Both Text and Images Leaked! A Systematic Analysis of Data Contamination in Multimodal LLM
作者: Dingjie Song, Sicheng Lai, Mingxuan Wang, Shunian Chen, Lichao Sun, Benyou Wang
分类: cs.CV, cs.AI, cs.CL, cs.MM
发布日期: 2024-11-06 (更新: 2025-09-20)
备注: Accepted to EMNLP 2025 Findings
💡 一句话要点
提出MM-Detect框架,系统分析多模态LLM中的数据泄露问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 数据污染 大型语言模型 模型评估 视觉问答
📋 核心要点
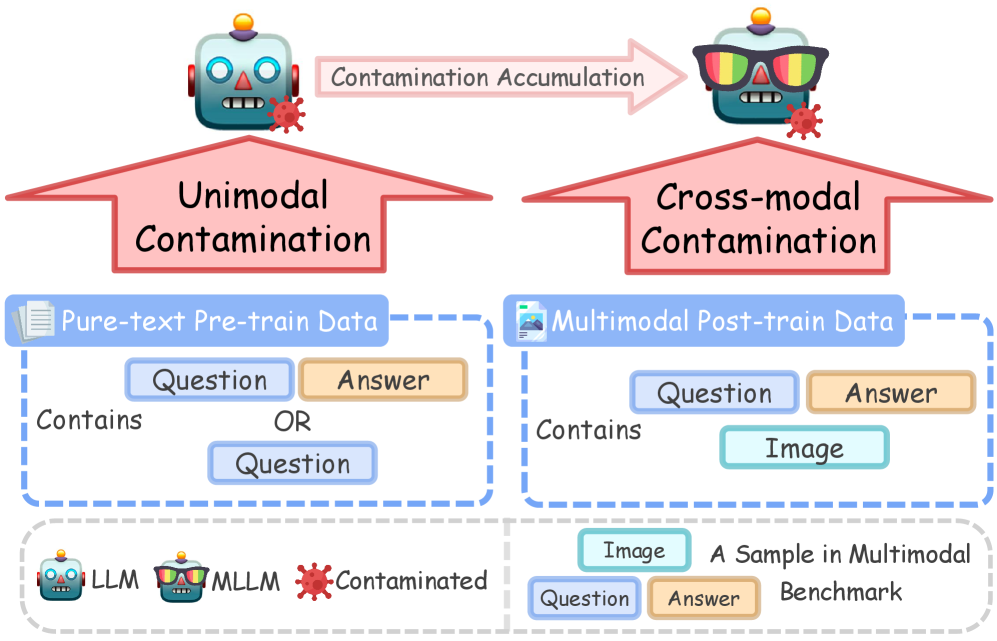
- 现有单模态LLM污染检测方法难以应对MLLM的多模态数据复杂性和多阶段训练。
- 提出MM-Detect框架,区分单模态和跨模态污染,量化MLLM在VQA任务中的污染程度。
- 实验表明MLLM存在显著污染,尤其在专有模型和旧基准中,且污染可能源于单模态预训练。
📝 摘要(中文)
多模态大型语言模型(MLLM)的快速发展显著提升了基准测试的性能。然而,数据污染——模型训练过程中无意中记忆了基准数据——对公平评估构成了严峻挑战。由于多模态数据的复杂性和多阶段训练,现有的单模态大型语言模型(LLM)的检测方法不适用于MLLM。我们使用分析框架MM-Detect系统地分析了多模态数据污染,该框架定义了两种污染类别——单模态和跨模态——并有效地量化了多项选择和基于字幕的视觉问答任务中的污染严重程度。对十二个MLLM和五个基准的评估表明存在显著的污染,尤其是在专有模型和较旧的基准中。至关重要的是,污染有时源于单模态预训练,而不仅仅是来自多模态微调。我们的见解改进了对污染的理解,指导了评估实践并提高了多模态模型的可靠性。
🔬 方法详解
问题定义:论文旨在解决多模态大型语言模型(MLLM)中数据污染检测的问题。现有针对单模态LLM的污染检测方法无法直接应用于MLLM,因为MLLM涉及更复杂的多模态数据和多阶段训练过程,例如单模态预训练和多模态微调。因此,需要一种新的方法来系统地分析和量化MLLM中的数据污染。
核心思路:论文的核心思路是构建一个名为MM-Detect的分析框架,该框架能够区分和量化MLLM中的两种数据污染类型:单模态污染和跨模态污染。单模态污染指的是模型在单模态预训练阶段记忆了benchmark数据,而跨模态污染指的是在多模态微调阶段记忆了benchmark数据。通过分析模型在不同阶段对benchmark数据的记忆程度,可以更准确地评估MLLM的性能。
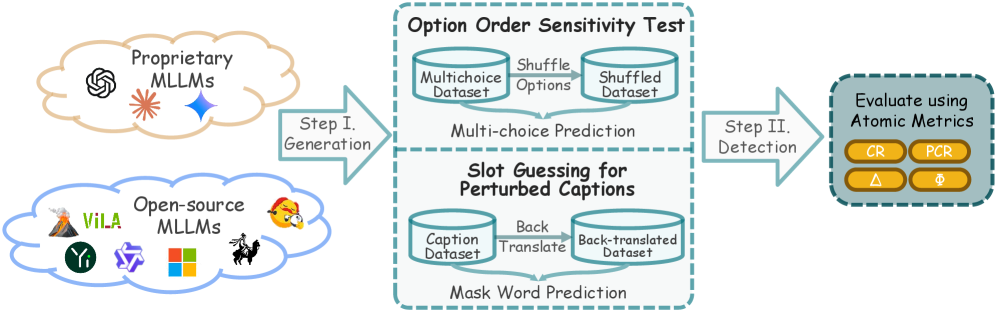
技术框架:MM-Detect框架包含以下主要模块:1) 数据准备模块,用于收集和处理MLLM的训练数据和benchmark数据;2) 污染检测模块,用于检测模型在单模态预训练和多模态微调阶段对benchmark数据的记忆程度;3) 污染量化模块,用于量化不同类型的污染对模型性能的影响。该框架可以应用于多项选择和基于字幕的视觉问答(VQA)任务。
关键创新:论文的关键创新在于提出了区分单模态和跨模态污染的概念,并设计了相应的检测方法。与现有方法相比,MM-Detect能够更全面地分析MLLM中的数据污染,并揭示污染的来源。此外,该框架还能够量化不同类型的污染对模型性能的影响,从而为模型评估和改进提供更准确的依据。
