CAD-MLLM: Unifying Multimodality-Conditioned CAD Generation With MLLM
作者: Jingwei Xu, Chenyu Wang, Zibo Zhao, Wen Liu, Yi Ma, Shenghua Gao
分类: cs.CV
发布日期: 2024-11-07 (更新: 2025-08-04)
备注: Project page: https://cad-mllm.github.io/
💡 一句话要点
CAD-MLLM:提出一种统一的多模态条件CAD生成框架,利用MLLM实现文本、图像、点云等多模态输入驱动的CAD模型生成。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: CAD生成 多模态学习 大型语言模型 计算机视觉 参数化建模
📋 核心要点
- 现有CAD生成方法难以统一处理文本、图像、点云等多模态输入,限制了用户交互的灵活性。
- CAD-MLLM利用大型语言模型对齐多模态特征空间和CAD模型命令序列,实现多模态条件下的CAD模型生成。
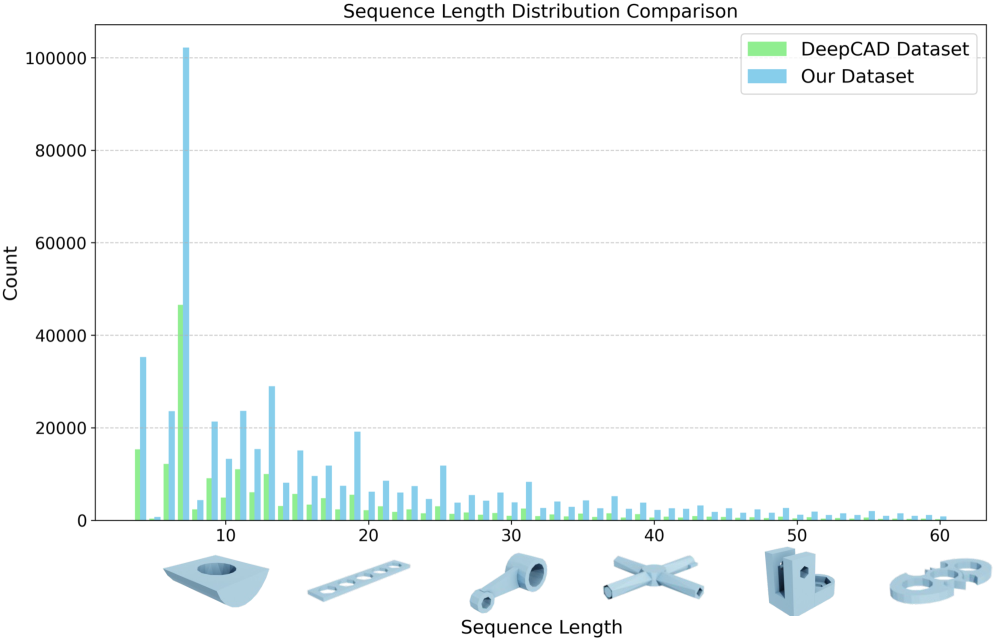
- Omni-CAD数据集包含45万个CAD实例及其多模态数据,实验表明CAD-MLLM在生成质量和鲁棒性方面优于现有方法。
📝 摘要(中文)
本文旨在设计一个统一的计算机辅助设计(CAD)生成系统,该系统能够根据用户以文本描述、图像、点云或它们的组合形式的输入,轻松生成CAD模型。为此,我们引入了CAD-MLLM,这是第一个能够根据多模态输入生成参数化CAD模型的系统。具体来说,在CAD-MLLM框架内,我们利用CAD模型的命令序列,然后使用先进的大型语言模型(LLM)来对齐这些不同的多模态数据和CAD模型的向量化表示之间的特征空间。为了方便模型训练,我们设计了一个全面的数据构建和标注流程,为每个CAD模型配备了相应的多模态数据。我们最终得到的数据集名为Omni-CAD,是第一个多模态CAD数据集,包含每个CAD模型的文本描述、多视角图像、点云和命令序列。它包含大约45万个实例及其CAD构建序列。为了彻底评估我们生成的CAD模型的质量,我们超越了当前侧重于重建质量的评估指标,引入了评估拓扑质量和表面封闭程度的额外指标。大量的实验结果表明,CAD-MLLM显著优于现有的条件生成方法,并且对噪声和缺失点具有很强的鲁棒性。
🔬 方法详解
问题定义:现有CAD生成方法通常只支持单一模态的输入,例如仅支持文本描述或者仅支持图像。这限制了用户交互的灵活性,无法充分利用不同模态的信息。此外,现有的评估指标主要关注重建质量,忽略了拓扑结构和表面封闭性等重要方面。
核心思路:CAD-MLLM的核心思路是利用大型语言模型(LLM)强大的多模态理解和生成能力,将不同模态的输入(文本、图像、点云)统一到一个共同的特征空间中,并将其与CAD模型的命令序列对齐。通过学习这种对齐关系,模型可以根据多模态输入生成相应的CAD模型。
技术框架:CAD-MLLM的整体框架包含以下几个主要模块:1) 多模态编码器:用于将文本、图像和点云等输入编码为特征向量。2) LLM:用于对齐多模态特征空间和CAD模型命令序列,并生成CAD命令序列。3) CAD解码器:用于将CAD命令序列解码为最终的CAD模型。训练过程中,模型通过最小化生成CAD模型与真实CAD模型之间的差异来学习多模态输入与CAD模型之间的映射关系。
关键创新:CAD-MLLM的关键创新在于:1) 提出了一个统一的多模态CAD生成框架,可以处理文本、图像、点云等多种输入模态。2) 利用大型语言模型(LLM)来对齐多模态特征空间和CAD模型命令序列,从而实现多模态条件下的CAD模型生成。3) 构建了一个大规模的多模态CAD数据集Omni-CAD,包含45万个CAD实例及其多模态数据。
关键设计:CAD-MLLM使用了预训练的大型语言模型,例如LLaMA或GPT系列,并对其进行了微调,使其能够更好地理解和生成CAD命令序列。损失函数方面,除了重建损失外,还引入了拓扑损失和表面封闭性损失,以提高生成CAD模型的质量。具体参数设置和网络结构细节在论文中有详细描述,此处未知。
🖼️ 关键图片


📊 实验亮点
