SA3DIP: Segment Any 3D Instance with Potential 3D Priors
作者: Xi Yang, Xu Gu, Xingyilang Yin, Xinbo Gao
分类: cs.CV
发布日期: 2024-11-06
💡 一句话要点
SA3DIP:利用潜在3D先验分割任意3D实例,提升零样本分割性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D实例分割 零样本学习 三维场景理解 超点分割 多视角融合
📋 核心要点
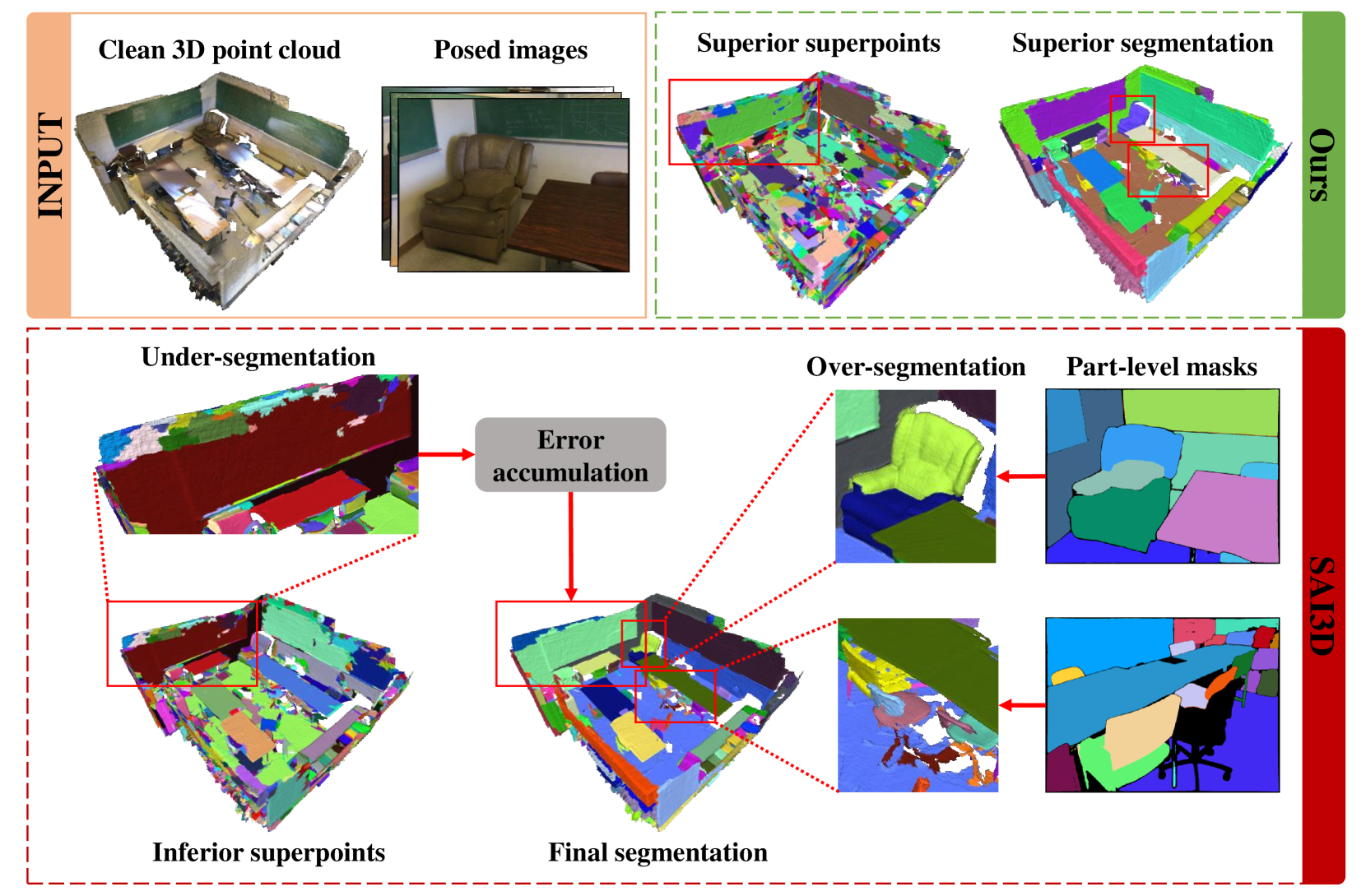
- 现有方法依赖二维分割模型和手工算法,易受二维分割误差影响,且对几何相似实例分割不足。
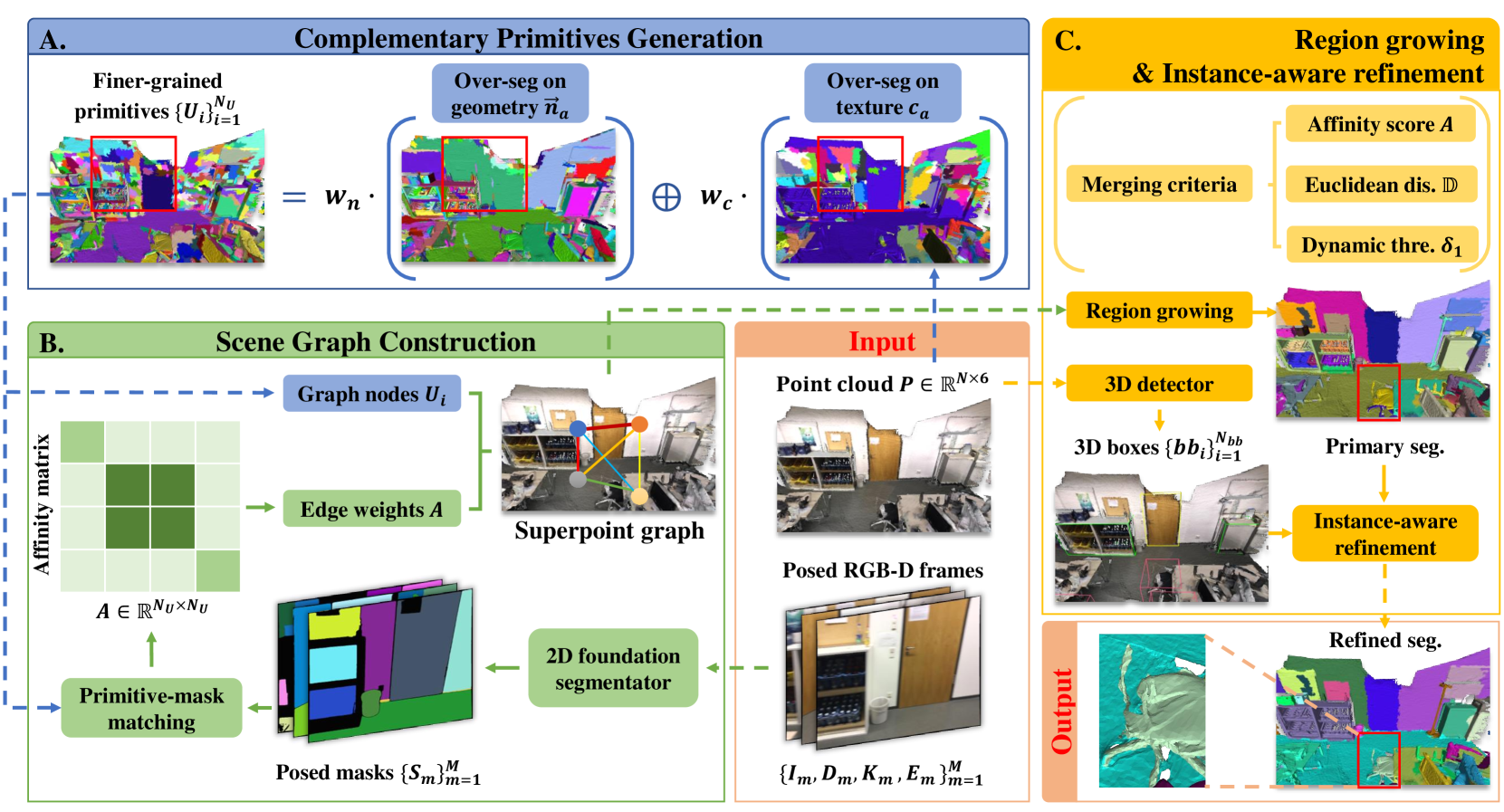
- SA3DIP利用几何和纹理先验生成互补的3D图元,并引入3D检测器约束,提升分割精度。
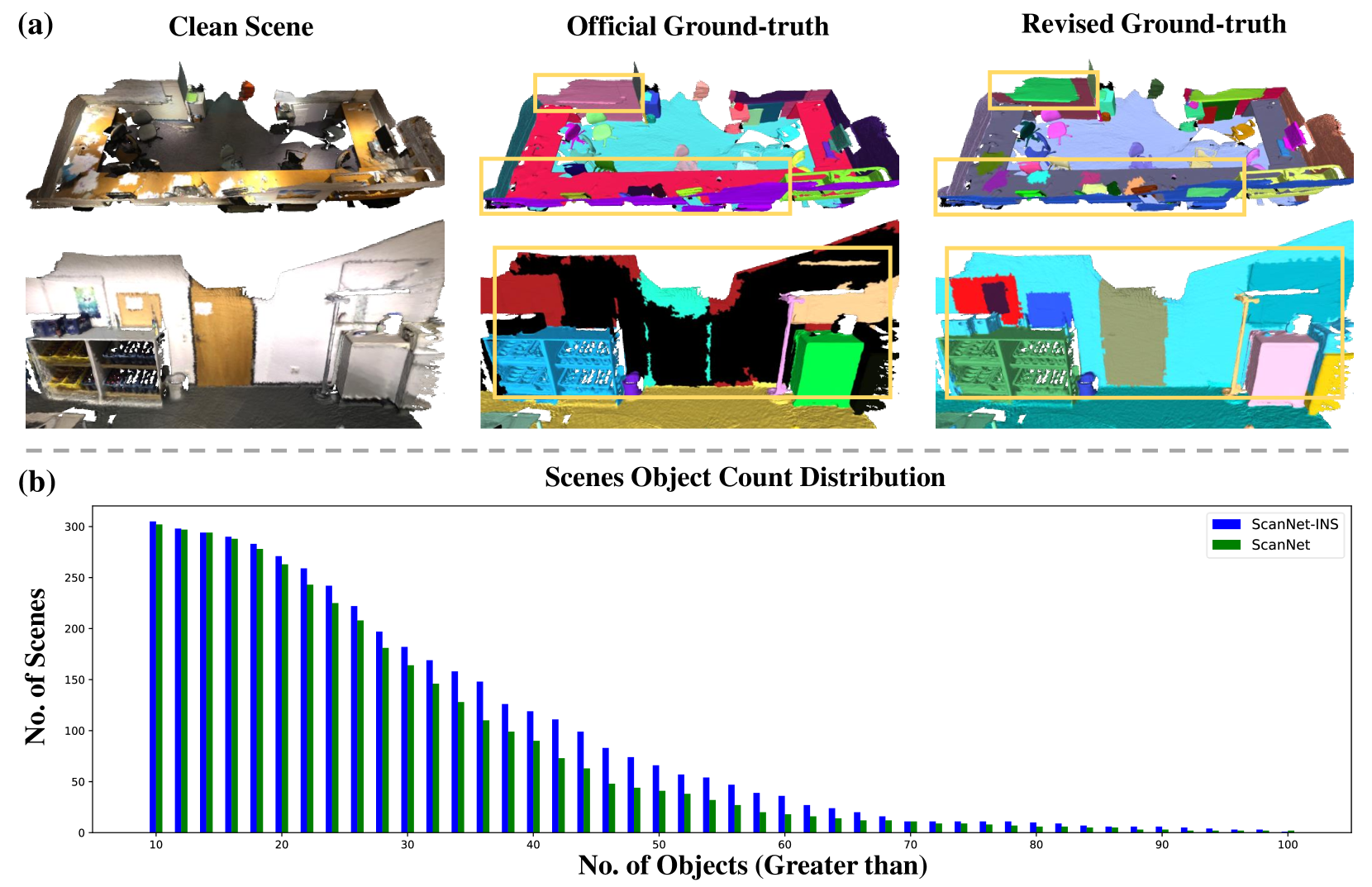
- 提出的ScanNetV2-INS数据集包含更完整的标注,实验证明SA3DIP在多个数据集上表现出色。
📝 摘要(中文)
二维基础模型的普及激发了将其应用于开放世界三维实例分割的研究。现有方法采用超点作为几何图元,并结合来自Segment Anything Model (SAM)的二维多视角掩码作为合并指导,实现了出色的零样本实例分割结果。然而,三维先验的有限使用限制了分割性能。先前方法仅基于空间坐标估计的法线计算三维超点,导致几何形状相似的实例分割不足。此外,过度依赖SAM和手工设计的二维算法,由于SAM固有的部分级分割倾向,导致过度分割。为了解决这些问题,我们提出了一种新颖的方法SA3DIP,通过利用潜在的三维先验来分割任意三维实例。具体而言,一方面,我们基于几何和纹理先验生成互补的三维图元,从而减少了后续过程中累积的初始误差。另一方面,我们通过使用三维检测器引导进一步的合并过程,引入了来自三维空间的补充约束。此外,我们注意到ScanNetV2基准测试中存在相当一部分低质量的ground truth标注,这影响了公平评估。因此,我们提出了ScanNetV2-INS,其中包含完整ground truth标签,并为三维类无关实例分割补充了额外的实例。在各种2D-3D数据集上的实验评估证明了我们方法的有效性和鲁棒性。我们的代码和提出的ScanNetV2-INS数据集在此处可用。
