LiVOS: Light Video Object Segmentation with Gated Linear Matching
作者: Qin Liu, Jianfeng Wang, Zhengyuan Yang, Linjie Li, Kevin Lin, Marc Niethammer, Lijuan Wang
分类: cs.CV
发布日期: 2024-11-05
备注: Code&models: https://github.com/uncbiag/LiVOS
💡 一句话要点
LiVOS:利用门控线性匹配实现轻量级视频目标分割
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频目标分割 半监督学习 线性注意力 轻量级网络 长视频处理
📋 核心要点
- 现有STM网络在处理长视频和高分辨率视频时,由于softmax注意力的二次复杂度,面临严重的内存限制。
- LiVOS通过线性注意力机制进行线性匹配,将记忆匹配转化为循环过程,显著降低了计算复杂度,从而减少内存占用。
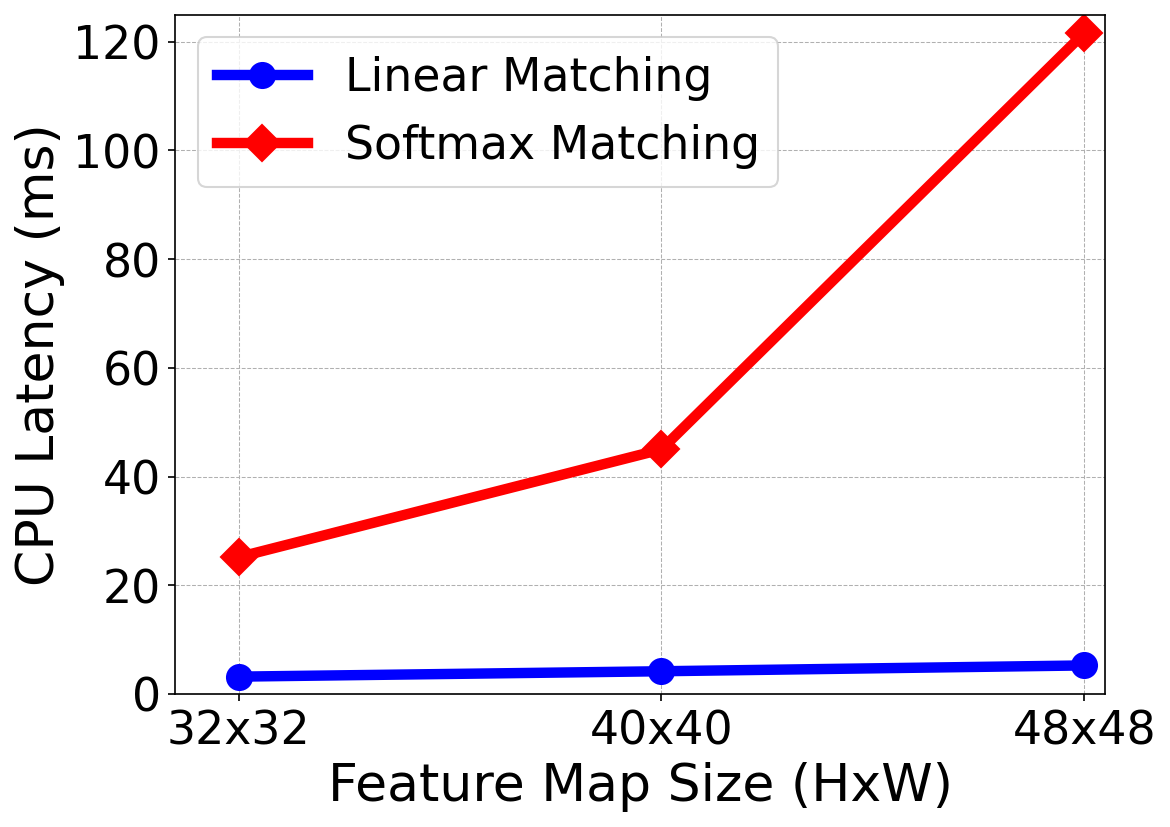
- 实验表明,LiVOS在性能上接近甚至匹配STM网络,同时显著降低了GPU内存需求,并支持更高分辨率的视频处理。
📝 摘要(中文)
半监督视频目标分割(VOS)主要由时空记忆(STM)网络驱动,该网络将过去的帧特征存储在时空记忆中,并通过softmax注意力机制分割当前帧。然而,由于softmax匹配的二次复杂度,STM网络面临内存限制,限制了它们在视频长度和分辨率增加时的适用性。为了解决这个问题,我们提出了LiVOS,一种轻量级记忆网络,它采用线性注意力进行线性匹配,将记忆匹配重新构建为一个循环过程,将二次注意力矩阵简化为一个恒定大小的、时空无关的2D状态。为了增强选择性,我们引入了门控线性匹配,其中数据相关的门矩阵与状态矩阵相乘,以控制保留或丢弃哪些信息。在各种基准测试上的实验证明了我们方法的有效性。它在MOSE上实现了64.8的J&F,在DAVIS上实现了85.1的J&F,超过了所有非STM方法,并缩小了与基于STM的方法的差距。对于更长和更高分辨率的视频,它与基于STM的方法相匹配,但GPU内存减少了53%,并支持在32G消费级GPU上进行4096p推理——这是一种以前成本高昂的能力——为长视频和高分辨率视频基础模型打开了大门。
🔬 方法详解
问题定义:半监督视频目标分割旨在给定视频第一帧的标注,自动分割视频后续帧中的目标。现有基于时空记忆(STM)的方法,虽然效果较好,但由于softmax注意力机制的二次复杂度,导致内存消耗巨大,难以处理长视频和高分辨率视频。
核心思路:LiVOS的核心思路是将复杂的时空记忆匹配过程,通过线性注意力机制转化为一个循环过程。通过线性匹配,将二次复杂度降低为常数级别,从而显著减少内存占用。同时,引入门控机制来增强特征选择性,提升分割精度。
技术框架:LiVOS主要包含特征提取、线性匹配和分割三个主要模块。首先,使用卷积神经网络提取视频帧的特征。然后,利用线性注意力机制进行记忆匹配,将过去帧的信息编码到一个固定大小的2D状态中。最后,利用该状态信息和当前帧的特征进行目标分割。整个过程是循环进行的,每一帧的分割结果都会更新记忆状态。
关键创新:LiVOS最重要的创新点在于使用线性注意力机制进行记忆匹配,从而避免了softmax注意力的二次复杂度问题。此外,门控线性匹配机制能够根据数据自适应地选择需要保留或丢弃的信息,进一步提升了分割性能。
关键设计:LiVOS使用线性注意力机制,将query和key的维度进行线性变换后直接相乘,避免了softmax操作。门控机制通过一个sigmoid函数生成门控矩阵,该矩阵与记忆状态相乘,控制信息的流动。损失函数采用标准的交叉熵损失函数,用于监督像素级别的分割结果。