实验结果表明,CAD-MLLM在CAD模型生成任务上显著优于现有的条件生成方法。在Omni-CAD数据集上,CAD-MLLM在重建质量、拓扑质量和表面封闭性等方面均取得了显著提升。此外,CAD-MLLM对噪声和缺失点具有很强的鲁棒性,即使在输入数据存在缺陷的情况下,也能生成高质量的CAD模型。具体性能数据未知。
🎯 应用场景
CAD-MLLM具有广泛的应用前景,例如:1) 智能设计助手:根据用户的文本描述、草图或点云快速生成CAD模型。2) 逆向工程:根据产品的图像或点云重建CAD模型。3) 个性化定制:根据用户的需求定制CAD模型。该研究有望提高CAD设计的效率和创造性,促进制造业的智能化发展。
📄 摘要(原文)
This paper aims to design a unified Computer-Aided Design (CAD) generation system that can easily generate CAD models based on the user's inputs in the form of textual description, images, point clouds, or even a combination of them. Towards this goal, we introduce the CAD-MLLM, the first system capable of generating parametric CAD models conditioned on the multimodal input. Specifically, within the CAD-MLLM framework, we leverage the command sequences of CAD models and then employ advanced large language models (LLMs) to align the feature space across these diverse multi-modalities data and CAD models' vectorized representations. To facilitate the model training, we design a comprehensive data construction and annotation pipeline that equips each CAD model with corresponding multimodal data. Our resulting dataset, named Omni-CAD, is the first multimodal CAD dataset that contains textual description, multi-view images, points, and command sequence for each CAD model. It contains approximately 450K instances and their CAD construction sequences. To thoroughly evaluate the quality of our generated CAD models, we go beyond current evaluation metrics that focus on reconstruction quality by introducing additional metrics that assess topology quality and surface enclosure extent. Extensive experimental results demonstrate that CAD-MLLM significantly outperforms existing conditional generative methods and remains highly robust to noises and missing points. The project page and more visualizations can be found at: https://cad-mllm.github.io/