A Reinforcement Learning-Based Automatic Video Editing Method Using Pre-trained Vision-Language Model
作者: Panwen Hu, Nan Xiao, Feifei Li, Yongquan Chen, Rui Huang
分类: cs.CV
发布日期: 2024-11-07
💡 一句话要点
提出基于预训练视觉-语言模型的强化学习自动视频剪辑方法,用于通用场景视频编辑。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 自动视频剪辑 强化学习 视觉-语言模型 通用场景编辑 序列决策
📋 核心要点
- 现有自动视频剪辑系统多针对特定场景,通用场景下的自动剪辑研究不足,且事件驱动方法难以直接迁移。
- 利用预训练视觉-语言模型提取编辑相关的上下文表示,并构建基于强化学习的框架进行序列编辑决策。
- 在真实电影数据集上的实验表明,该方法提出的上下文表示和强化学习框架具有有效性和学习能力。
📝 摘要(中文)
本文提出了一种基于强化学习的自动视频剪辑方法,该方法利用预训练的视觉-语言模型。现有的自动剪辑系统主要针对特定场景或事件,例如足球比赛直播,而针对通用编辑(如电影或vlog编辑)的自动系统研究较少。本文提出一个两阶段方案用于通用编辑。首先,不同于以往提取特定场景特征的方法,我们利用预训练的视觉-语言模型(VLM)提取与编辑相关的表示作为编辑上下文。此外,为了缩小专业视频与简单指导下生成的自动作品之间的差距,我们提出了一个基于强化学习(RL)的编辑框架,将编辑问题形式化,并训练虚拟编辑器做出更好的序列编辑决策。最后,我们在一个真实的电影数据集上评估了该方法,实验结果表明了所提出的上下文表示和基于RL的编辑框架的学习能力是有效且有益的。
🔬 方法详解
问题定义:现有自动视频剪辑系统主要集中在特定场景或事件,例如体育赛事。通用场景下的自动视频剪辑,例如电影或vlog的编辑,仍然是一个挑战。现有的事件驱动的编辑方法难以直接应用于通用场景,并且生成的视频质量与专业编辑的视频相比仍有差距。
核心思路:论文的核心思路是利用预训练的视觉-语言模型(VLM)来提取与编辑相关的上下文信息,并使用强化学习(RL)框架来学习最佳的编辑策略。VLM能够捕捉视频内容和语义信息,为编辑提供更丰富的上下文。RL框架则允许系统通过试错学习,逐步优化编辑决策,从而生成更符合专业标准的视频。
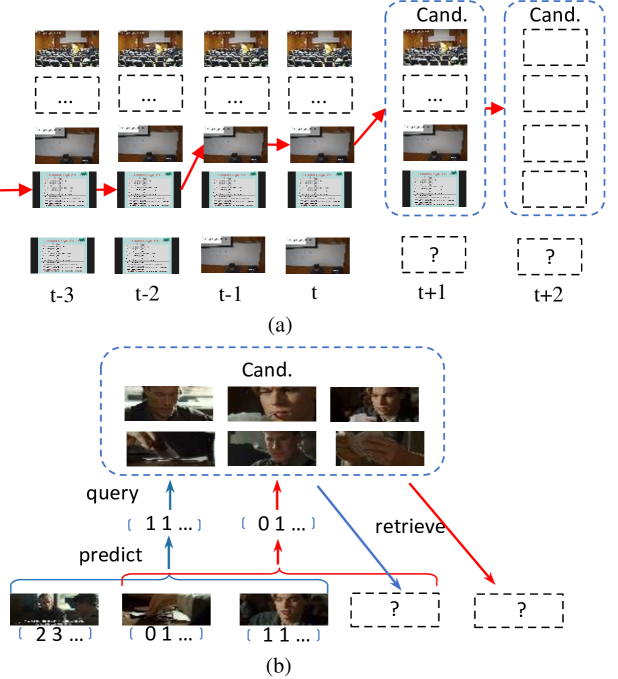
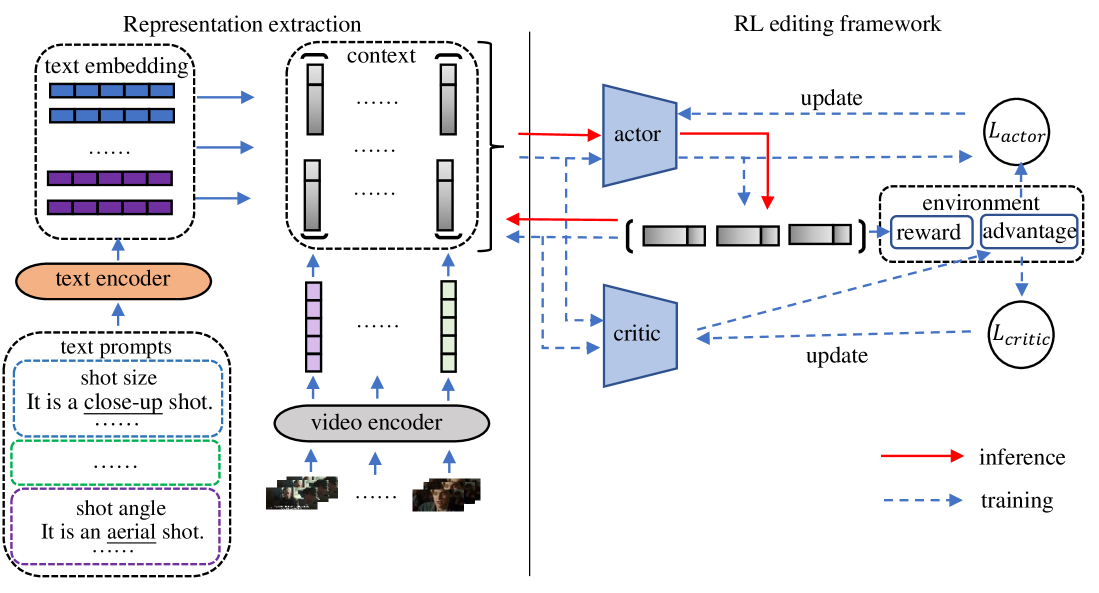
技术框架:该方法采用两阶段方案: 1. 上下文表示提取:使用预训练的视觉-语言模型提取视频片段的特征表示,作为编辑的上下文信息。 2. 强化学习编辑:构建一个强化学习环境,其中智能体(虚拟编辑器)通过与环境交互,学习最佳的编辑策略。智能体根据当前上下文信息选择编辑动作(例如,剪切、拼接等),并根据编辑结果获得奖励。通过不断学习,智能体逐渐掌握最佳的编辑策略。
关键创新:该方法的关键创新在于: 1. 利用预训练VLM提取编辑上下文:不同于以往方法中提取特定场景的特征,该方法利用VLM提取更通用的、与编辑相关的上下文表示,从而适用于更广泛的视频类型。 2. 基于RL的编辑框架:将视频编辑问题形式化为一个序列决策问题,并使用RL来训练虚拟编辑器,使其能够做出更好的编辑决策。
关键设计: * 视觉-语言模型选择:具体使用的VLM模型未知,但需要选择能够有效提取视频内容和语义信息的模型。 * 强化学习环境设计:需要定义状态空间(例如,视频片段的特征表示、已编辑视频的长度等)、动作空间(例如,剪切、拼接等编辑操作)和奖励函数(例如,视频的流畅度、信息量等)。 * 奖励函数设计:奖励函数的设计至关重要,需要能够反映视频编辑的质量,并引导智能体学习最佳的编辑策略。奖励函数可能包括多个指标的加权组合,例如视频的流畅度、信息量、吸引力等。