🖼️ 关键图片


📊 实验亮点
LiVOS在MOSE数据集上取得了64.8的J&F,在DAVIS数据集上取得了85.1的J&F,超越了所有非STM方法。更重要的是,LiVOS在处理长视频和高分辨率视频时,与STM方法性能相当,但GPU内存占用减少了53%,并且能够在消费级GPU上进行4096p视频的推理。
🎯 应用场景
LiVOS在视频编辑、自动驾驶、视频监控等领域具有广泛的应用前景。它可以用于自动抠像、目标跟踪、异常行为检测等任务。由于其轻量级的特性,LiVOS尤其适用于资源受限的设备,例如移动设备和嵌入式系统。未来,LiVOS有望成为长视频和高分辨率视频分析的基础模型。
📄 摘要(原文)
Semi-supervised video object segmentation (VOS) has been largely driven by space-time memory (STM) networks, which store past frame features in a spatiotemporal memory to segment the current frame via softmax attention. However, STM networks face memory limitations due to the quadratic complexity of softmax matching, restricting their applicability as video length and resolution increase. To address this, we propose LiVOS, a lightweight memory network that employs linear matching via linear attention, reformulating memory matching into a recurrent process that reduces the quadratic attention matrix to a constant-size, spatiotemporal-agnostic 2D state. To enhance selectivity, we introduce gated linear matching, where a data-dependent gate matrix is multiplied with the state matrix to control what information to retain or discard. Experiments on diverse benchmarks demonstrated the effectiveness of our method. It achieved 64.8 J&F on MOSE and 85.1 J&F on DAVIS, surpassing all non-STM methods and narrowing the gap with STM-based approaches. For longer and higher-resolution videos, it matched STM-based methods with 53% less GPU memory and supports 4096p inference on a 32G consumer-grade GPU--a previously cost-prohibitive capability--opening the door for long and high-resolution video foundation models.