GS2Pose: Two-stage 6D Object Pose Estimation Guided by Gaussian Splatting
作者: Jilan Mei, Junbo Li, Cai Meng
分类: cs.CV, cs.AI
发布日期: 2024-11-06 (更新: 2024-11-08)
💡 一句话要点
GS2Pose:利用高斯溅射引导的两阶段6D物体姿态估计
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 6D姿态估计 3D高斯溅射 可微渲染 新物体识别 机器人抓取
📋 核心要点
- 现有6D物体姿态估计方法依赖高质量CAD模型,限制了其在新物体上的应用,且对光照变化和遮挡等因素敏感。
- GS2Pose利用3D高斯溅射重建结果,无需CAD模型,并设计两阶段框架:粗略估计和基于可微渲染的精细优化。
- 实验表明,GS2Pose在LineMod数据集上取得了极具竞争力的结果,验证了其在新物体姿态估计上的有效性和鲁棒性。
📝 摘要(中文)
本文提出了一种名为GS2Pose的新方法,用于对新物体的进行精确和鲁棒的6D姿态估计。通过引入3D高斯溅射,GS2Pose可以利用重建结果,而无需高质量的CAD模型,这意味着它只需要分割的RGBD图像作为输入。具体来说,GS2Pose采用两阶段结构,包括粗略估计和精细估计。在粗略阶段,设计了一个带有极化注意力机制的轻量级U-Net网络,称为Pose-Net。通过使用3DGS模型进行监督训练,Pose-Net可以生成NOCS图像以计算粗略姿态。在精细阶段,GS2Pose遵循重投影或Bundle Adjustment (BA)的思想,构建了一种姿态回归算法,称为GS-Refiner。通过利用李代数扩展3DGS,GS-Refiner获得了一个姿态可微的渲染管线,通过比较输入图像和渲染图像来细化粗略姿态。GS-Refiner还选择性地更新3DGS模型中的参数,以实现环境适应,从而增强算法对光照变化、遮挡和其他具有挑战性的干扰因素的鲁棒性和灵活性。GS2Pose通过在LineMod数据集上进行的实验进行了评估,并与类似算法进行了比较,产生了极具竞争力的结果。GS2Pose的代码将很快在GitHub上发布。
🔬 方法详解
问题定义:论文旨在解决新物体的精确6D姿态估计问题。现有方法通常依赖于高质量的CAD模型,这限制了它们在实际应用中的泛化能力,尤其是在处理未见过的物体时。此外,现有方法在光照变化、遮挡等复杂场景下的鲁棒性也存在挑战。
核心思路:论文的核心思路是利用3D高斯溅射(3DGS)技术,从RGBD图像中重建物体的3D模型,从而避免对CAD模型的依赖。然后,通过两阶段的姿态估计框架,先进行粗略估计,再通过可微渲染进行精细优化,提高姿态估计的精度和鲁棒性。
