LFSamba: Marry SAM with Mamba for Light Field Salient Object Detection
作者: Zhengyi Liu, Longzhen Wang, Xianyong Fang, Zhengzheng Tu, Linbo Wang
分类: cs.CV
发布日期: 2024-11-11
备注: Accepted by SPL
🔗 代码/项目: GITHUB
💡 一句话要点
LFSamba:结合SAM与Mamba的光场显著性目标检测模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 光场显著性目标检测 SAM Mamba 长程依赖建模 弱监督学习
📋 核心要点
- 现有光场显著性目标检测方法在特征提取和关系建模方面存在不足,难以充分利用光场图像的空间几何信息。
- LFSamba模型通过结合SAM和Mamba,分别实现高效的模态感知特征提取和长程依赖关系建模,从而提升显著性检测性能。
- 该研究还构建了首个光场显著性目标检测的涂鸦监督数据集,并建立了相应的基线,为弱监督学习提供了基础。
📝 摘要(中文)
本文提出了一种用于多焦点光场图像的先进显著性目标检测模型LFSamba。该模型强调四个主要创新点:(a)高效特征提取,利用SAM提取模态感知的判别性特征;(b)片间关系建模,利用Mamba捕捉多个焦点切片之间的长程依赖关系,从而提取隐式深度线索;(c)模态间关系建模,利用Mamba整合全焦点和多焦点图像,实现相互增强;(d)弱监督学习能力,从现有的像素级掩码数据集开发了一个涂鸦标注数据集,建立了第一个用于光场显著性目标检测的涂鸦监督基线。
🔬 方法详解
问题定义:光场显著性目标检测旨在从光场图像中准确识别并分割出最吸引人注意力的区域。现有方法通常难以有效利用光场图像中蕴含的丰富空间几何信息,尤其是在建模不同焦点切片之间的长程依赖关系方面存在不足,导致显著性检测精度受限。
核心思路:LFSamba的核心思路是结合SAM(Segment Anything Model)强大的特征提取能力和Mamba擅长处理序列数据的特性,分别用于提取模态感知的判别性特征和建模焦点切片之间的长程依赖关系。通过这种方式,模型能够更有效地利用光场图像中的空间几何信息,从而提升显著性检测性能。同时,利用Mamba进行模态间融合,增强全焦点和多焦点图像的互补性。
