Personalized Video Summarization by Multimodal Video Understanding
作者: Brian Chen, Xiangyuan Zhao, Yingnan Zhu
分类: cs.CV, cs.AI
发布日期: 2024-11-05
备注: In Proceedings of CIKM 2024 Applied Research Track
期刊: 33rd ACM International Conference on Information and Knowledge Management (CIKM 2024)
💡 一句话要点
提出基于多模态视频理解的个性化视频摘要方法,提升用户体验。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频摘要 个性化推荐 视觉语言模型 多模态理解 用户偏好 无监督学习 视频理解
📋 核心要点
- 现有视频摘要方法缺乏对用户偏好的有效建模,且依赖大量标注数据,泛化性不足。
- 论文提出基于预训练视觉语言模型的VSL pipeline,将视频帧转换为文本,并根据用户偏好选择相关场景。
- 实验表明,该方法优于现有无监督方法,且在不同数据集上表现出更好的适应性,更适合实际应用。
📝 摘要(中文)
视频摘要技术已被证明可以改善用户在访问和理解视频内容时的整体体验。如果已知用户的偏好,视频摘要可以从输入视频中识别重要的信息或相关内容,帮助他们获得必要的信息或确定他们是否有兴趣观看原始视频。为了使视频摘要适应各种类型的视频和用户偏好,需要大量的训练数据和昂贵的人工标注。为了促进此类研究,我们提出了一个新的视频摘要基准,该基准捕捉了各种用户偏好。此外,我们提出了一种名为“基于语言的视频摘要(VSL)”的pipeline,用于用户偏好的视频摘要,该pipeline基于预训练的视觉语言模型(VLMs),避免了在大型训练数据集上训练视频摘要系统的需求。该pipeline以视频和封闭字幕作为输入,并通过将视频帧转换为文本,在场景级别执行语义分析。随后,用户的类型偏好被用作选择相关文本场景的基础。实验结果表明,我们提出的pipeline优于当前最先进的无监督视频摘要模型。我们表明,与有监督的基于查询的视频摘要模型相比,我们的方法在不同的数据集上更具适应性。最后,运行时分析表明,当扩展用户偏好和视频的数量时,我们的pipeline更适合实际使用。
🔬 方法详解
问题定义:现有视频摘要方法通常缺乏对用户个性化偏好的考虑,难以生成满足不同用户需求的摘要。此外,许多方法依赖于大量的标注数据进行训练,这限制了它们在实际应用中的可扩展性和泛化能力。因此,如何有效地利用少量数据或无监督的方式,生成符合用户个性化偏好的视频摘要是一个重要的挑战。
核心思路:论文的核心思路是利用预训练的视觉语言模型(VLMs)的强大语义理解能力,将视频内容转换为文本表示,然后根据用户的偏好,从文本表示中选择相关的场景。这种方法避免了直接在视频数据上进行训练,从而减少了对大量标注数据的依赖。同时,通过将用户偏好融入到场景选择的过程中,实现了个性化的视频摘要。
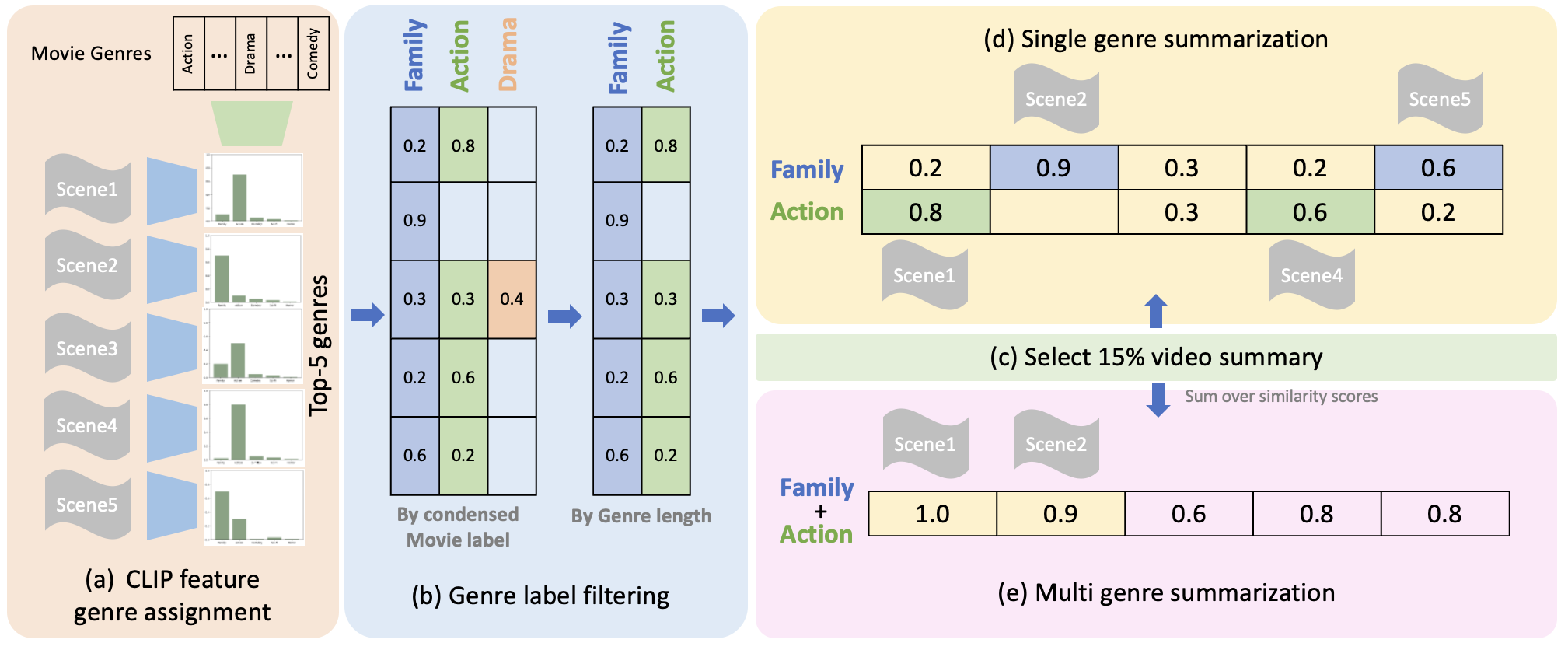
技术框架:VSL pipeline主要包含以下几个阶段:1) 视频和字幕输入:pipeline接收视频及其对应的封闭字幕作为输入。2) 场景级别语义分析:利用VLMs将视频帧转换为文本描述,从而在场景级别进行语义分析。3) 用户偏好场景选择:根据用户的类型偏好,从文本描述中选择相关的场景。4) 视频摘要生成:将选择的场景组合成最终的视频摘要。
关键创新:该方法最重要的创新点在于利用预训练的视觉语言模型进行视频理解和摘要生成,避免了对大量标注数据的依赖。此外,该方法通过将用户偏好融入到场景选择的过程中,实现了个性化的视频摘要。与传统的视频摘要方法相比,该方法更具灵活性和可扩展性。
关键设计:在场景级别语义分析阶段,论文使用了预训练的VLMs将视频帧转换为文本描述。具体来说,可以将每一帧图像输入到VLM中,得到对应的文本描述。然后,可以将相邻的帧的文本描述进行聚合,形成场景级别的文本表示。在用户偏好场景选择阶段,论文使用了用户的类型偏好作为选择相关场景的基础。具体来说,可以将用户的类型偏好表示为一个文本查询,然后使用文本相似度度量来选择与查询最相关的场景。
🖼️ 关键图片


