How Far is Video Generation from World Model: A Physical Law Perspective
作者: Bingyi Kang, Yang Yue, Rui Lu, Zhijie Lin, Yang Zhao, Kaixin Wang, Gao Huang, Jiashi Feng
分类: cs.CV, cs.AI
发布日期: 2024-11-04 (更新: 2025-06-22)
备注: ICML 2025
💡 一句话要点
通过物理定律视角评估视频生成模型的世界模型能力与泛化机制
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 视频生成 世界模型 物理定律 泛化能力 扩散模型
📋 核心要点
- 现有视频生成模型在学习物理定律方面存在不足,缺乏对物理规律的真正理解,难以泛化到新场景。
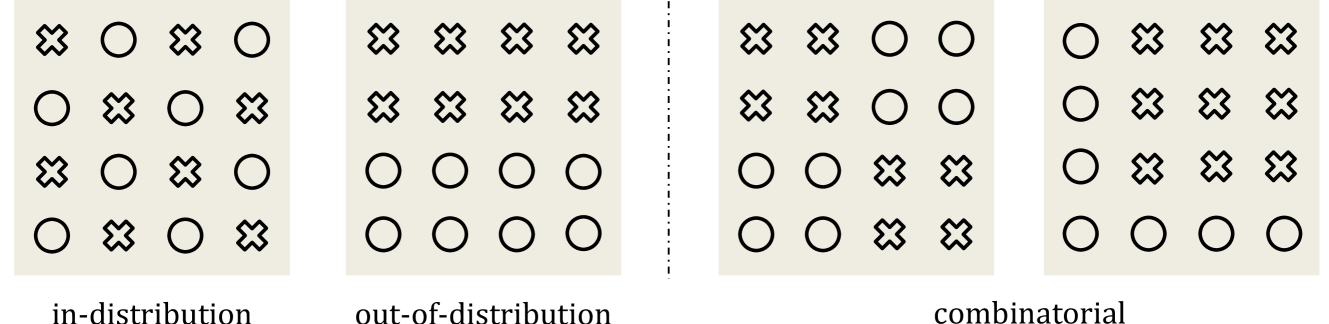
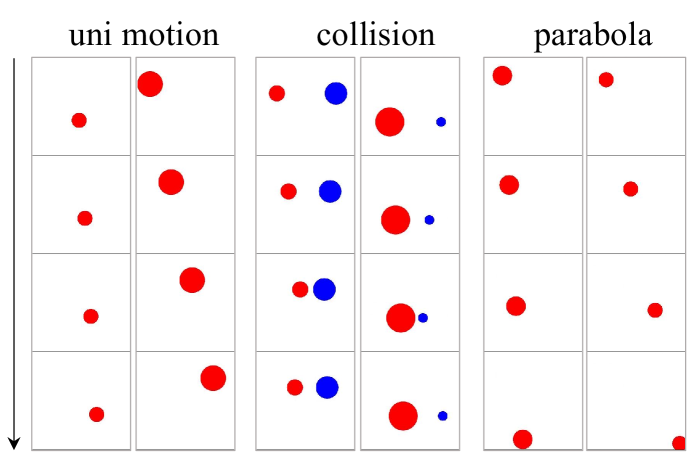
- 论文构建2D物理模拟环境,生成大量数据,用于训练和评估视频生成模型在不同泛化场景下的表现。
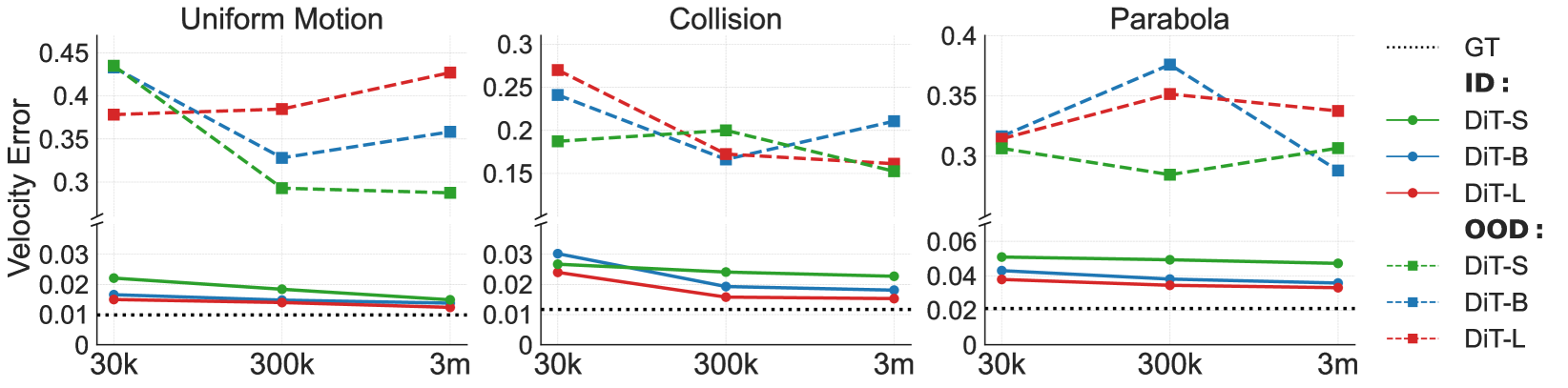
- 实验表明,模型在同分布泛化表现良好,但在异分布泛化中失败,揭示了模型“基于案例”的泛化机制。
📝 摘要(中文)
OpenAI的Sora展示了视频生成在发展遵循物理定律的世界模型方面的潜力。然而,视频生成模型是否能在没有人为先验知识的情况下,仅从视觉数据中发现这些定律是值得怀疑的。一个学习真实定律的世界模型应该对细微差别具有鲁棒性,并能正确地推断未见过的场景。本文在三个关键场景中进行了评估:同分布、异分布和组合泛化。我们开发了一个2D模拟测试平台,用于物体运动和碰撞,以确定性地生成受一个或多个经典力学定律支配的视频。这为大规模实验提供了无限的数据,并能够定量评估生成的视频是否符合物理定律。我们训练了基于扩散的视频生成模型,以根据初始帧预测物体运动。我们的缩放实验表明,模型在同分布情况下表现出完美的泛化能力,在组合泛化方面表现出可衡量的缩放行为,但在异分布场景中则失败。进一步的实验揭示了关于这些模型泛化机制的两个关键见解:(1) 模型未能抽象出一般的物理规则,而是表现出“基于案例”的泛化行为,即模仿最接近的训练示例;(2) 在推广到新案例时,模型在参考训练数据时会优先考虑不同的因素:颜色 > 大小 > 速度 > 形状。我们的研究表明,尽管缩放对Sora的广泛成功起到了作用,但仅靠缩放不足以使视频生成模型发现基本的物理定律。
🔬 方法详解
问题定义:现有视频生成模型,如Sora,虽然在生成逼真视频方面取得了显著进展,但其是否真正理解并遵循物理定律仍不清楚。现有方法缺乏对物理规律的抽象能力,难以泛化到训练数据之外的场景,例如物体数量、初始状态等发生显著变化的场景。因此,如何评估和提升视频生成模型对物理定律的理解和泛化能力是一个关键问题。
核心思路:论文的核心思路是通过构建一个可控的2D物理模拟环境,生成大量符合经典力学定律的视频数据,然后训练视频生成模型来预测物体运动。通过定量评估模型在不同泛化场景下的表现,来分析模型是否真正学习到了物理定律,以及其泛化机制。这种方法允许精确控制实验条件,并对模型的预测结果进行定量分析。
技术框架:整体框架包括以下几个主要步骤:1) 构建2D物理模拟环境,该环境可以模拟物体运动和碰撞,并根据设定的物理定律生成视频数据。2) 定义不同的泛化场景,包括同分布、异分布和组合泛化。3) 使用生成的视频数据训练基于扩散模型的视频生成模型。4) 在不同的泛化场景下评估模型的预测结果,并分析模型的泛化能力。5) 通过控制变量实验,分析模型在泛化过程中所关注的因素。
关键创新:论文的关键创新在于:1) 构建了一个可控的2D物理模拟环境,为大规模实验提供了数据基础。2) 提出了基于不同泛化场景的评估方法,可以定量分析模型对物理定律的理解程度。3) 揭示了视频生成模型“基于案例”的泛化机制,以及在泛化过程中对不同因素的优先级排序。
关键设计:在2D物理模拟环境中,论文使用经典力学定律来控制物体运动和碰撞。视频生成模型采用基于扩散模型的架构,通过学习视频帧之间的条件概率分布来预测物体运动。在训练过程中,使用均方误差(MSE)作为损失函数,优化模型的预测结果。在评估过程中,使用定量指标来衡量模型预测的准确性,例如预测位置与真实位置之间的距离。
🖼️ 关键图片
📊 实验亮点
