Multi-Transmotion: Pre-trained Model for Human Motion Prediction
作者: Yang Gao, Po-Chien Luan, Alexandre Alahi
分类: cs.CV, cs.RO
发布日期: 2024-11-04
备注: CoRL 2024
🔗 代码/项目: GITHUB
💡 一句话要点
Multi-Transmotion:用于人体运动预测的跨模态预训练模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人体运动预测 预训练模型 Transformer 跨模态学习 多数据集融合
📋 核心要点
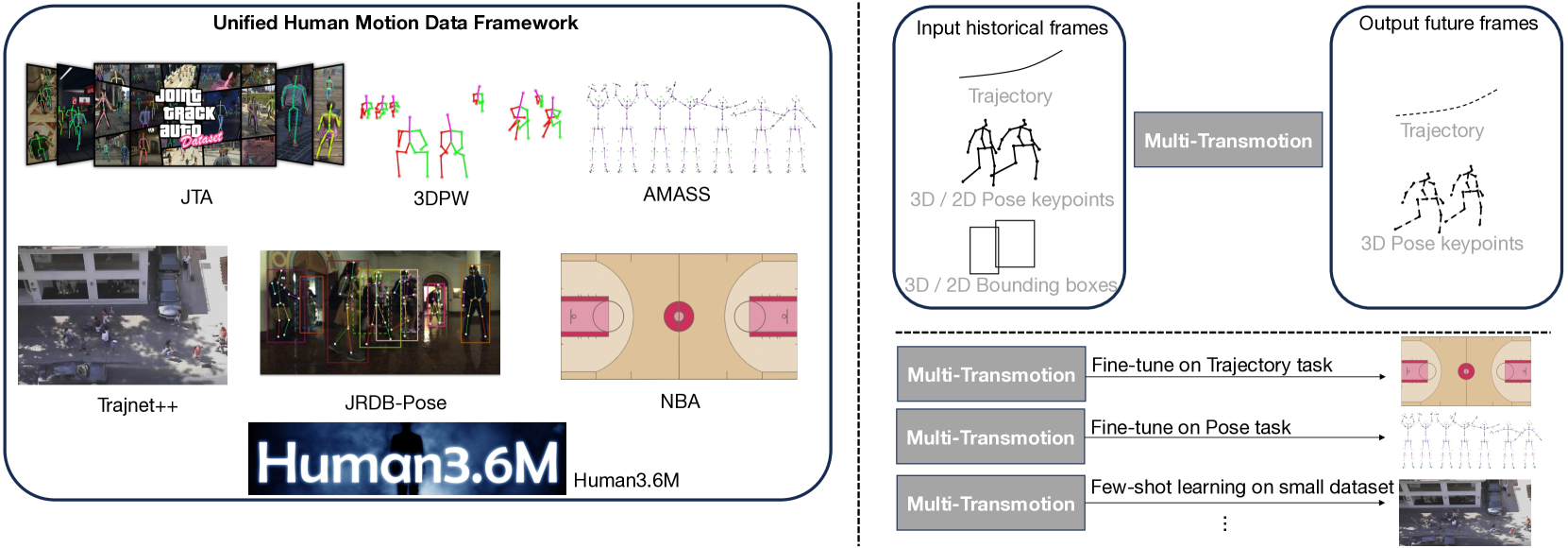
- 现有方法缺乏统一的人体运动预测数据集,难以进行有效的预训练。
- 论文提出Multi-Transmotion模型,通过整合多模态数据集进行跨模态预训练。
- 实验表明,该方法在轨迹和姿态预测等下游任务中取得了有竞争力的性能。
📝 摘要(中文)
智能系统预测人类行为的能力至关重要,尤其是在自动驾驶导航和社会机器人等领域。然而,人体运动的复杂性阻碍了人体运动预测标准化数据集的开发,从而妨碍了预训练模型的建立。本文通过整合包含轨迹和3D姿态关键点的多个数据集来解决这些限制,从而提出了用于人体运动预测的预训练模型。我们合并了跨不同模态的七个不同的数据集,并标准化了它们的格式。为了促进多模态预训练,我们引入了Multi-Transmotion,这是一种基于Transformer的创新模型,专为跨模态预训练而设计。此外,我们提出了一种新颖的掩码策略来捕获丰富的表示。我们的方法在各种数据集上的多个下游任务中表现出具有竞争力的性能,包括NBA和JTA数据集中的轨迹预测,以及AMASS和3DPW数据集中的姿态预测。代码已公开。
🔬 方法详解
问题定义:人体运动预测是智能系统理解和预测人类行为的关键能力。然而,由于人体运动的复杂性和多样性,缺乏一个统一的标准数据集,这使得预训练模型的开发变得困难。现有方法通常依赖于特定数据集进行训练,泛化能力有限。
核心思路:本文的核心思路是整合多个不同模态的人体运动数据集,包括轨迹和3D姿态关键点,并利用Transformer模型进行跨模态预训练。通过这种方式,模型可以学习到更丰富和通用的运动表示,从而提高在各种下游任务中的性能。
