Revisiting Disparity from Dual-Pixel Images: Physics-Informed Lightweight Depth Estimation
作者: Teppei Kurita, Yuhi Kondo, Legong Sun, Takayuki Sasaki, Sho Nitta, Yasuhiro Hashimoto, Yoshinori Muramatsu, Yusuke Moriuchi
分类: cs.CV
发布日期: 2024-11-06
备注: Accepted to IEEE Winter Conference on Applications of Computer Vision (WACV) 2025
💡 一句话要点
提出基于物理信息的轻量级双像素图像深度估计方法,实现高性能和小模型。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 双像素图像 深度估计 视差估计 轻量级网络 物理信息 非学习细化 RGB-D数据集
📋 核心要点
- 传统深度学习方法参数量大,未能充分利用双像素图像的视差约束,导致深度估计性能受限。
- 通过显式约束视差,并学习双像素图像的物理特性,提出了一种轻量级的深度估计网络。
- 实验表明,该方法在减少模型大小的同时,实现了最先进的深度估计精度,且无需双像素数据集训练。
📝 摘要(中文)
本研究提出了一种使用双像素(DP)图像的高性能视差(深度)估计方法,该方法参数量少。传统的端到端深度学习方法参数众多,但未能充分利用视差约束,限制了其性能。因此,我们提出了一种基于补全网络的轻量级视差估计方法,该方法显式地约束视差,并学习DP的物理和系统视差特性。通过参数化地建模DP特有的视差误差,并将其用于训练期间的采样,网络获得了DP的独特属性并增强了鲁棒性。这种学习还允许我们使用通用的RGB-D数据集进行训练,而无需耗费人力获取DP数据集。此外,我们提出了一种非学习的细化框架,通过适当地细化网络输出的置信度图,有效地处理固有的视差扩展误差。结果表明,即使不使用DP数据集进行训练,所提出的方法也实现了最先进的结果,同时将整个系统的大小减少到传统方法的1/5,从而证明了其有效性。代码和数据集可在我们的项目网站上找到。
🔬 方法详解
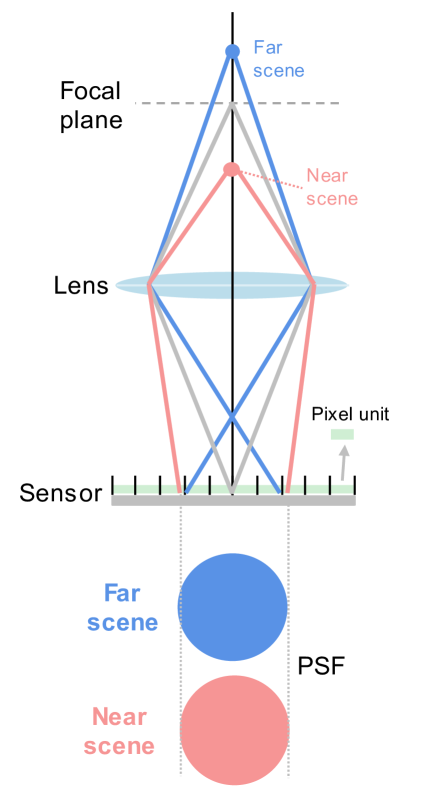
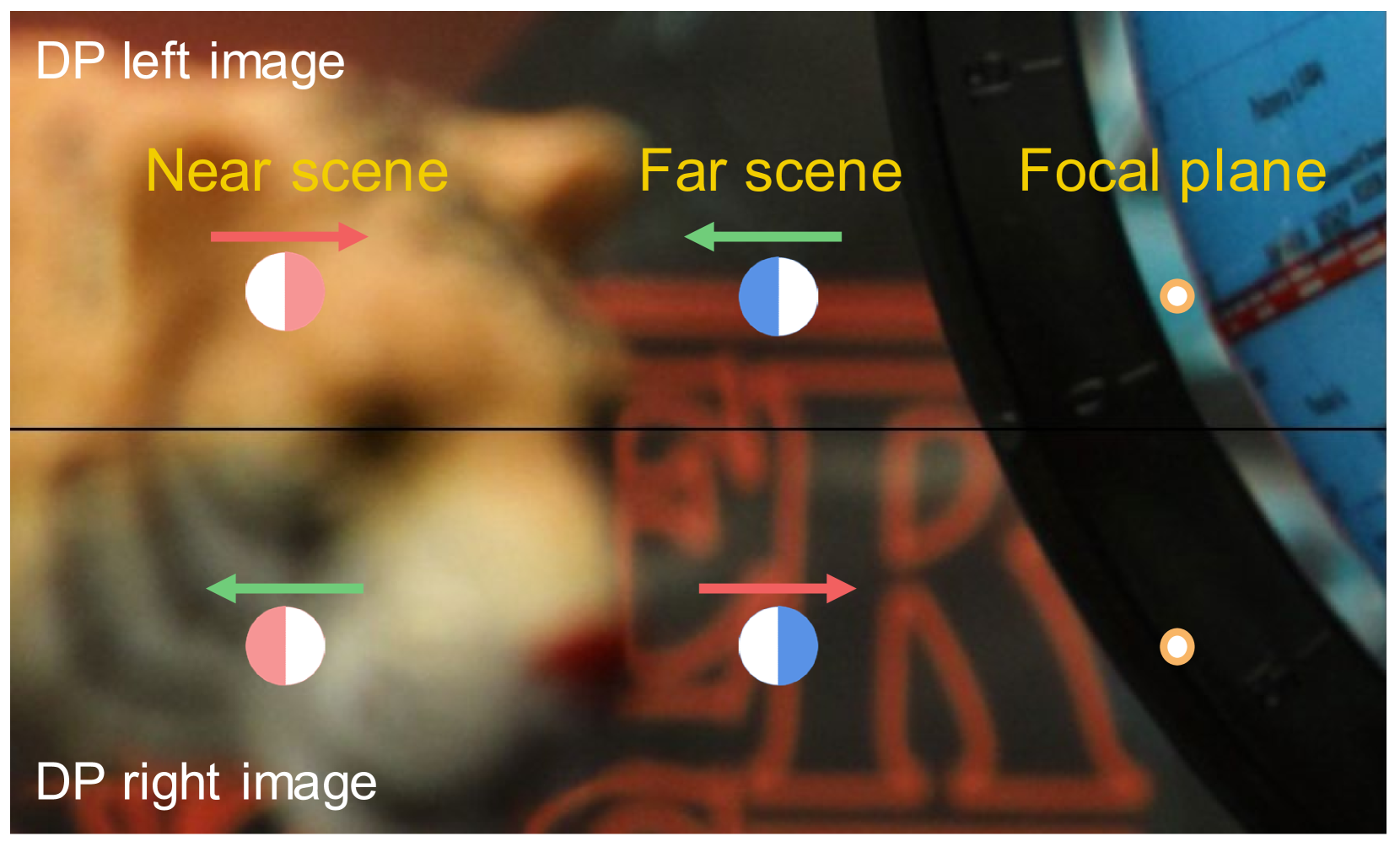
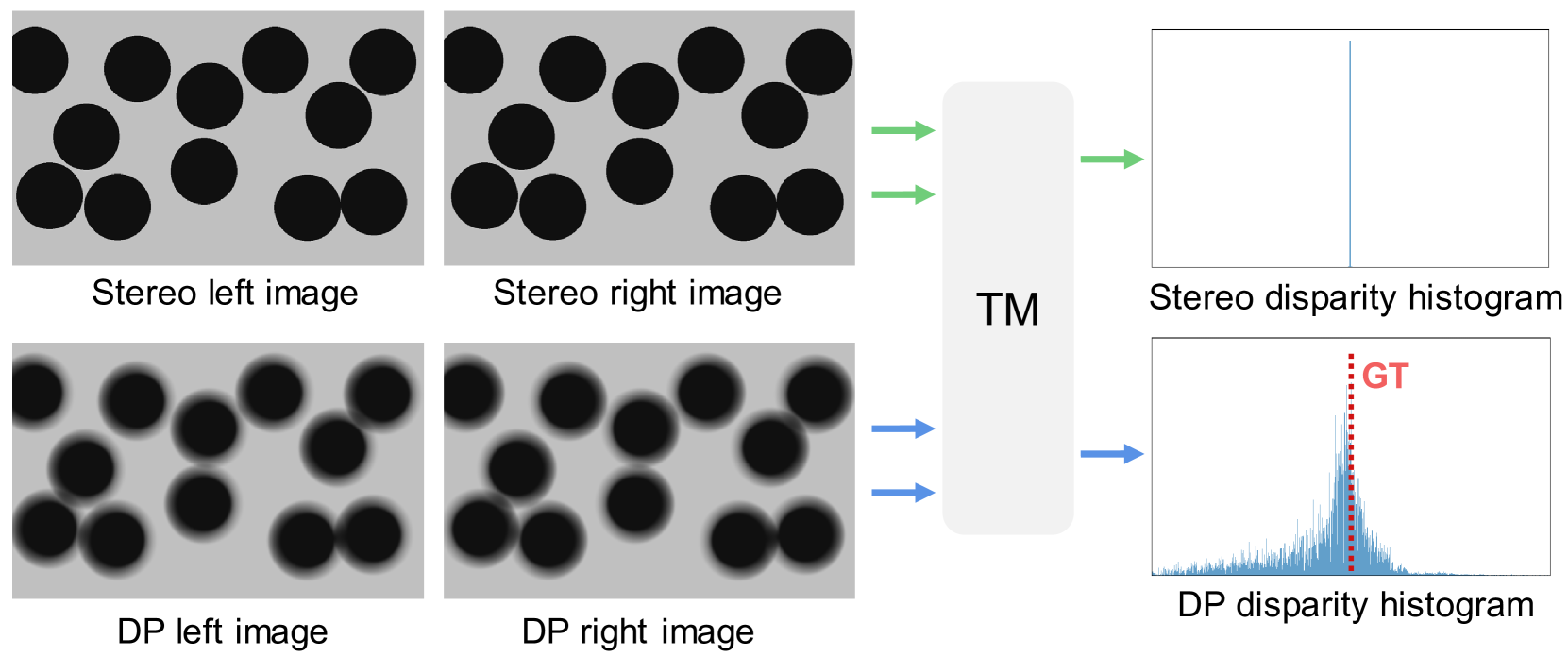
