SEE-DPO: Self Entropy Enhanced Direct Preference Optimization
作者: Shivanshu Shekhar, Shreyas Singh, Tong Zhang
分类: cs.CV, cs.LG
发布日期: 2024-11-06 (更新: 2025-10-06)
💡 一句话要点
提出自熵增强直接偏好优化(SEE-DPO)以提升文本到图像扩散模型的训练稳定性和图像质量。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本到图像生成 扩散模型 直接偏好优化 自熵正则化 奖励黑客
📋 核心要点
- 现有基于DPO的扩散模型训练方法易过拟合和奖励黑客,导致训练不稳定和图像质量下降。
- 引入自熵正则化机制,鼓励模型更广泛探索,增强鲁棒性,从而缓解奖励黑客问题。
- 实验表明,该方法能显著提高图像多样性和特异性,并在图像生成指标上达到当前最佳水平。
📝 摘要(中文)
直接偏好优化(DPO)已成功应用于根据人类偏好对大型语言模型(LLM)进行对齐,最近也被应用于提高文本到图像扩散模型的质量。然而,基于DPO的方法,如SPO、Diffusion-DPO和D3PO,极易出现过拟合和奖励黑客现象,尤其是在生成模型被优化以适应长时间训练期间的分布外数据时。为了克服这些挑战并稳定扩散模型的训练,我们在基于人类反馈的强化学习中引入了一种自熵正则化机制。这种增强通过鼓励更广泛的探索和更大的鲁棒性来改进DPO训练。我们的正则化技术有效地缓解了奖励黑客问题,从而提高了潜在空间中的稳定性和图像质量。大量实验表明,将人类反馈与自熵正则化相结合可以显著提高图像的多样性和特异性,在关键图像生成指标上实现最先进的结果。
🔬 方法详解
问题定义:论文旨在解决文本到图像扩散模型中,使用直接偏好优化(DPO)进行训练时,容易出现的过拟合和奖励黑客问题。现有方法,如SPO、Diffusion-DPO和D3PO,在长时间训练中,模型容易过度拟合训练数据,导致生成质量下降,并且容易受到奖励函数的恶意利用,生成不符合人类偏好的结果。
核心思路:论文的核心思路是在DPO训练过程中引入自熵正则化。通过最大化生成图像的熵,鼓励模型探索更广泛的图像空间,避免过度集中于训练数据中的特定模式。这种方式可以提高模型的泛化能力,使其在面对未见过的输入时也能生成高质量的图像,并降低奖励黑客的风险。
技术框架:SEE-DPO的整体框架是在标准的DPO训练流程中加入自熵正则化项。具体来说,模型首先根据文本提示生成图像,然后根据人类偏好(或代理奖励模型)计算奖励值。在此基础上,计算生成图像的熵,并将其作为正则化项添加到DPO损失函数中。通过优化包含自熵正则化项的损失函数,模型可以在学习人类偏好的同时,保持生成图像的多样性。
关键创新:SEE-DPO的关键创新在于将自熵正则化引入到DPO训练中。与传统的DPO方法相比,SEE-DPO能够更好地平衡模型对人类偏好的学习和对图像空间的探索,从而提高模型的泛化能力和鲁棒性。这种方法有效地缓解了奖励黑客问题,并提高了生成图像的质量和多样性。
关键设计:自熵正则化项的具体形式为生成图像像素值概率分布的熵。在实现中,可以使用蒙特卡洛方法估计熵的值。正则化系数λ控制自熵正则化项的强度,需要根据具体任务进行调整。损失函数为DPO损失加上λ乘以负熵,目标是最小化损失函数。网络结构沿用主流扩散模型结构,如U-Net。
🖼️ 关键图片

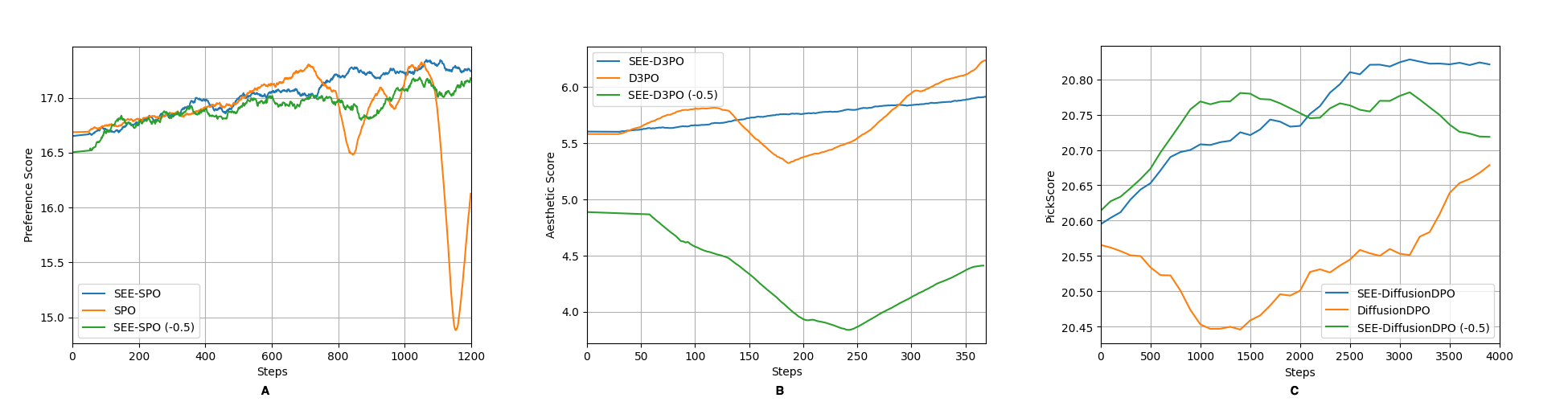

📊 实验亮点
实验结果表明,SEE-DPO在图像生成质量和多样性方面均优于现有方法。具体来说,SEE-DPO在FID(Fréchet Inception Distance)和CLIP score等指标上取得了显著提升,表明生成的图像更逼真且与文本描述更一致。此外,SEE-DPO还能够生成更多样化的图像,有效缓解了奖励黑客问题。
🎯 应用场景
该研究成果可广泛应用于各种文本到图像生成任务,例如艺术创作、产品设计、游戏开发等。通过结合人类偏好和自熵正则化,可以生成更符合用户需求、更具多样性和更高质量的图像,具有重要的实际应用价值和商业前景。未来,该方法还可以扩展到其他生成模型,如视频生成、3D模型生成等。
📄 摘要(原文)
Direct Preference Optimization (DPO) has been successfully used to align large language models (LLMs) according to human preferences, and more recently it has also been applied to improving the quality of text-to-image diffusion models. However, DPO-based methods such as SPO, Diffusion-DPO, and D3PO are highly susceptible to overfitting and reward hacking, especially when the generative model is optimized to fit out-of-distribution during prolonged training. To overcome these challenges and stabilize the training of diffusion models, we introduce a self-entropy regularization mechanism in reinforcement learning from human feedback. This enhancement improves DPO training by encouraging broader exploration and greater robustness. Our regularization technique effectively mitigates reward hacking, leading to improved stability and enhanced image quality across the latent space. Extensive experiments demonstrate that integrating human feedback with self-entropy regularization can significantly boost image diversity and specificity, achieving state-of-the-art results on key image generation metrics.