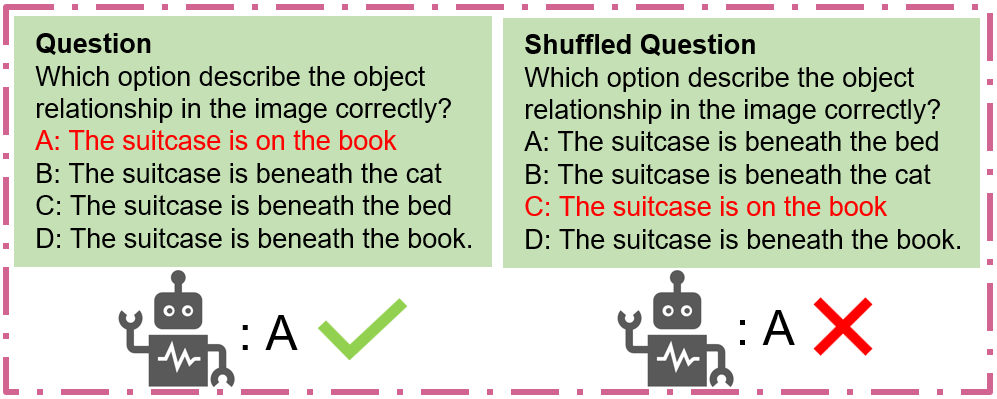
关键设计:MM-Detect框架的关键设计包括:1) 使用基于相似度的度量来检测模型对benchmark数据的记忆程度;2) 设计了针对单模态和跨模态污染的不同检测策略;3) 使用控制实验来量化不同类型的污染对模型性能的影响。具体的参数设置、损失函数和网络结构等技术细节在论文中未详细描述,属于未知信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,现有的MLLM存在显著的数据污染,尤其是在专有模型和较旧的基准测试中。更重要的是,研究发现污染可能源于单模态预训练阶段,而不仅仅是多模态微调阶段。MM-Detect框架能够有效地检测和量化不同类型的污染,为MLLM的评估和改进提供了有价值的见解。
🎯 应用场景
该研究成果可应用于多模态大型语言模型的公平评估、模型训练数据的清洗和模型可靠性的提升。通过识别和减轻数据污染,可以提高MLLM在实际应用中的泛化能力和鲁棒性,例如在智能客服、自动驾驶、医疗诊断等领域。
📄 摘要(原文)
The rapid advancement of multimodal large language models (MLLMs) has significantly enhanced performance across benchmarks. However, data contamination-unintentional memorization of benchmark data during model training-poses critical challenges for fair evaluation. Existing detection methods for unimodal large language models (LLMs) are inadequate for MLLMs due to multimodal data complexity and multi-phase training. We systematically analyze multimodal data contamination using our analytical framework, MM-Detect, which defines two contamination categories-unimodal and cross-modal-and effectively quantifies contamination severity across multiple-choice and caption-based Visual Question Answering tasks. Evaluations on twelve MLLMs and five benchmarks reveal significant contamination, particularly in proprietary models and older benchmarks. Crucially, contamination sometimes originates during unimodal pre-training rather than solely from multimodal fine-tuning. Our insights refine contamination understanding, guiding evaluation practices and improving multimodal model reliability.