Track Any Peppers: Weakly Supervised Sweet Pepper Tracking Using VLMs
作者: Jia Syuen Lim, Yadan Luo, Zhi Chen, Tianqi Wei, Scott Chapman, Zi Huang
分类: cs.CV
发布日期: 2024-11-11
💡 一句话要点
Track Any Peppers:利用VLM弱监督实现甜椒精准追踪
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 甜椒追踪 弱监督学习 视觉语言模型 零样本检测 目标追踪 YOLOv8 智慧农业
📋 核心要点
- 现有甜椒追踪方法依赖大量人工标注,成本高昂且难以适应不同环境下的变化。
- TAP利用VLM的零样本检测能力自动生成伪标签,结合YOLOv8分割网络和MASA-BoT-SORT追踪框架,实现弱监督学习。
- 实验表明,TAP在甜椒追踪任务中取得了显著的性能,HOTA达到80.4%,证明了其有效性和实用性。
📝 摘要(中文)
本文提出了Track Any Peppers (TAP),一种用于甜椒追踪的弱监督集成技术,旨在解决甜椒检测与多目标追踪挑战。TAP利用视觉-语言基础模型(如Grounding DINO)的零样本检测能力,以最少的人工干预自动生成视频序列中甜椒的伪标签。这些伪标签在必要时经过优化,用于训练YOLOv8分割网络。为了提高复杂条件下的检测精度,我们结合了光照调整等预处理技术,并在后推理过程中应用基于深度的滤波。在目标追踪方面,我们将Matching by Segment Anything (MASA)适配器与BoT-SORT算法集成。实验结果表明,该方法实现了80.4%的HOTA,66.1%的MOTA,74.0%的召回率和90.7%的精确率,无需大量人工标注即可有效追踪甜椒。这项工作突出了基础模型在农业环境中高效、准确的目标检测和追踪方面的潜力。
🔬 方法详解
问题定义:论文旨在解决甜椒检测与多目标追踪问题,尤其是在缺乏大量标注数据的情况下。现有方法依赖于大量人工标注,成本高,泛化能力差,难以适应不同光照、遮挡等复杂农业环境。
核心思路:论文的核心思路是利用视觉-语言模型(VLM)的零样本检测能力,自动生成甜椒的伪标签,从而实现弱监督学习。通过VLM先验知识,减少对人工标注的依赖,提高模型的泛化能力和效率。
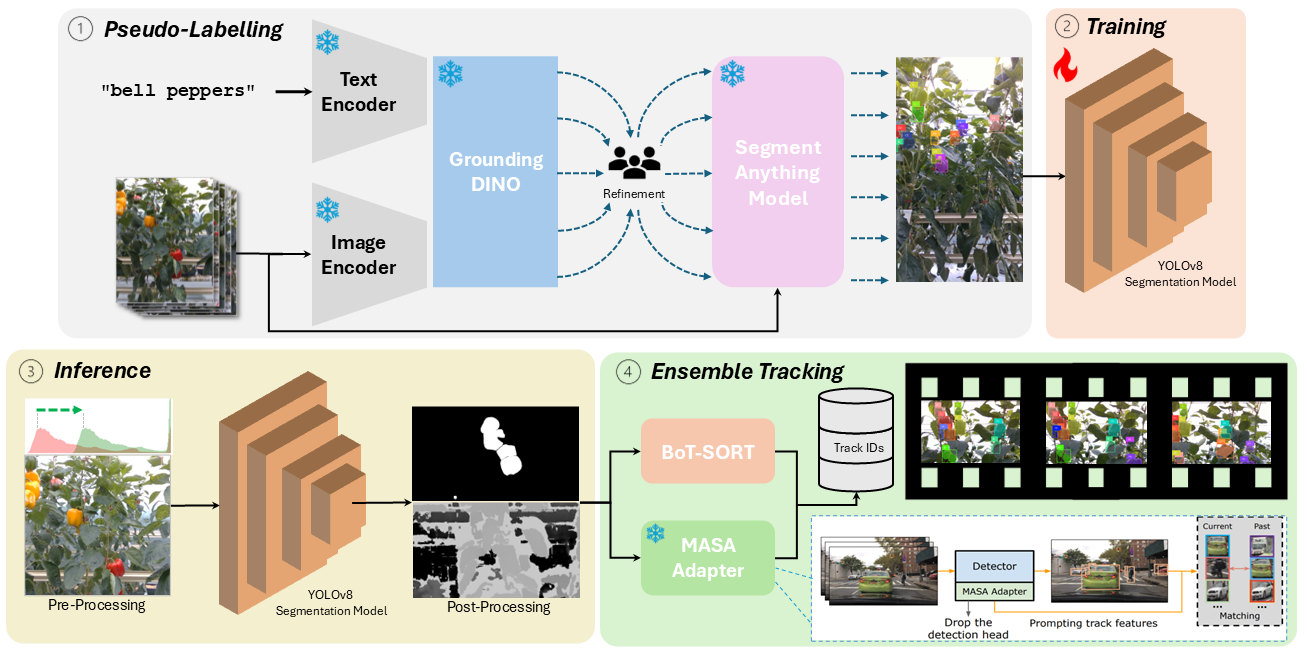
技术框架:TAP方法的整体框架包括以下几个阶段:1) 利用Grounding DINO等VLM进行零样本甜椒检测,生成初始伪标签;2) 对伪标签进行优化,例如人工修正错误标签;3) 使用优化后的伪标签训练YOLOv8分割网络,提高甜椒检测精度;4) 结合MASA适配器和BoT-SORT算法进行目标追踪,实现甜椒在视频序列中的稳定追踪;5) 应用预处理技术(如光照调整)和后处理技术(如深度滤波)进一步提升性能。
关键创新:该方法最重要的创新点在于利用VLM的零样本检测能力,实现了甜椒追踪的弱监督学习。与传统的监督学习方法相比,该方法大大减少了对人工标注数据的需求,降低了成本,提高了效率。此外,MASA适配器与BoT-SORT算法的集成也提升了追踪的鲁棒性。
