CRT-Fusion: Camera, Radar, Temporal Fusion Using Motion Information for 3D Object Detection
作者: Jisong Kim, Minjae Seong, Jun Won Choi
分类: cs.CV
发布日期: 2024-11-05 (更新: 2024-12-11)
备注: Accepted at NeurIPS2024
💡 一句话要点
CRT-Fusion:融合相机、雷达和时序信息的3D目标检测方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D目标检测 雷达相机融合 时序融合 运动估计 自动驾驶
📋 核心要点
- 现有雷达-相机融合方法难以有效捕捉动态物体的运动信息,导致在复杂场景下的3D目标检测性能受限。
- CRT-Fusion通过多视图融合、运动特征估计和运动引导时序融合,将时序信息融入雷达-相机融合中,提升动态目标检测能力。
- 在nuScenes数据集上,CRT-Fusion在NDS指标上提升1.7%,在mAP指标上提升1.4%,达到了state-of-the-art的性能。
📝 摘要(中文)
精确且鲁棒的3D目标检测是自动驾驶车辆和机器人技术的关键组成部分。虽然最近的雷达-相机融合方法通过在鸟瞰图(BEV)表示中融合信息取得了显著进展,但它们通常难以有效地捕捉动态物体的运动,导致在实际场景中的性能受限。本文提出了CRT-Fusion,一种将时间信息集成到雷达-相机融合中的新框架,以应对这一挑战。我们的方法包括三个关键模块:多视图融合(MVF)、运动特征估计器(MFE)和运动引导时序融合(MGTF)。MVF模块在相机视图和鸟瞰视图中融合雷达和图像特征,从而生成更精确的统一BEV表示。MFE模块同时执行两项任务:像素级速度信息估计和BEV分割。基于从MFE模块获得的速度和占用率得分图,MGTF模块以循环方式对齐和融合多个时间戳的特征图。通过考虑动态物体的运动,CRT-Fusion可以生成鲁棒的BEV特征图,从而提高检测精度和鲁棒性。在具有挑战性的nuScenes数据集上的大量评估表明,CRT-Fusion在基于雷达-相机的3D目标检测方面实现了最先进的性能。我们的方法在NDS方面比之前的最佳方法高出+1.7%,同时在mAP方面也超过了领先的方法+1.4%。这些指标的显著改进表明了我们提出的融合策略在提高3D目标检测的可靠性和准确性方面的有效性。
🔬 方法详解
问题定义:现有雷达-相机融合的3D目标检测方法,在处理动态场景时,由于缺乏对目标运动信息的有效建模,导致检测精度和鲁棒性下降。尤其是在遮挡、光照变化等复杂环境下,静态融合策略难以准确识别和定位运动目标。
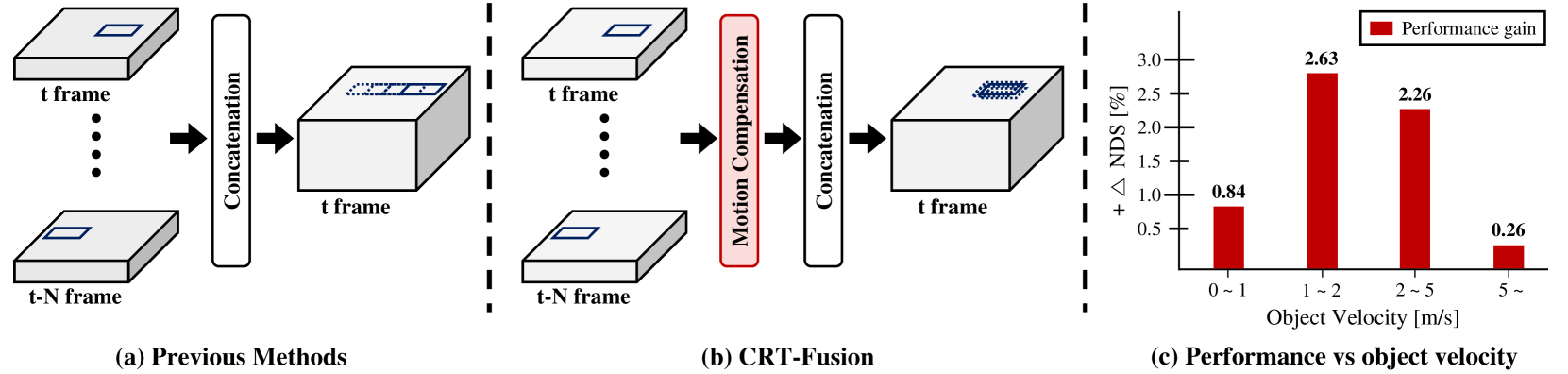
核心思路:CRT-Fusion的核心思路是利用时序信息,显式地建模目标的运动状态,从而提升动态场景下的3D目标检测性能。通过运动特征估计和运动引导的时序融合,将过去的信息融入到当前帧的特征表示中,增强对运动目标的感知能力。
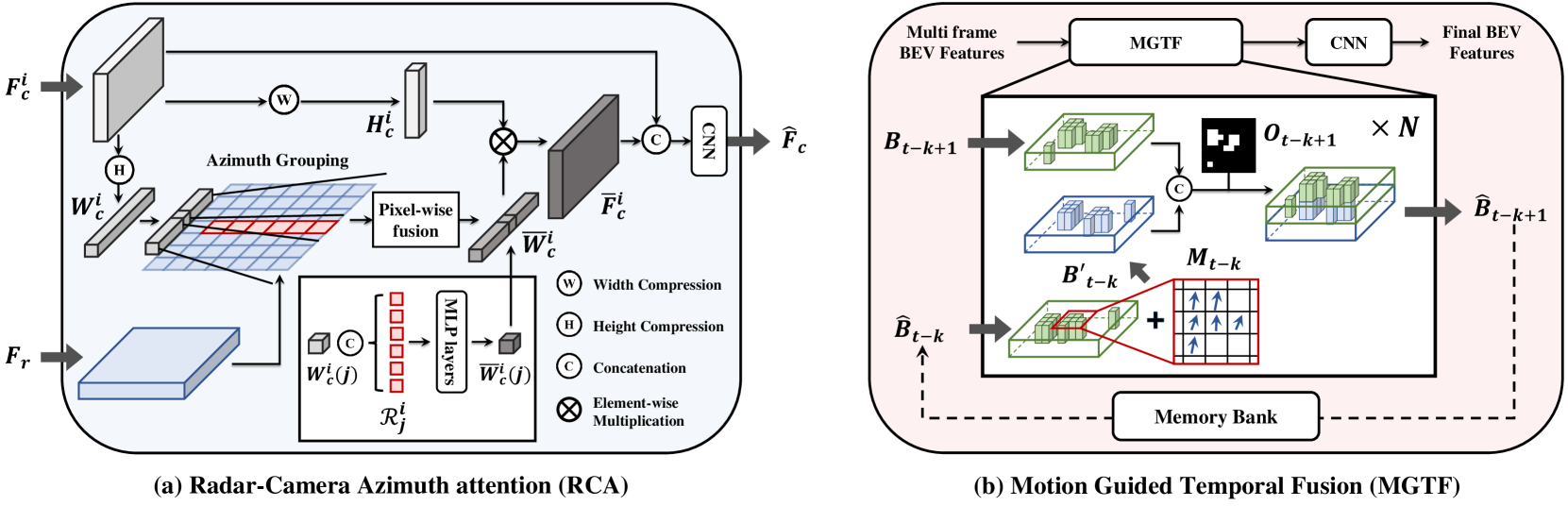
技术框架:CRT-Fusion框架包含三个主要模块:多视图融合(MVF)、运动特征估计器(MFE)和运动引导时序融合(MGTF)。MVF模块负责融合雷达和相机在不同视角下的特征,生成统一的BEV表示。MFE模块估计像素级的速度信息和BEV分割结果,为后续的时序融合提供运动先验。MGTF模块基于MFE模块的输出,对齐并融合不同时间戳的特征图,最终生成鲁棒的BEV特征图。
关键创新:CRT-Fusion的关键创新在于运动引导的时序融合机制。传统的时序融合方法通常采用简单的特征拼接或平均,忽略了目标在不同时间戳之间的运动关系。CRT-Fusion通过MFE模块估计的运动信息,对齐不同时间戳的特征图,从而更有效地融合时序信息,提升对动态目标的感知能力。
关键设计:MFE模块同时进行像素级速度估计和BEV分割,采用多任务学习的方式,共享底层特征,提高效率。MGTF模块采用循环神经网络(RNN)结构,以循环的方式融合时序信息,能够有效地捕捉目标的长期运动轨迹。损失函数方面,采用了针对3D目标检测的常用损失函数,并针对运动估计和分割任务添加了额外的损失项。
🖼️ 关键图片

📊 实验亮点
CRT-Fusion在nuScenes数据集上取得了显著的性能提升。在NDS指标上,CRT-Fusion比之前的最佳方法高出1.7%,达到了新的state-of-the-art水平。同时,在mAP指标上,CRT-Fusion也超过了领先的方法1.4%。这些结果表明,CRT-Fusion在动态场景下的3D目标检测方面具有显著优势。
