StreamingBench: Assessing the Gap for MLLMs to Achieve Streaming Video Understanding
作者: Junming Lin, Zheng Fang, Chi Chen, Zihao Wan, Fuwen Luo, Peng Li, Yang Liu, Maosong Sun
分类: cs.CV, cs.AI
发布日期: 2024-11-06
💡 一句话要点
StreamingBench:评估MLLM在流视频理解能力上与人类的差距
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 流视频理解 多模态大语言模型 实时视频分析 基准测试 上下文理解
📋 核心要点
- 现有MLLM主要集中于离线视频理解,需要预先处理所有帧,无法像人类一样实时理解和响应流式视频。
- StreamingBench旨在评估MLLM在实时视觉理解、全源理解和上下文理解三个方面的流视频理解能力。
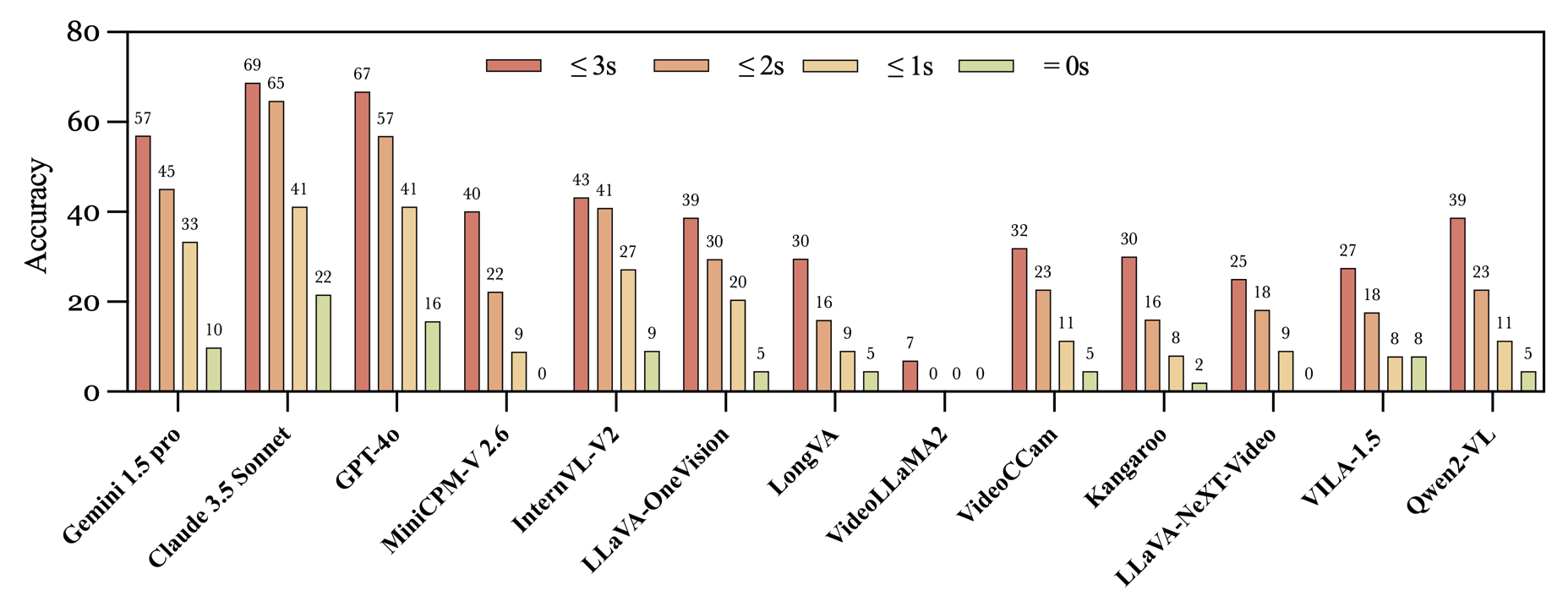
- 实验表明,即使是Gemini 1.5 Pro和GPT-4o等先进MLLM,其流视频理解能力也远低于人类水平。
📝 摘要(中文)
多模态大型语言模型(MLLM)的快速发展使其能力从图像理解扩展到视频理解。然而,大多数MLLM主要关注离线视频理解,需要在进行任何查询之前对所有视频帧进行广泛处理。这与人类实时观看、收听、思考和响应流式输入的能力存在显著差距,突显了当前MLLM的局限性。本文提出了StreamingBench,这是第一个旨在评估MLLM流视频理解能力的综合基准。StreamingBench评估流视频理解的三个核心方面:(1)实时视觉理解,(2)全源理解,(3)上下文理解。该基准包含18个任务,900个视频和4,500个人工标注的问答对。每个视频包含五个在不同时间点提出的问题,以模拟连续流式场景。我们使用13个开源和专有MLLM在StreamingBench上进行了实验,发现即使是最先进的专有MLLM,如Gemini 1.5 Pro和GPT-4o,其流视频理解能力也远低于人类水平。我们希望我们的工作能够促进MLLM的进一步发展,使其能够在更真实的场景中接近人类水平的视频理解和交互。
🔬 方法详解
问题定义:当前的多模态大型语言模型(MLLM)在视频理解方面主要集中于离线处理,即需要完整读取整个视频后才能进行分析和问答。这种方式无法模拟人类实时理解和响应流式视频的能力,例如观看直播、参与实时对话等。现有方法的痛点在于缺乏对实时性和上下文信息的有效利用,导致在流式视频场景下的性能显著下降。
核心思路:StreamingBench的核心思路是构建一个能够模拟真实流式视频场景的评测基准,通过在不同时间点提出问题,考察MLLM在实时视觉理解、全源理解(例如结合音频信息)和上下文理解方面的能力。通过这种方式,可以更全面地评估MLLM在处理流式视频时的性能瓶颈,并推动相关技术的发展。
技术框架:StreamingBench包含18个任务,涵盖了不同的流式视频理解场景。每个任务包含多个视频,每个视频配有5个在不同时间点提出的问题,模拟连续的流式输入。整个评测流程如下:1. 输入流式视频片段;2. MLLM根据已接收到的视频信息回答当前时间点的问题;3. 记录MLLM的回答,并与人工标注的答案进行比较,评估其性能。
关键创新:StreamingBench的关键创新在于其对流式视频理解的全面评估。它不仅关注视觉信息,还考虑了音频等多模态信息,以及上下文信息的利用。此外,通过在不同时间点提出问题,可以更真实地模拟流式视频场景,从而更准确地评估MLLM的实时理解能力。这是首个专门针对MLLM流视频理解能力的综合性基准。
