utilizing the supervision from seven different specialist models to ensure task coverage. (2) we utilize importance sampling based on the scores provided by large multimodal models (like GPT-4o) instead of CLIP-score to improve the data quality. (3) we propose a new editing architecture called EditNet to greatly boost the editing success rate, (4) we provide images with different aspect ratios to ensure that our model can handle any image in the wild. We have curated a test set containing images of different aspect ratios, accompanied by diverse instructions to cover different tasks. Both automatic evaluation and human evaluations demonstrate that \omniedit can significantly outperform all the existing models. Our code, dataset and model will be available at https://tiger-ai-lab.github.io/OmniEdit/