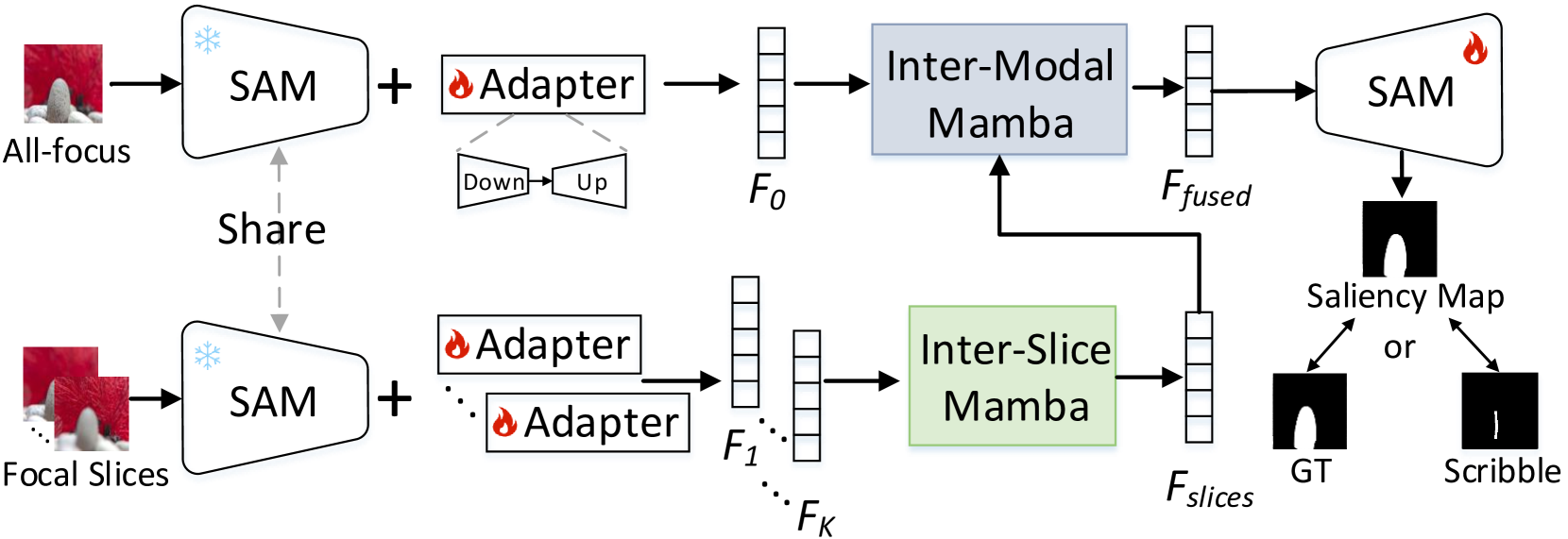
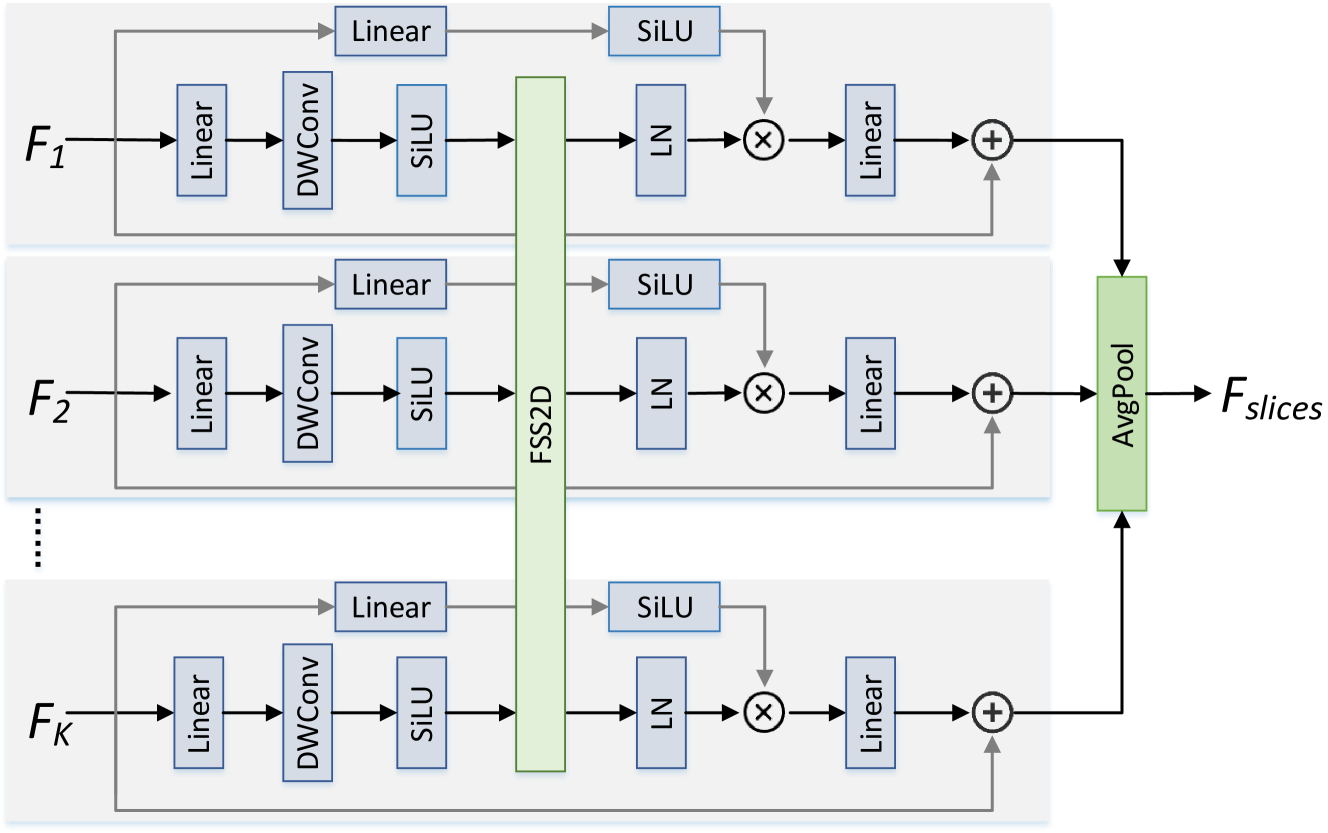
技术框架:LFSamba的整体架构包含以下几个主要模块:1) 特征提取模块:使用SAM提取全焦点图像和多焦点图像的特征,得到模态感知的特征表示。2) 片间关系建模模块:利用Mamba对多焦点图像的特征进行序列建模,捕捉不同焦点切片之间的长程依赖关系,提取隐式深度线索。3) 模态间关系建模模块:再次利用Mamba融合全焦点图像和多焦点图像的特征,实现模态间的互补增强。4) 显著性预测模块:将融合后的特征输入到解码器中,预测显著性图。
关键创新:LFSamba的关键创新在于:1) 将SAM引入光场显著性目标检测领域,用于高效的模态感知特征提取。2) 利用Mamba建模焦点切片之间的长程依赖关系,从而更有效地利用光场图像中的空间几何信息。3) 提出了基于涂鸦标注的光场显著性目标检测弱监督学习方法,降低了标注成本。
关键设计:在特征提取模块中,使用了预训练的SAM模型,并针对光场图像的特点进行了微调。在片间关系建模模块中,Mamba的序列长度设置为焦点切片的数量。在模态间关系建模模块中,Mamba的输入是全焦点图像和多焦点图像的特征拼接。损失函数包括二元交叉熵损失和IoU损失,用于优化显著性预测结果。涂鸦监督学习中,设计了特定的损失函数来约束模型在涂鸦区域内的预测结果。
🖼️ 关键图片

📊 实验亮点
该论文提出的LFSamba模型在多个光场显著性目标检测数据集上取得了state-of-the-art的性能。实验结果表明,LFSamba能够有效地利用光场图像中的空间几何信息,显著提升显著性检测的精度。此外,涂鸦监督学习方法在降低标注成本的同时,仍然能够取得具有竞争力的性能。
🎯 应用场景
LFSamba在立体摄影、虚拟现实、机器人视觉等领域具有广泛的应用前景。例如,可以用于增强3D场景重建的精度,提高虚拟现实体验的沉浸感,以及提升机器人对复杂环境的感知能力。此外,该研究提出的涂鸦监督学习方法可以降低光场显著性目标检测的标注成本,促进该技术在更多实际场景中的应用。
📄 摘要(原文)
A light field camera can reconstruct 3D scenes using captured multi-focus images that contain rich spatial geometric information, enhancing applications in stereoscopic photography, virtual reality, and robotic vision. In this work, a state-of-the-art salient object detection model for multi-focus light field images, called LFSamba, is introduced to emphasize four main insights: (a) Efficient feature extraction, where SAM is used to extract modality-aware discriminative features; (b) Inter-slice relation modeling, leveraging Mamba to capture long-range dependencies across multiple focal slices, thus extracting implicit depth cues; (c) Inter-modal relation modeling, utilizing Mamba to integrate all-focus and multi-focus images, enabling mutual enhancement; (d) Weakly supervised learning capability, developing a scribble annotation dataset from an existing pixel-level mask dataset, establishing the first scribble-supervised baseline for light field salient object detection.https://github.com/liuzywen/LFScribble