Learning General-Purpose Biomedical Volume Representations using Randomized Synthesis
作者: Neel Dey, Benjamin Billot, Hallee E. Wong, Clinton J. Wang, Mengwei Ren, P. Ellen Grant, Adrian V. Dalca, Polina Golland
分类: cs.CV, cs.LG
发布日期: 2024-11-04 (更新: 2025-03-02)
备注: ICLR 2025: International Conference on Learning Representations. Code and model weights available at https://github.com/neel-dey/anatomix. Keywords: synthetic data, representation learning, medical image analysis, image registration, image segmentation
💡 一句话要点
提出基于随机合成的通用生物医学体数据表征学习方法,提升模型泛化性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 生物医学图像 体数据表征学习 随机合成 对比学习 多模态配准 少样本分割 领域泛化
📋 核心要点
- 现有的生物医学体数据基础模型泛化能力弱,主要原因是3D数据集规模小且多样性不足。
- 论文提出一种基于随机合成数据的数据引擎和对比学习方法,增强模型对成像变化的鲁棒性,提升泛化能力。
- 实验表明,该方法在多模态配准和少样本分割任务上取得了新的突破,无需真实图像预训练。
📝 摘要(中文)
当前的生物医学体数据基础模型难以泛化,因为公开的3D数据集规模小,且不能覆盖医疗程序、病症、解剖区域和成像协议的广泛多样性。为了解决这个问题,我们提出了一种表征学习方法,该方法在训练时就预先考虑到强大的领域迁移。我们首先提出了一个数据引擎,用于合成高度可变的训练样本,从而能够推广到新的生物医学环境。然后,为了训练一个用于任何体素级别任务的3D网络,我们开发了一种对比学习方法,该方法预训练网络,使其对数据引擎模拟的干扰成像变化保持稳定,这是泛化的关键归纳偏置。该网络的特征可以作为输入图像的鲁棒表示用于下游任务,其权重为在新数据集上进行微调提供了强大的、数据集无关的初始化。因此,我们在多模态配准和少样本分割方面都设定了新的标准,这对于任何3D生物医学视觉模型来说都是第一次,所有这些都没有在任何现有的真实图像数据集上进行(预)训练。
🔬 方法详解
问题定义:现有生物医学体数据模型依赖于有限的真实数据集进行训练,导致模型在面对新的医疗程序、病症、解剖区域和成像协议时泛化能力不足。模型难以适应不同成像条件下的噪声和伪影,限制了其在实际临床应用中的有效性。
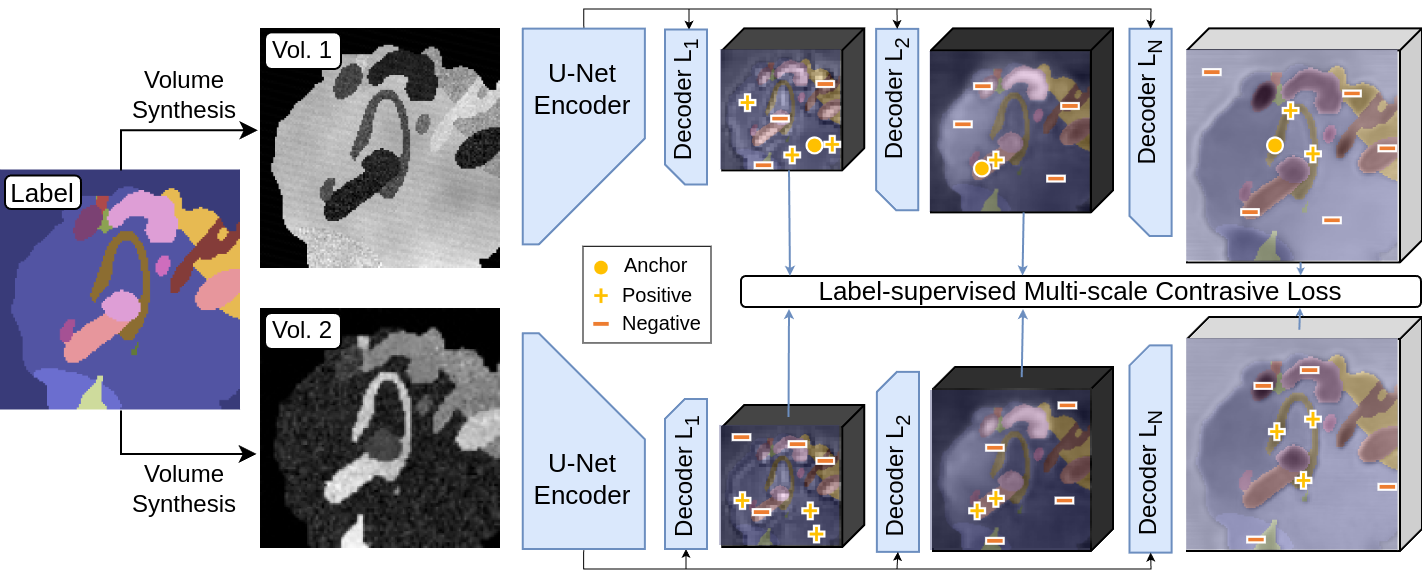
核心思路:论文的核心思路是通过合成高度可变的训练数据,并在训练过程中引入对比学习,使模型能够学习到对成像变化具有鲁棒性的通用表征。通过模拟各种可能的成像条件,模型可以更好地适应真实世界中的数据分布,从而提高泛化能力。
技术框架:该方法包含两个主要组成部分:数据引擎和对比学习框架。数据引擎负责生成具有高度多样性的合成训练样本,包括不同的解剖结构、病理变化和成像参数。对比学习框架则利用这些合成数据来训练3D神经网络,使其能够区分不同的解剖结构,同时对成像变化保持不变性。训练后的网络可以提取输入图像的鲁棒特征,并用于下游任务。