问题定义:论文旨在解决双像素图像的深度估计问题。现有基于深度学习的方法通常参数量大,计算复杂度高,并且没有充分利用双像素图像固有的视差信息,导致深度估计精度不高。此外,获取大规模的双像素数据集成本很高,限制了模型的训练和泛化能力。
核心思路:论文的核心思路是设计一个轻量级的网络,显式地建模和利用双像素图像的视差特性。通过参数化建模双像素图像特有的视差误差,并在训练过程中进行采样,使网络能够学习到双像素图像的物理和系统特性,从而提高深度估计的准确性和鲁棒性。同时,利用非学习的细化框架处理视差扩展误差。
技术框架:该方法主要包含两个阶段:基于补全网络的视差估计和非学习的视差细化。首先,使用一个轻量级的补全网络进行初始视差估计,该网络在训练过程中利用参数化的视差误差模型进行采样。然后,使用一个非学习的细化框架,基于置信度图对初始视差估计结果进行细化,以减少视差扩展误差。
关键创新:该方法最重要的创新点在于:1) 显式地建模和利用双像素图像的视差特性,通过参数化视差误差模型,使网络能够学习到双像素图像的物理和系统特性。2) 提出了一种非学习的细化框架,有效地处理了视差扩展误差,提高了深度估计的精度。3) 能够在没有双像素数据集的情况下,利用通用的RGB-D数据集进行训练。
关键设计:在网络结构方面,使用了轻量级的补全网络,以减少参数量和计算复杂度。在损失函数方面,使用了标准的深度估计损失函数,并结合了参数化的视差误差模型进行采样。在非学习的细化框架中,使用了置信度图来指导视差细化,并采用了一些启发式的规则来处理视差扩展误差。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在保持较高深度估计精度的同时,显著减少了模型的大小,仅为传统方法的1/5。即使不使用双像素数据集进行训练,该方法也能取得state-of-the-art的结果,证明了其有效性和泛化能力。项目提供了代码和数据集,方便其他研究者进行复现和改进。
🎯 应用场景
该研究成果可应用于各种需要深度信息的场景,如移动机器人、自动驾驶、增强现实和虚拟现实等。轻量级的模型设计使其能够部署在资源受限的设备上,例如手机和嵌入式系统。无需双像素数据集进行训练的特性,降低了数据采集的成本,加速了算法的落地。
📄 摘要(原文)
In this study, we propose a high-performance disparity (depth) estimation method using dual-pixel (DP) images with few parameters. Conventional end-to-end deep-learning methods have many parameters but do not fully exploit disparity constraints, which limits their performance. Therefore, we propose a lightweight disparity estimation method based on a completion-based network that explicitly constrains disparity and learns the physical and systemic disparity properties of DP. By modeling the DP-specific disparity error parametrically and using it for sampling during training, the network acquires the unique properties of DP and enhances robustness. This learning also allows us to use a common RGB-D dataset for training without a DP dataset, which is labor-intensive to acquire. Furthermore, we propose a non-learning-based refinement framework that efficiently handles inherent disparity expansion errors by appropriately refining the confidence map of the network output. As a result, the proposed method achieved state-of-the-art results while reducing the overall system size to 1/5 of that of the conventional method, even without using the DP dataset for training, thereby demonstrating its effectiveness. The code and dataset are available on our project site.