🎯 应用场景
CRT-Fusion技术可广泛应用于自动驾驶、机器人导航、智能交通等领域。通过提升动态场景下的3D目标检测精度和鲁棒性,可以提高自动驾驶车辆对行人、车辆等运动目标的感知能力,从而增强行驶安全性。该技术还可以应用于机器人导航,帮助机器人在复杂环境中更好地识别和避开障碍物。未来,该技术有望在智慧城市、智能安防等领域发挥重要作用。
📄 摘要(原文)
Accurate and robust 3D object detection is a critical component in autonomous vehicles and robotics. While recent radar-camera fusion methods have made significant progress by fusing information in the bird's-eye view (BEV) representation, they often struggle to effectively capture the motion of dynamic objects, leading to limited performance in real-world scenarios. In this paper, we introduce CRT-Fusion, a novel framework that integrates temporal information into radar-camera fusion to address this challenge. Our approach comprises three key modules: Multi-View Fusion (MVF), Motion Feature Estimator (MFE), and Motion Guided Temporal Fusion (MGTF). The MVF module fuses radar and image features within both the camera view and bird's-eye view, thereby generating a more precise unified BEV representation. The MFE module conducts two simultaneous tasks: estimation of pixel-wise velocity information and BEV segmentation. Based on the velocity and the occupancy score map obtained from the MFE module, the MGTF module aligns and fuses feature maps across multiple timestamps in a recurrent manner. By considering the motion of dynamic objects, CRT-Fusion can produce robust BEV feature maps, thereby improving detection accuracy and robustness. Extensive evaluations on the challenging nuScenes dataset demonstrate that CRT-Fusion achieves state-of-the-art performance for radar-camera-based 3D object detection. Our approach outperforms the previous best method in terms of NDS by +1.7%, while also surpassing the leading approach in mAP by +1.4%. These significant improvements in both metrics showcase the effectiveness of our proposed fusion strategy in enhancing the reliability and accuracy of 3D object detection.