🔬 方法详解
问题定义:现有方法在开放世界3D实例分割中,过度依赖2D基础模型(如SAM)提供的多视角分割信息,并以超点作为几何图元。这种方法存在两个主要痛点:一是3D先验信息利用不足,仅依赖空间坐标计算法线来生成超点,导致几何相似的实例分割不足;二是过度依赖SAM的2D分割结果,SAM倾向于进行部分级分割,导致3D实例的过度分割。
核心思路:SA3DIP的核心思路是更充分地利用3D空间中的先验信息,以弥补现有方法对2D信息的过度依赖。具体来说,它通过引入基于几何和纹理的互补3D图元生成方式,以及利用3D检测器进行约束的合并策略,来提高3D实例分割的准确性和鲁棒性。
技术框架:SA3DIP的整体框架包含以下几个主要阶段:1) 互补3D图元生成:基于几何和纹理信息生成初始的3D超点。2) 2D多视角掩码融合:利用SAM生成的多视角掩码信息,对初始超点进行初步合并。3) 3D检测器约束的合并:使用3D目标检测器预测的3D bounding box作为约束,进一步合并超点,减少过度分割。
关键创新:SA3DIP的关键创新在于:1) 互补3D图元生成:不仅仅依赖几何信息,还引入了纹理信息,生成更鲁棒的3D超点,减少初始分割误差。2) 3D检测器约束的合并:利用3D检测器提供的全局信息,对超点进行更准确的合并,有效抑制了SAM导致的过度分割问题。
关键设计:在互补3D图元生成阶段,论文可能采用了不同的特征提取网络来提取几何和纹理特征,并设计了相应的融合策略。在3D检测器约束的合并阶段,可能使用了基于IoU的匹配策略,将超点与检测到的3D bounding box进行关联,并根据关联程度进行合并。具体的损失函数设计和网络结构细节未知。
🖼️ 关键图片
📊 实验亮点
SA3DIP在多个2D-3D数据集上进行了实验验证,结果表明其性能优于现有方法。具体的性能提升数据未知,但论文强调了SA3DIP在解决几何相似实例分割不足和SAM过度分割问题上的有效性。此外,提出的ScanNetV2-INS数据集为3D实例分割研究提供了更可靠的评估基准。