关键设计:在伪标签生成阶段,使用了Grounding DINO等VLM,并根据实际情况进行人工修正。在目标检测阶段,选择了YOLOv8分割网络,并针对甜椒的特点进行了优化。在目标追踪阶段,集成了MASA适配器,利用分割信息提高追踪的准确性。此外,还采用了光照调整等预处理技术和深度滤波等后处理技术,以应对复杂环境下的挑战。
🖼️ 关键图片
📊 实验亮点
TAP方法在甜椒追踪任务中取得了显著的性能提升,HOTA达到80.4%,MOTA达到66.1%,召回率达到74.0%,精确率达到90.7%。这些结果表明,该方法在无需大量人工标注的情况下,能够有效地追踪甜椒,具有很高的实用价值。
🎯 应用场景
该研究成果可广泛应用于智慧农业领域,例如自动化采摘机器人、农作物生长监测系统等。通过精准追踪农作物,可以实现精细化管理,提高产量和质量,降低人工成本。未来,该方法有望扩展到其他农作物的检测与追踪,推动农业智能化发展。
📄 摘要(原文)
In the Detection and Multi-Object Tracking of Sweet Peppers Challenge, we present Track Any Peppers (TAP) - a weakly supervised ensemble technique for sweet peppers tracking. TAP leverages the zero-shot detection capabilities of vision-language foundation models like Grounding DINO to automatically generate pseudo-labels for sweet peppers in video sequences with minimal human intervention. These pseudo-labels, refined when necessary, are used to train a YOLOv8 segmentation network. To enhance detection accuracy under challenging conditions, we incorporate pre-processing techniques such as relighting adjustments and apply depth-based filtering during post-inference. For object tracking, we integrate the Matching by Segment Anything (MASA) adapter with the BoT-SORT algorithm. Our approach achieves a HOTA score of 80.4%, MOTA of 66.1%, Recall of 74.0%, and Precision of 90.7%, demonstrating effective tracking of sweet peppers without extensive manual effort. This work highlights the potential of foundation models for efficient and accurate object detection and tracking in agricultural settings.