CAD-NeRF: Learning NeRFs from Uncalibrated Few-view Images by CAD Model Retrieval
作者: Xin Wen, Xuening Zhu, Renjiao Yi, Zhifeng Wang, Chenyang Zhu, Kai Xu
分类: cs.CV
发布日期: 2024-11-05 (更新: 2025-05-05)
备注: The article has been accepted by Frontiers of Computer Science (FCS)
DOI: 10.1007/s11704-024-40417-7
💡 一句话要点
CAD-NeRF:利用CAD模型检索,从无标定少视图图像中学习NeRF
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 神经辐射场 NeRF 三维重建 少视图重建 无标定重建 CAD模型检索 位姿估计
📋 核心要点
- 现有NeRF方法通常需要精确的相机位姿或大量的输入图像,对无位姿少视图图像重建NeRF构成挑战。
- CAD-NeRF的核心思想是利用CAD模型库进行模型和位姿检索,为NeRF的训练提供密度监督和位姿初始化。
- 实验结果表明,CAD-NeRF能够从检索到的CAD模型中学习具有较大形变的精确密度,具有良好的泛化能力。
📝 摘要(中文)
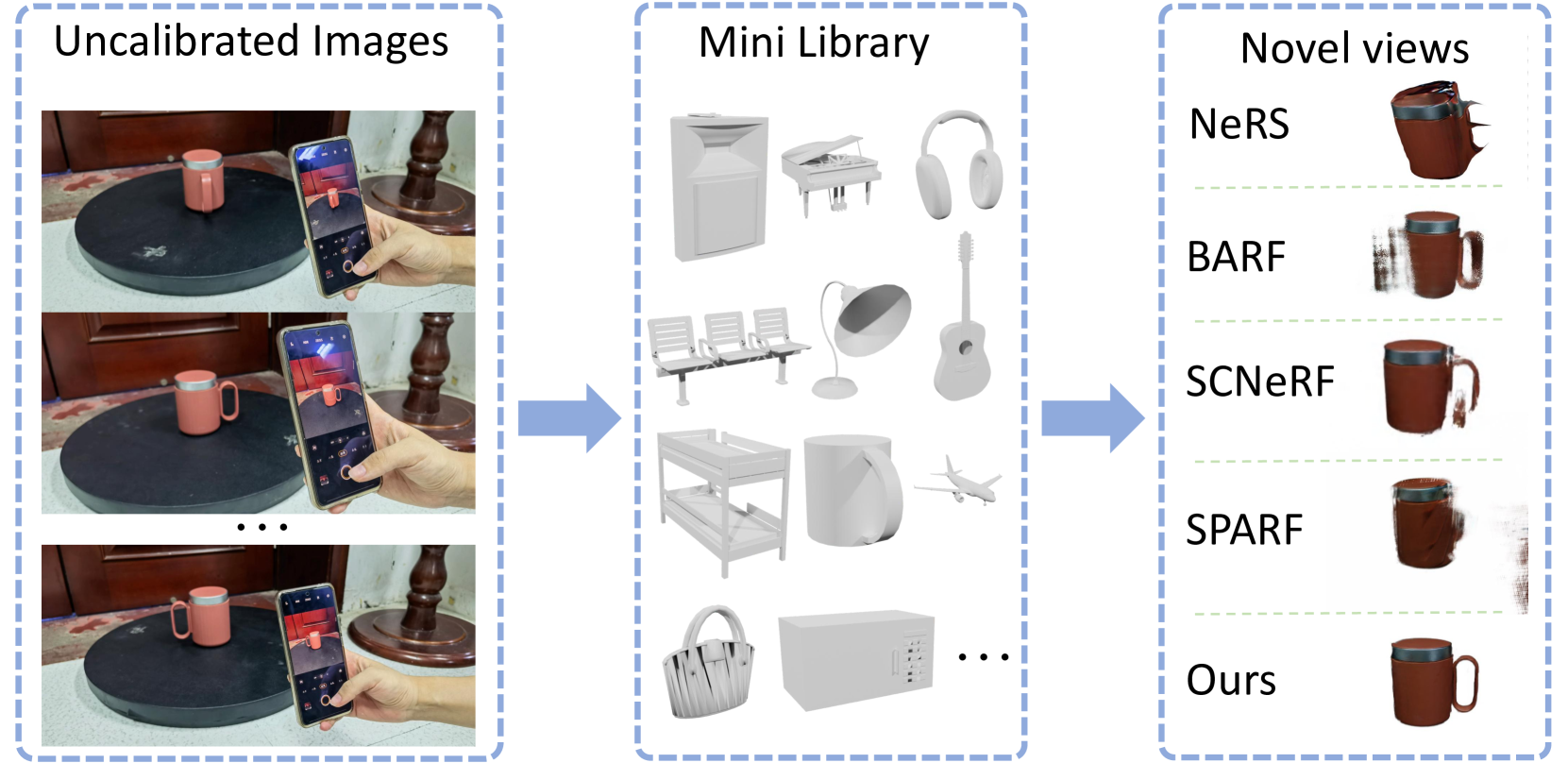
本文提出CAD-NeRF,一种从少于10张无相机位姿图像中重建神经辐射场(NeRF)的方法。针对无位姿少视图图像重建NeRF这一高度不适定问题,该方法首先构建一个ShapeNet CAD模型库,并从多个随机视角渲染这些模型。然后,通过模型和位姿检索,从库中找到与输入图像具有相似形状的模型,作为密度监督和位姿初始化。提出了一种多视图位姿检索方法,以避免视图之间的位姿冲突,这在无标定NeRF方法中是一个新问题。接下来,利用CAD引导训练物体的几何形状,并联合优化密度场的形变和相机位姿。最后,以自监督方式训练和微调纹理和密度。在合成和真实图像上的综合评估表明,CAD-NeRF能够成功地从检索到的CAD模型中学习具有较大形变的精确密度,展示了其泛化能力。
🔬 方法详解
问题定义:论文旨在解决从少量未标定的图像中重建NeRF的问题。现有NeRF方法要么需要精确的相机位姿,要么需要大量的输入图像,这限制了它们在实际场景中的应用。在缺乏相机位姿和图像数量有限的情况下,NeRF的重建变得非常困难,是一个高度不适定的问题。