🎯 应用场景
SA3DIP在机器人导航、自动驾驶、三维场景理解等领域具有广泛的应用前景。它可以帮助机器人更准确地识别和分割环境中的物体,从而实现更智能的交互和决策。此外,该技术还可以应用于三维重建、虚拟现实等领域,提升用户体验。
📄 摘要(原文)
The proliferation of 2D foundation models has sparked research into adapting them for open-world 3D instance segmentation. Recent methods introduce a paradigm that leverages superpoints as geometric primitives and incorporates 2D multi-view masks from Segment Anything model (SAM) as merging guidance, achieving outstanding zero-shot instance segmentation results. However, the limited use of 3D priors restricts the segmentation performance. Previous methods calculate the 3D superpoints solely based on estimated normal from spatial coordinates, resulting in under-segmentation for instances with similar geometry. Besides, the heavy reliance on SAM and hand-crafted algorithms in 2D space suffers from over-segmentation due to SAM's inherent part-level segmentation tendency. To address these issues, we propose SA3DIP, a novel method for Segmenting Any 3D Instances via exploiting potential 3D Priors. Specifically, on one hand, we generate complementary 3D primitives based on both geometric and textural priors, which reduces the initial errors that accumulate in subsequent procedures. On the other hand, we introduce supplemental constraints from the 3D space by using a 3D detector to guide a further merging process. Furthermore, we notice a considerable portion of low-quality ground truth annotations in ScanNetV2 benchmark, which affect the fair evaluations. Thus, we present ScanNetV2-INS with complete ground truth labels and supplement additional instances for 3D class-agnostic instance segmentation. Experimental evaluations on various 2D-3D datasets demonstrate the effectiveness and robustness of our approach. Our code and proposed ScanNetV2-INS dataset are available HERE.