实验结果表明,视频生成模型在同分布情况下表现出接近完美的泛化能力,但在异分布情况下则完全失败。在组合泛化方面,模型表现出可衡量的缩放行为,但性能提升有限。进一步分析表明,模型倾向于模仿最接近的训练示例,并且在泛化过程中,颜色、大小、速度和形状等因素的优先级不同,颜色优先级最高。
🎯 应用场景
该研究成果可应用于开发更智能、更可靠的机器人和自动驾驶系统。通过让模型学习物理定律,可以提高其在复杂环境中的感知和决策能力。此外,该研究还可以促进对视频生成模型内在机制的理解,为开发更强大的世界模型奠定基础,例如用于游戏AI或虚拟现实。
📄 摘要(原文)
OpenAI's Sora highlights the potential of video generation for developing world models that adhere to fundamental physical laws. However, the ability of video generation models to discover such laws purely from visual data without human priors can be questioned. A world model learning the true law should give predictions robust to nuances and correctly extrapolate on unseen scenarios. In this work, we evaluate across three key scenarios: in-distribution, out-of-distribution, and combinatorial generalization. We developed a 2D simulation testbed for object movement and collisions to generate videos deterministically governed by one or more classical mechanics laws. This provides an unlimited supply of data for large-scale experimentation and enables quantitative evaluation of whether the generated videos adhere to physical laws. We trained diffusion-based video generation models to predict object movements based on initial frames. Our scaling experiments show perfect generalization within the distribution, measurable scaling behavior for combinatorial generalization, but failure in out-of-distribution scenarios. Further experiments reveal two key insights about the generalization mechanisms of these models: (1) the models fail to abstract general physical rules and instead exhibit "case-based" generalization behavior, i.e., mimicking the closest training example; (2) when generalizing to new cases, models are observed to prioritize different factors when referencing training data: color > size > velocity > shape. Our study suggests that scaling alone is insufficient for video generation models to uncover fundamental physical laws, despite its role in Sora's broader success. See our project page at https://phyworld.github.io