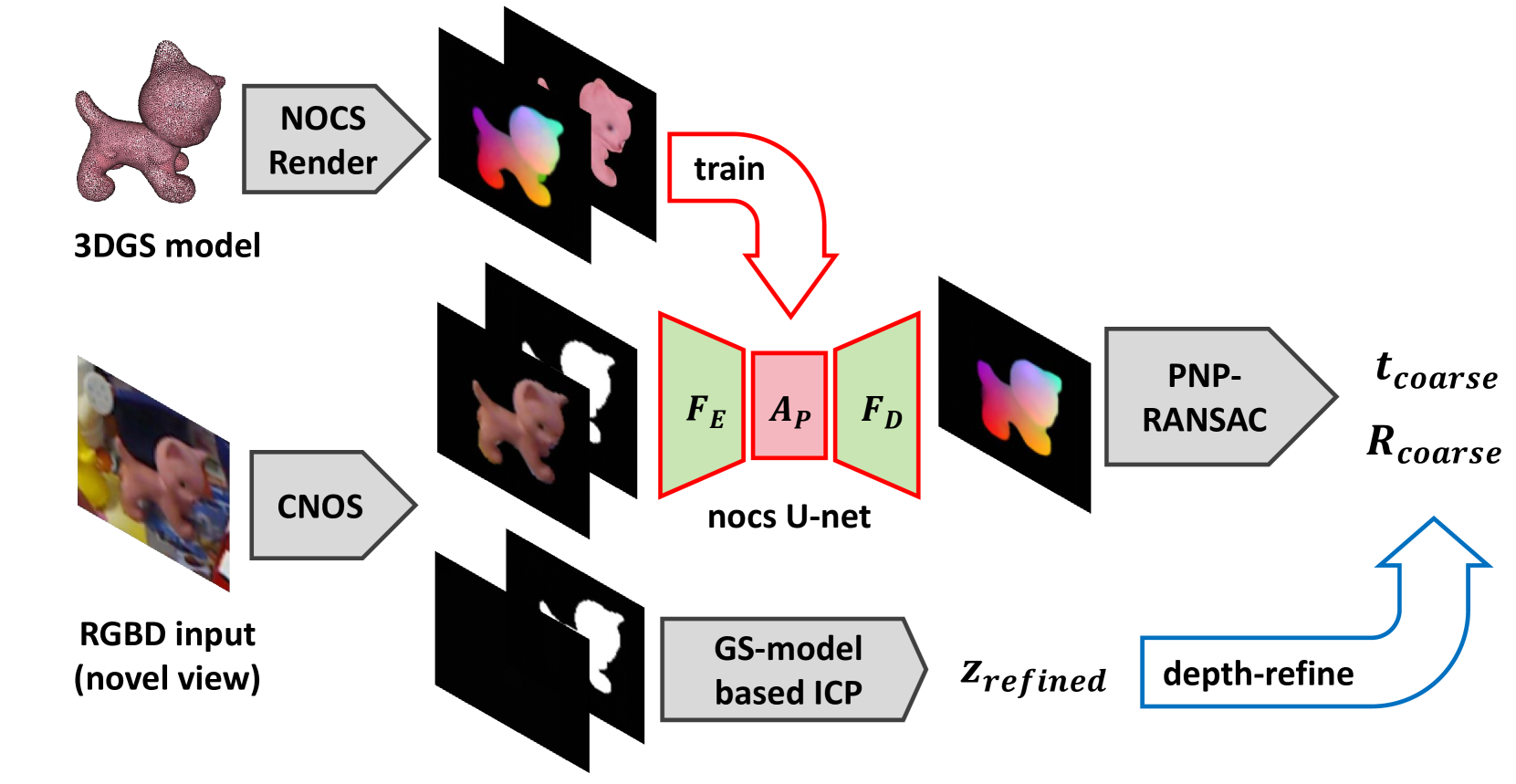
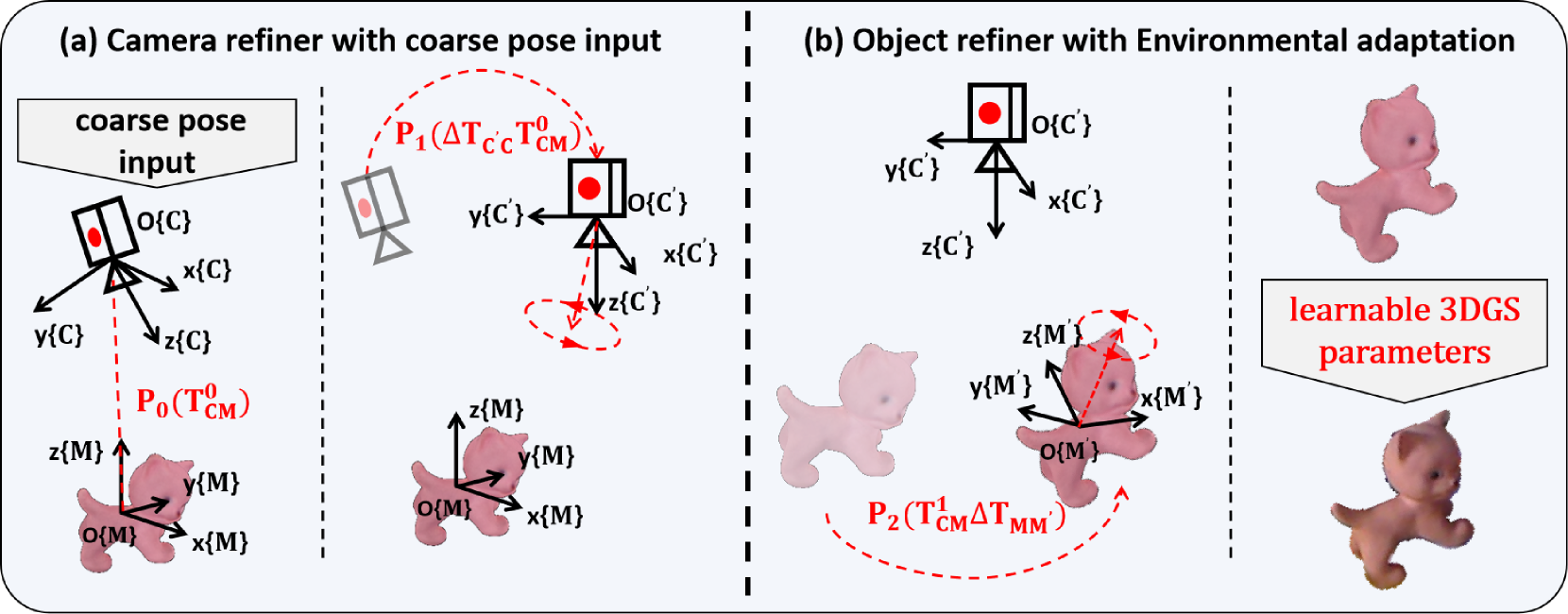
技术框架:GS2Pose包含两个主要阶段:1) 粗略姿态估计 (Pose-Net):使用一个轻量级的U-Net网络,结合极化注意力机制,从输入图像中预测NOCS图像,进而计算粗略的物体姿态。2) 精细姿态优化 (GS-Refiner):基于Bundle Adjustment的思想,构建一个可微渲染管线,通过比较输入图像和渲染图像之间的差异,利用李代数对姿态进行迭代优化。同时,GS-Refiner还选择性地更新3DGS模型中的参数,以适应环境变化。
关键创新:该方法的主要创新在于:1) 无需CAD模型:利用3DGS技术,摆脱了对CAD模型的依赖,使其能够处理新物体的姿态估计问题。2) 可微渲染优化:通过构建可微渲染管线,实现了端到端的姿态优化,提高了姿态估计的精度。3) 环境自适应:通过选择性地更新3DGS模型参数,增强了算法对光照变化和遮挡等因素的鲁棒性。
关键设计:Pose-Net采用了轻量级的U-Net结构,并引入了极化注意力机制,以提高特征提取的效率和准确性。GS-Refiner使用李代数来表示姿态变换,并构建了可微渲染损失函数,用于优化姿态参数。此外,GS-Refiner还设计了一种选择性参数更新策略,用于更新3DGS模型中的颜色和不透明度等参数,以适应环境变化。
🖼️ 关键图片

📊 实验亮点
GS2Pose在LineMod数据集上进行了评估,并与现有算法进行了比较,取得了极具竞争力的结果。具体性能数据未知,但摘要强调了其结果“highly competitive”,表明该方法在精度和鲁棒性方面具有显著优势。该方法通过引入3DGS和可微渲染,有效提升了新物体姿态估计的性能。
🎯 应用场景
GS2Pose在机器人抓取、增强现实、自动驾驶等领域具有广泛的应用前景。该方法无需CAD模型,能够处理新物体的姿态估计,使其能够应用于更广泛的场景。通过提高姿态估计的精度和鲁棒性,可以提升机器人操作的可靠性和效率,增强AR/VR应用的沉浸感,并为自动驾驶系统提供更准确的环境感知。
📄 摘要(原文)
This paper proposes a new method for accurate and robust 6D pose estimation of novel objects, named GS2Pose. By introducing 3D Gaussian splatting, GS2Pose can utilize the reconstruction results without requiring a high-quality CAD model, which means it only requires segmented RGBD images as input. Specifically, GS2Pose employs a two-stage structure consisting of coarse estimation followed by refined estimation. In the coarse stage, a lightweight U-Net network with a polarization attention mechanism, called Pose-Net, is designed. By using the 3DGS model for supervised training, Pose-Net can generate NOCS images to compute a coarse pose. In the refinement stage, GS2Pose formulates a pose regression algorithm following the idea of reprojection or Bundle Adjustment (BA), referred to as GS-Refiner. By leveraging Lie algebra to extend 3DGS, GS-Refiner obtains a pose-differentiable rendering pipeline that refines the coarse pose by comparing the input images with the rendered images. GS-Refiner also selectively updates parameters in the 3DGS model to achieve environmental adaptation, thereby enhancing the algorithm's robustness and flexibility to illuminative variation, occlusion, and other challenging disruptive factors. GS2Pose was evaluated through experiments conducted on the LineMod dataset, where it was compared with similar algorithms, yielding highly competitive results. The code for GS2Pose will soon be released on GitHub.