关键创新:该方法最重要的创新点在于其完全依赖于合成数据进行训练,避免了对真实数据集的依赖。通过精心设计的数据引擎和对比学习框架,模型能够学习到具有高度泛化能力的表征,并在多个下游任务上取得了显著的性能提升。
关键设计:数据引擎通过随机组合不同的解剖结构、病理变化和成像参数来生成合成数据。对比学习框架使用InfoNCE损失函数,鼓励模型将同一解剖结构的不同成像变体映射到相似的表征空间,同时将不同解剖结构映射到不同的表征空间。网络结构采用标准的3D卷积神经网络,并针对生物医学图像的特点进行了优化。
🖼️ 关键图片


📊 实验亮点
该方法在多模态配准和少样本分割任务上取得了显著的性能提升,无需在真实图像数据集上进行预训练。在多模态配准任务中,该方法优于现有的基于深度学习的方法。在少样本分割任务中,该方法在仅使用少量标注样本的情况下,也能达到与使用大量标注样本训练的模型相当的性能。
🎯 应用场景
该研究成果可广泛应用于医学图像分析领域,例如辅助诊断、手术规划和图像引导治疗。通过提供更鲁棒和通用的图像表征,该方法可以提高医学图像分析算法的准确性和可靠性,从而改善患者的诊断和治疗效果。此外,该方法还可以用于开发新的医学图像分析工具和应用,例如自动分割和配准算法。
📄 摘要(原文)
Current volumetric biomedical foundation models struggle to generalize as public 3D datasets are small and do not cover the broad diversity of medical procedures, conditions, anatomical regions, and imaging protocols. We address this by creating a representation learning method that instead anticipates strong domain shifts at training time itself. We first propose a data engine that synthesizes highly variable training samples that would enable generalization to new biomedical contexts. To then train a single 3D network for any voxel-level task, we develop a contrastive learning method that pretrains the network to be stable against nuisance imaging variation simulated by the data engine, a key inductive bias for generalization. This network's features can be used as robust representations of input images for downstream tasks and its weights provide a strong, dataset-agnostic initialization for finetuning on new datasets. As a result, we set new standards across both multimodality registration and few-shot segmentation, a first for any 3D biomedical vision model, all without (pre-)training on any existing dataset of real images.