关键设计:StreamingBench包含900个视频和4,500个人工标注的问答对。视频内容涵盖了各种场景,例如日常生活、体育赛事、新闻报道等。问题设计旨在考察MLLM在不同方面的理解能力,例如目标识别、事件描述、因果推理等。具体的技术细节,例如视频编码格式、音频采样率等,论文中未详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,即使是Gemini 1.5 Pro和GPT-4o等最先进的专有MLLM,在StreamingBench上的表现也远低于人类水平。这突显了当前MLLM在流视频理解方面存在的巨大差距。该研究为未来的研究方向提供了重要的参考,并为开发更强大的流视频理解模型奠定了基础。
🎯 应用场景
该研究成果可应用于实时视频监控、智能客服、直播互动、自动驾驶等领域。通过提升MLLM在流视频理解方面的能力,可以实现更智能、更自然的视频交互体验。例如,在直播场景中,MLLM可以实时分析视频内容,并根据用户提问提供个性化解答;在自动驾驶中,MLLM可以实时感知周围环境,并做出相应的决策。
📄 摘要(原文)
The rapid development of Multimodal Large Language Models (MLLMs) has expanded their capabilities from image comprehension to video understanding. However, most of these MLLMs focus primarily on offline video comprehension, necessitating extensive processing of all video frames before any queries can be made. This presents a significant gap compared to the human ability to watch, listen, think, and respond to streaming inputs in real time, highlighting the limitations of current MLLMs. In this paper, we introduce StreamingBench, the first comprehensive benchmark designed to evaluate the streaming video understanding capabilities of MLLMs. StreamingBench assesses three core aspects of streaming video understanding: (1) real-time visual understanding, (2) omni-source understanding, and (3) contextual understanding. The benchmark consists of 18 tasks, featuring 900 videos and 4,500 human-curated QA pairs. Each video features five questions presented at different time points to simulate a continuous streaming scenario. We conduct experiments on StreamingBench with 13 open-source and proprietary MLLMs and find that even the most advanced proprietary MLLMs like Gemini 1.5 Pro and GPT-4o perform significantly below human-level streaming video understanding capabilities. We hope our work can facilitate further advancements for MLLMs, empowering them to approach human-level video comprehension and interaction in more realistic scenarios.