🖼️ 关键图片

📊 实验亮点
论文在真实电影数据集上进行了实验,验证了所提出方法的有效性。实验结果表明,该方法能够生成质量较高的视频剪辑,并且优于传统的基于规则的编辑方法。具体的性能数据和提升幅度未知,但实验结果证明了VLM提取的上下文表示和RL框架的学习能力。
🎯 应用场景
该研究成果可应用于多种场景,包括:自动生成vlog、电影剪辑、新闻视频编辑、教育视频制作等。它可以降低视频编辑的门槛,提高视频制作效率,并为用户提供更个性化的视频内容。未来,该技术有望与智能推荐系统结合,根据用户兴趣自动生成定制化的视频。
📄 摘要(原文)
In this era of videos, automatic video editing techniques attract more and more attention from industry and academia since they can reduce workloads and lower the requirements for human editors. Existing automatic editing systems are mainly scene- or event-specific, e.g., soccer game broadcasting, yet the automatic systems for general editing, e.g., movie or vlog editing which covers various scenes and events, were rarely studied before, and converting the event-driven editing method to a general scene is nontrivial. In this paper, we propose a two-stage scheme for general editing. Firstly, unlike previous works that extract scene-specific features, we leverage the pre-trained Vision-Language Model (VLM) to extract the editing-relevant representations as editing context. Moreover, to close the gap between the professional-looking videos and the automatic productions generated with simple guidelines, we propose a Reinforcement Learning (RL)-based editing framework to formulate the editing problem and train the virtual editor to make better sequential editing decisions. Finally, we evaluate the proposed method on a more general editing task with a real movie dataset. Experimental results demonstrate the effectiveness and benefits of the proposed context representation and the learning ability of our RL-based editing framework.