核心思路:论文的核心思路是利用CAD模型库作为先验知识,通过检索与输入图像相似的CAD模型,为NeRF的训练提供几何形状和相机位姿的初始化。这种方法利用了CAD模型提供的形状信息,有效地约束了NeRF的解空间,从而提高了重建的准确性和鲁棒性。
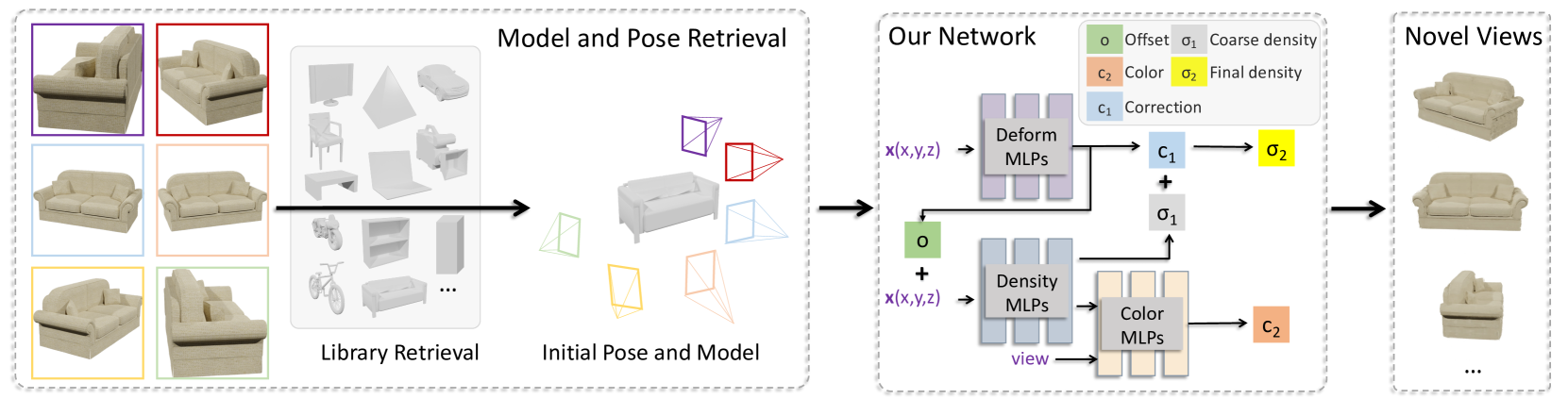
技术框架:CAD-NeRF的整体框架包括以下几个主要阶段:1) CAD模型库构建:从ShapeNet等数据集构建CAD模型库,并从多个随机视角渲染这些模型。2) 模型和位姿检索:给定稀疏视角的输入图像,从CAD模型库中检索形状相似的模型,并估计每个输入图像的相机位姿。3) NeRF训练:利用检索到的CAD模型作为密度监督,联合优化NeRF的几何形状、纹理和相机位姿。
关键创新:该方法最重要的创新点在于利用CAD模型检索来解决无标定少视图NeRF重建问题。具体来说,提出了多视图位姿检索方法,以避免视图之间的位姿冲突,这在以往的无标定NeRF方法中没有被考虑。此外,该方法还实现了密度场形变和相机位姿的联合优化,进一步提高了重建的精度。
关键设计:在模型检索阶段,使用了图像特征提取和相似度度量方法,例如使用预训练的卷积神经网络提取图像特征,并使用余弦相似度等度量方法计算图像之间的相似度。在NeRF训练阶段,使用了基于CAD模型的密度监督损失函数,以及相机位姿的正则化项。具体损失函数形式未知,但推测与检索到的CAD模型和估计的相机位姿相关。
🖼️ 关键图片

📊 实验亮点
论文在合成和真实图像上进行了综合评估,结果表明CAD-NeRF能够成功地从检索到的CAD模型中学习具有较大形变的精确密度。具体性能数据未知,但摘要强调了其泛化能力,表明该方法在不同场景和物体上都具有良好的表现。与现有方法相比,CAD-NeRF能够在更少的图像和更少的先验知识下实现高质量的NeRF重建。
🎯 应用场景
CAD-NeRF具有广泛的应用前景,例如在机器人导航、三维重建、虚拟现实和增强现实等领域。该方法可以用于从少量图像中重建场景的三维模型,从而为机器人提供环境感知能力,为用户提供沉浸式的虚拟现实体验。此外,该方法还可以用于文物保护和数字化,通过对少量照片进行处理,重建文物的三维模型。
📄 摘要(原文)
Reconstructing from multi-view images is a longstanding problem in 3D vision, where neural radiance fields (NeRFs) have shown great potential and get realistic rendered images of novel views. Currently, most NeRF methods either require accurate camera poses or a large number of input images, or even both. Reconstructing NeRF from few-view images without poses is challenging and highly ill-posed. To address this problem, we propose CAD-NeRF, a method reconstructed from less than 10 images without any known poses. Specifically, we build a mini library of several CAD models from ShapeNet and render them from many random views. Given sparse-view input images, we run a model and pose retrieval from the library, to get a model with similar shapes, serving as the density supervision and pose initializations. Here we propose a multi-view pose retrieval method to avoid pose conflicts among views, which is a new and unseen problem in uncalibrated NeRF methods. Then, the geometry of the object is trained by the CAD guidance. The deformation of the density field and camera poses are optimized jointly. Then texture and density are trained and fine-tuned as well. All training phases are in self-supervised manners. Comprehensive evaluations of synthetic and real images show that CAD-NeRF successfully learns accurate densities with a large deformation from retrieved CAD models, showing the generalization abilities.