ConvMixFormer- A Resource-efficient Convolution Mixer for Transformer-based Dynamic Hand Gesture Recognition
作者: Mallika Garg, Debashis Ghosh, Pyari Mohan Pradhan
分类: cs.CV, cs.HC, cs.LG
发布日期: 2024-11-11 (更新: 2024-12-02)
期刊: WACV 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出ConvMixFormer,一种资源高效的卷积混合Transformer,用于动态手势识别。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 动态手势识别 Transformer 卷积神经网络 资源效率 深度学习
📋 核心要点
- Transformer模型在手势识别中应用面临计算复杂度高和参数量大的挑战,尤其是在处理序列数据时。
- ConvMixFormer通过卷积层token mixer替代自注意力机制,并采用高效门控机制,降低计算成本和参数量。
- 在NVidia动态手势和Briareo数据集上,ConvMixFormer在单模和多模输入上均取得了state-of-the-art的结果,并展示了参数效率。
📝 摘要(中文)
Transformer模型在自然语言处理(NLP)和计算机视觉等多个领域取得了显著成功。随着对基于Transformer架构的兴趣日益增长,它们现在也被用于手势识别。因此,我们也探索并设计了一种新颖的ConvMixFormer架构用于动态手势识别。由于Transformer在处理序列数据时,注意力特征的计算复杂度呈二次方增长,导致这些模型计算量大且笨重。我们考虑了Transformer的这一缺点,并设计了一种资源高效的模型,该模型用基于卷积层的token mixer取代了Transformer中的自注意力机制。基于卷积的mixer的计算成本和参数使用量明显低于二次自注意力。卷积mixer有助于模型捕获自注意力因其顺序处理特性而难以捕获的局部空间特征。此外,该模型采用了一种高效的门控机制,而不是Transformer中传统的feed-forward网络,以帮助模型控制所提出的模型不同阶段内的特征流动。这种设计使用更少的学习参数,几乎是原始Transformer的一半,有助于快速高效的训练。所提出的方法在NVidia动态手势和Briareo数据集上进行了评估,我们的模型在单模和多模输入上都取得了最先进的结果。我们还展示了所提出的ConvMixFormer模型与其他方法相比的参数效率。源代码可在https://github.com/mallikagarg/ConvMixFormer 获取。
🔬 方法详解
问题定义:论文旨在解决动态手势识别中Transformer模型计算复杂度高、参数量大的问题。现有Transformer模型在处理序列数据时,自注意力机制的计算复杂度呈二次方增长,导致模型训练和部署成本较高,难以在资源受限的设备上应用。
核心思路:论文的核心思路是利用卷积操作来替代Transformer中的自注意力机制,从而降低计算复杂度和参数量。卷积操作能够有效地提取局部空间特征,并且计算成本远低于自注意力机制。此外,论文还引入了一种高效的门控机制来控制特征流动,进一步减少了参数量。
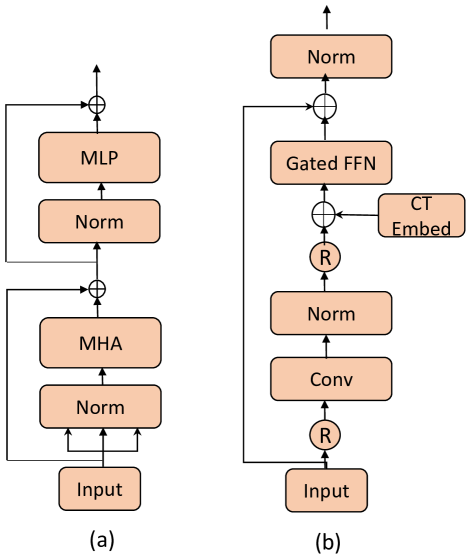
技术框架:ConvMixFormer的整体架构基于Transformer,但关键区别在于使用卷积混合器(Convolution Mixer)替换了传统的自注意力模块。模型首先将输入数据进行token化,然后通过一系列的ConvMixFormer块进行处理。每个ConvMixFormer块包含一个卷积混合器和一个门控机制。卷积混合器负责提取局部空间特征,门控机制负责控制特征的流动。最后,模型输出预测结果。
关键创新:ConvMixFormer的关键创新在于使用卷积混合器替代了自注意力机制。与自注意力机制相比,卷积混合器具有更低的计算复杂度和参数量,同时能够有效地提取局部空间特征。此外,论文提出的高效门控机制也进一步减少了参数量,提高了模型的效率。
关键设计:卷积混合器使用深度可分离卷积(Depthwise Separable Convolution)来降低计算成本。门控机制采用Sigmoid激活函数来控制特征的流动。模型的损失函数为交叉熵损失函数。具体的网络结构和参数设置可以在论文提供的源代码中找到。
🖼️ 关键图片

📊 实验亮点
ConvMixFormer在NVidia动态手势和Briareo数据集上取得了state-of-the-art的结果。在NVidia动态手势数据集上,ConvMixFormer在单模输入和多模输入上均优于现有的方法。此外,ConvMixFormer的参数量仅为原始Transformer的一半,表明其具有更高的参数效率。实验结果表明,ConvMixFormer是一种资源高效且性能优异的动态手势识别模型。
🎯 应用场景
ConvMixFormer在动态手势识别领域具有广泛的应用前景,例如人机交互、虚拟现实、智能家居等。该模型可以用于识别用户的手势指令,从而实现对设备的控制和操作。由于其资源效率高,ConvMixFormer尤其适用于移动设备和嵌入式系统等资源受限的平台。未来的研究可以探索将ConvMixFormer应用于其他序列数据处理任务,例如语音识别和自然语言处理。
📄 摘要(原文)
Transformer models have demonstrated remarkable success in many domains such as natural language processing (NLP) and computer vision. With the growing interest in transformer-based architectures, they are now utilized for gesture recognition. So, we also explore and devise a novel ConvMixFormer architecture for dynamic hand gestures. The transformers use quadratic scaling of the attention features with the sequential data, due to which these models are computationally complex and heavy. We have considered this drawback of the transformer and designed a resource-efficient model that replaces the self-attention in the transformer with the simple convolutional layer-based token mixer. The computational cost and the parameters used for the convolution-based mixer are comparatively less than the quadratic self-attention. Convolution-mixer helps the model capture the local spatial features that self-attention struggles to capture due to their sequential processing nature. Further, an efficient gate mechanism is employed instead of a conventional feed-forward network in the transformer to help the model control the flow of features within different stages of the proposed model. This design uses fewer learnable parameters which is nearly half the vanilla transformer that helps in fast and efficient training. The proposed method is evaluated on NVidia Dynamic Hand Gesture and Briareo datasets and our model has achieved state-of-the-art results on single and multimodal inputs. We have also shown the parameter efficiency of the proposed ConvMixFormer model compared to other methods. The source code is available at https://github.com/mallikagarg/ConvMixFormer.