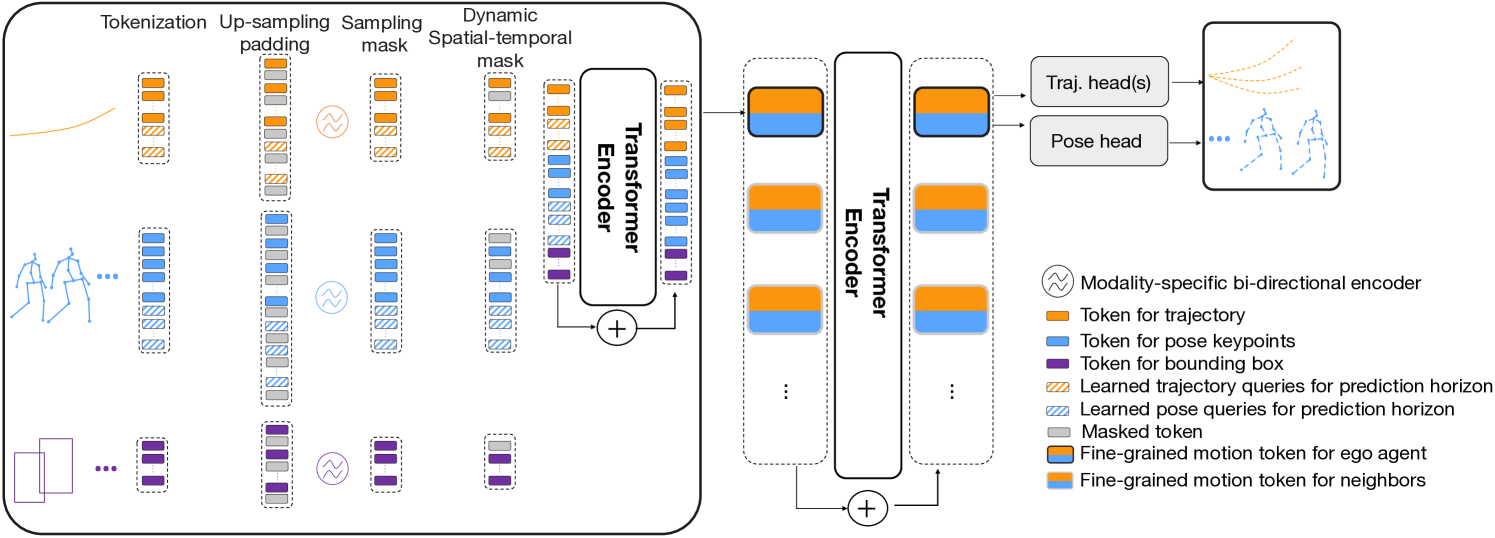
技术框架:Multi-Transmotion模型基于Transformer架构,主要包含以下几个模块:数据整合模块,用于将不同格式的数据集标准化;跨模态Transformer编码器,用于学习多模态数据的联合表示;掩码策略模块,用于增强模型的表示学习能力。整体流程是首先对多模态数据进行预处理和标准化,然后输入到Transformer编码器中进行训练,最后将预训练的模型应用于下游任务。
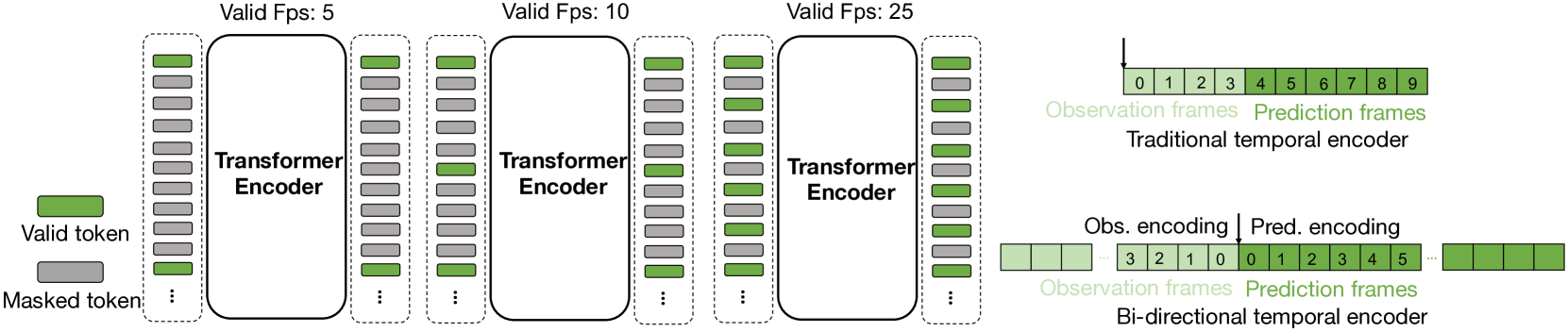
关键创新:该论文的关键创新在于提出了一个用于人体运动预测的跨模态预训练模型,并设计了一种新颖的掩码策略。通过整合多个数据集,模型可以学习到更通用的运动表示。此外,跨模态预训练使得模型能够利用不同模态之间的互补信息,从而提高预测精度。
关键设计:Multi-Transmotion模型采用了标准的Transformer编码器结构,并针对人体运动预测任务进行了优化。关键设计包括:1) 数据标准化方法,将不同数据集的数据统一到相同的格式;2) 跨模态Transformer编码器,使用自注意力机制学习多模态数据的联合表示;3) 掩码策略,随机掩盖部分输入数据,迫使模型学习更鲁棒的表示;4) 损失函数,采用均方误差损失函数来衡量预测结果与真实值之间的差异。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Multi-Transmotion模型在NBA和JTA数据集上的轨迹预测任务以及AMASS和3DPW数据集上的姿态预测任务中均取得了具有竞争力的性能。具体来说,该模型在多个指标上优于或与现有基线方法相当,证明了其有效性和泛化能力。代码已开源,方便研究人员复现和进一步研究。
🎯 应用场景
该研究成果可广泛应用于自动驾驶、社交机器人、虚拟现实、人机交互等领域。例如,在自动驾驶中,该模型可以预测行人的运动轨迹,从而提高驾驶安全性。在社交机器人中,该模型可以理解人类的肢体语言,从而实现更自然的人机交互。该研究为开发更智能、更人性化的智能系统奠定了基础。
📄 摘要(原文)
The ability of intelligent systems to predict human behaviors is crucial, particularly in fields such as autonomous vehicle navigation and social robotics. However, the complexity of human motion have prevented the development of a standardized dataset for human motion prediction, thereby hindering the establishment of pre-trained models. In this paper, we address these limitations by integrating multiple datasets, encompassing both trajectory and 3D pose keypoints, to propose a pre-trained model for human motion prediction. We merge seven distinct datasets across varying modalities and standardize their formats. To facilitate multimodal pre-training, we introduce Multi-Transmotion, an innovative transformer-based model designed for cross-modality pre-training. Additionally, we present a novel masking strategy to capture rich representations. Our methodology demonstrates competitive performance across various datasets on several downstream tasks, including trajectory prediction in the NBA and JTA datasets, as well as pose prediction in the AMASS and 3DPW datasets. The code is publicly available: https://github.com/vita-epfl/multi-transmotion