LidaRefer: Context-aware Outdoor 3D Visual Grounding for Autonomous Driving
作者: Yeong-Seung Baek, Heung-Seon Oh
分类: cs.CV
发布日期: 2024-11-07 (更新: 2025-07-31)
备注: 18 pages, 5 figures
💡 一句话要点
LidaRefer:面向自动驾驶的上下文感知室外3D视觉定位
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D视觉定位 自动驾驶 上下文感知 跨模态对齐 Transformer 伪标签 LiDAR点云
📋 核心要点
- 室外3D视觉定位面临大规模场景背景干扰和缺乏上下文标注的挑战,阻碍了跨模态对齐和上下文理解。
- LidaRefer通过对象中心特征选择和Transformer架构,实现精细跨模态对齐和全局上下文建模,提升定位精度。
- 提出的DiSCo监督策略和伪标签方法,显式建模目标、上下文和模糊对象关系,并在Talk2Car-3D数据集上取得SOTA性能。
📝 摘要(中文)
3D视觉定位(VG)旨在根据自然语言描述在3D场景中定位物体或区域。虽然室内3D VG已经取得了进展,但由于两个挑战,室外3D VG仍未得到充分探索:(1)大规模室外LiDAR场景主要由背景点组成,包含的foreground信息有限,使得跨模态对齐和上下文理解更加困难;(2)大多数室外数据集缺乏参考非目标对象的空间注释,这阻碍了参考上下文的显式学习。为此,我们提出了LidaRefer,一个用于室外场景的上下文感知3D VG框架。LidaRefer结合了一种以对象为中心的特征选择策略,以专注于语义相关的视觉特征,同时减少计算开销。然后,其基于Transformer的编码器-解码器架构擅长在精细化的视觉特征和词级文本特征之间建立细粒度的跨模态对齐,并捕获全面的全局上下文。此外,我们提出了一种判别-支持协作定位(DiSCo)的新型监督策略,该策略显式地建模目标、上下文和模糊对象之间的空间关系,以实现准确的目标识别。为了在没有手动标记的情况下实现这一点,我们引入了一种伪标记方法,该方法检索参考非目标对象的3D定位标签。LidaRefer在各种评估设置下,在Talk2Car-3D数据集上实现了最先进的性能。
🔬 方法详解
问题定义:论文旨在解决室外3D场景下的视觉定位问题。现有方法在处理大规模LiDAR点云时,容易受到背景噪声的干扰,且缺乏对上下文信息的有效利用。此外,现有数据集缺乏对非目标参考对象的标注,限制了模型对上下文关系的显式学习。
核心思路:论文的核心思路是利用对象中心的特征选择策略,减少背景噪声的干扰,并结合Transformer架构实现跨模态的细粒度对齐和全局上下文建模。通过引入判别-支持协作定位(DiSCo)监督策略和伪标签方法,显式地建模目标、上下文和模糊对象之间的关系,从而提高定位的准确性。
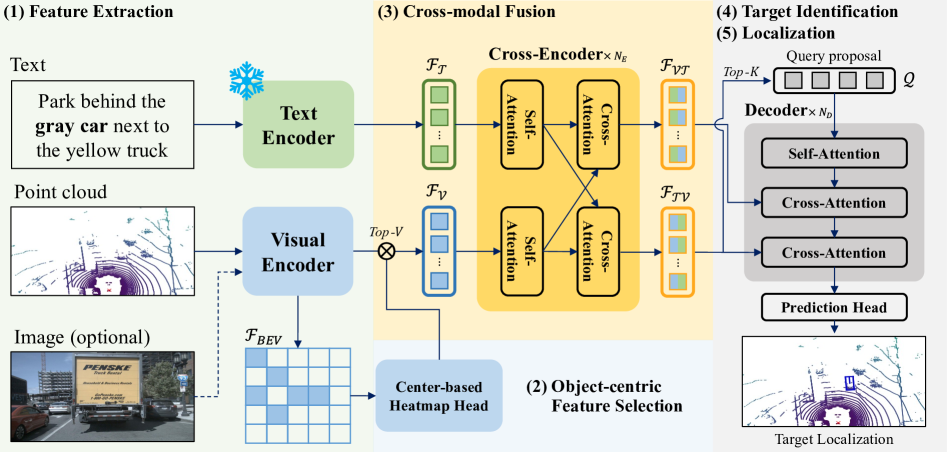
技术框架:LidaRefer框架主要包含以下几个模块:1) 对象中心特征选择模块,用于提取与目标对象相关的视觉特征,减少背景噪声的干扰;2) 基于Transformer的编码器-解码器架构,用于实现视觉特征和文本特征之间的跨模态对齐和全局上下文建模;3) 判别-支持协作定位(DiSCo)监督策略,用于显式地建模目标、上下文和模糊对象之间的关系;4) 伪标签生成模块,用于自动标注非目标参考对象,从而扩充训练数据。
关键创新:论文的关键创新点在于:1) 提出了对象中心的特征选择策略,有效减少了背景噪声的干扰;2) 引入了判别-支持协作定位(DiSCo)监督策略,显式地建模了目标、上下文和模糊对象之间的关系;3) 提出了伪标签生成方法,自动标注非目标参考对象,从而扩充了训练数据。
关键设计:对象中心特征选择策略的具体实现方式未知。Transformer架构的具体参数设置未知。DiSCo损失函数的具体形式未知。伪标签生成模块的具体算法未知。
🖼️ 关键图片


📊 实验亮点
LidaRefer在Talk2Car-3D数据集上取得了state-of-the-art的性能,证明了其在室外3D视觉定位方面的有效性。具体的性能数据和提升幅度在论文中未明确给出,但摘要中强调了其超越现有方法的性能表现。
🎯 应用场景
该研究成果可应用于自动驾驶、机器人导航、增强现实等领域。通过结合自然语言描述和3D场景信息,可以实现更精准的目标定位和场景理解,从而提高自动驾驶系统的安全性和可靠性,增强人机交互的自然性和智能化水平。未来,该技术有望在智慧城市、智能交通等领域发挥重要作用。
📄 摘要(原文)
3D visual grounding (VG) aims to locate objects or regions within 3D scenes guided by natural language descriptions. While indoor 3D VG has advanced, outdoor 3D VG remains underexplored due to two challenges: (1) large-scale outdoor LiDAR scenes are dominated by background points and contain limited foreground information, making cross-modal alignment and contextual understanding more difficult; and (2) most outdoor datasets lack spatial annotations for referential non-target objects, which hinders explicit learning of referential context. To this end, we propose LidaRefer, a context-aware 3D VG framework for outdoor scenes. LidaRefer incorporates an object-centric feature selection strategy to focus on semantically relevant visual features while reducing computational overhead. Then, its transformer-based encoder-decoder architecture excels at establishing fine-grained cross-modal alignment between refined visual features and word-level text features, and capturing comprehensive global context. Additionally, we present Discriminative-Supportive Collaborative localization (DiSCo), a novel supervision strategy that explicitly models spatial relationships between target, contextual, and ambiguous objects for accurate target identification. To enable this without manual labeling, we introduce a pseudo-labeling approach that retrieves 3D localization labels for referential non-target objects. LidaRefer achieves state-of-the-art performance on Talk2Car-3D dataset under various evaluation settings.