📊 实验亮点
实验结果表明,提出的VSL pipeline在视频摘要任务上优于当前最先进的无监督模型。与有监督的基于查询的视频摘要模型相比,该方法在不同数据集上表现出更好的适应性。运行时分析表明,当扩展用户偏好和视频的数量时,该pipeline更适合实际使用。具体性能数据未知,但结论表明该方法具有显著优势。
🎯 应用场景
该研究成果可应用于各种视频平台,如短视频APP、在线教育平台、新闻媒体等,为用户提供个性化的视频摘要服务,帮助用户快速了解视频内容,节省时间,提升用户体验。此外,该技术还可应用于智能监控、视频检索等领域,提高视频处理的效率和准确性。
📄 摘要(原文)
Video summarization techniques have been proven to improve the overall user experience when it comes to accessing and comprehending video content. If the user's preference is known, video summarization can identify significant information or relevant content from an input video, aiding them in obtaining the necessary information or determining their interest in watching the original video. Adapting video summarization to various types of video and user preferences requires significant training data and expensive human labeling. To facilitate such research, we proposed a new benchmark for video summarization that captures various user preferences. Also, we present a pipeline called Video Summarization with Language (VSL) for user-preferred video summarization that is based on pre-trained visual language models (VLMs) to avoid the need to train a video summarization system on a large training dataset. The pipeline takes both video and closed captioning as input and performs semantic analysis at the scene level by converting video frames into text. Subsequently, the user's genre preference was used as the basis for selecting the pertinent textual scenes. The experimental results demonstrate that our proposed pipeline outperforms current state-of-the-art unsupervised video summarization models. We show that our method is more adaptable across different datasets compared to supervised query-based video summarization models. In the end, the runtime analysis demonstrates that our pipeline is more suitable for practical use when scaling up the number of user preferences and videos.