PPLLaVA: Varied Video Sequence Understanding With Prompt Guidance
作者: Ruyang Liu, Haoran Tang, Haibo Liu, Yixiao Ge, Ying Shan, Chen Li, Jiankun Yang
分类: cs.CV
发布日期: 2024-11-04 (更新: 2024-11-05)
🔗 代码/项目: GITHUB
💡 一句话要点
PPLLaVA:提出提示引导的池化策略,实现短视频与长视频的统一理解。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频大语言模型 长视频理解 提示学习 视觉特征聚合 池化策略
📋 核心要点
- 现有视频LLM难以兼顾短视频和长视频,长视频模型在短视频上表现不佳,短视频模型无法处理长视频。
- PPLLaVA通过提示引导的池化策略,在压缩token的同时,聚合指令相关的视觉特征,实现对不同长度视频的统一理解。
- 实验表明,PPLLaVA在图像和视频基准测试中均表现出色,在吞吐量和视觉上下文长度上具有优势。
📝 摘要(中文)
过去一年,基于视频的大语言模型取得了显著进展。然而,开发一个统一的模型来理解短视频和长视频仍然是一个挑战。现有的大多数视频LLM无法处理数小时的视频,而为长视频定制的方法往往对较短的视频和图像无效。本文认为关键问题在于视频中存在冗余内容。为了解决这个问题,我们提出了一种新颖的池化策略,该策略同时实现了token压缩和指令感知的视觉特征聚合。我们的模型被称为提示引导池化LLaVA,简称PPLLaVA。具体来说,PPLLaVA由三个核心组件组成:基于CLIP的视觉提示对齐,用于提取与用户指令相关的视觉信息;提示引导池化,使用卷积式池化将视觉序列压缩到任意尺度;以及为视觉对话中常见的长提示设计的clip上下文扩展。此外,我们的代码库还集成了最先进的视频直接偏好优化(DPO)和视觉交错训练。大量的实验验证了我们模型的性能。凭借卓越的吞吐量和仅1024个视觉上下文,PPLLaVA作为视频LLM在图像基准测试中取得了更好的结果,同时在各种视频基准测试中实现了最先进的性能,擅长从字幕生成到多项选择题等任务,并能处理从几秒到几小时的视频长度。代码已在https://github.com/farewellthree/PPLLaVA上提供。
🔬 方法详解
问题定义:现有视频大语言模型难以同时处理短视频和长视频。专门为长视频设计的模型在短视频和图像上的表现往往不佳,而为短视频设计的模型则无法处理长视频。核心痛点在于视频中存在大量的冗余信息,如何有效压缩和提取关键信息是关键。
核心思路:PPLLaVA的核心思路是利用用户提供的提示(Prompt)来引导视觉特征的提取和聚合,从而减少冗余信息的影响,并使模型能够根据任务需求自适应地处理不同长度的视频。通过提示引导的池化策略,模型可以有效地压缩视觉token,同时保留与任务相关的关键信息。
技术框架:PPLLaVA主要包含三个核心模块:1) CLIP-based visual-prompt alignment (视觉提示对齐):利用CLIP模型提取与用户指令相关的视觉信息,将视觉信息与文本提示对齐。2) Prompt-guided pooling (提示引导池化):使用卷积式池化操作,根据用户提示将视觉序列压缩到任意尺度,实现token压缩。3) Clip context extension (clip上下文扩展):专门为视觉对话中常见的长提示设计,扩展模型的上下文处理能力。此外,该模型还集成了视频直接偏好优化(DPO)和视觉交错训练。
关键创新:PPLLaVA的关键创新在于其提示引导的池化策略。与传统的池化方法不同,PPLLaVA的池化过程受到用户提示的引导,能够更加关注与任务相关的视觉特征,从而提高模型的性能。此外,模型还集成了clip上下文扩展,使其能够处理更长的提示信息。
关键设计:PPLLaVA使用CLIP模型作为视觉编码器,提取视觉特征。提示引导池化采用卷积操作实现,池化核的大小和步长可以根据视频长度和任务需求进行调整。损失函数方面,模型采用视频直接偏好优化(DPO)进行训练,以提高模型的生成质量。具体参数设置和网络结构细节未在摘要中详细说明,需要参考论文全文。
🖼️ 关键图片


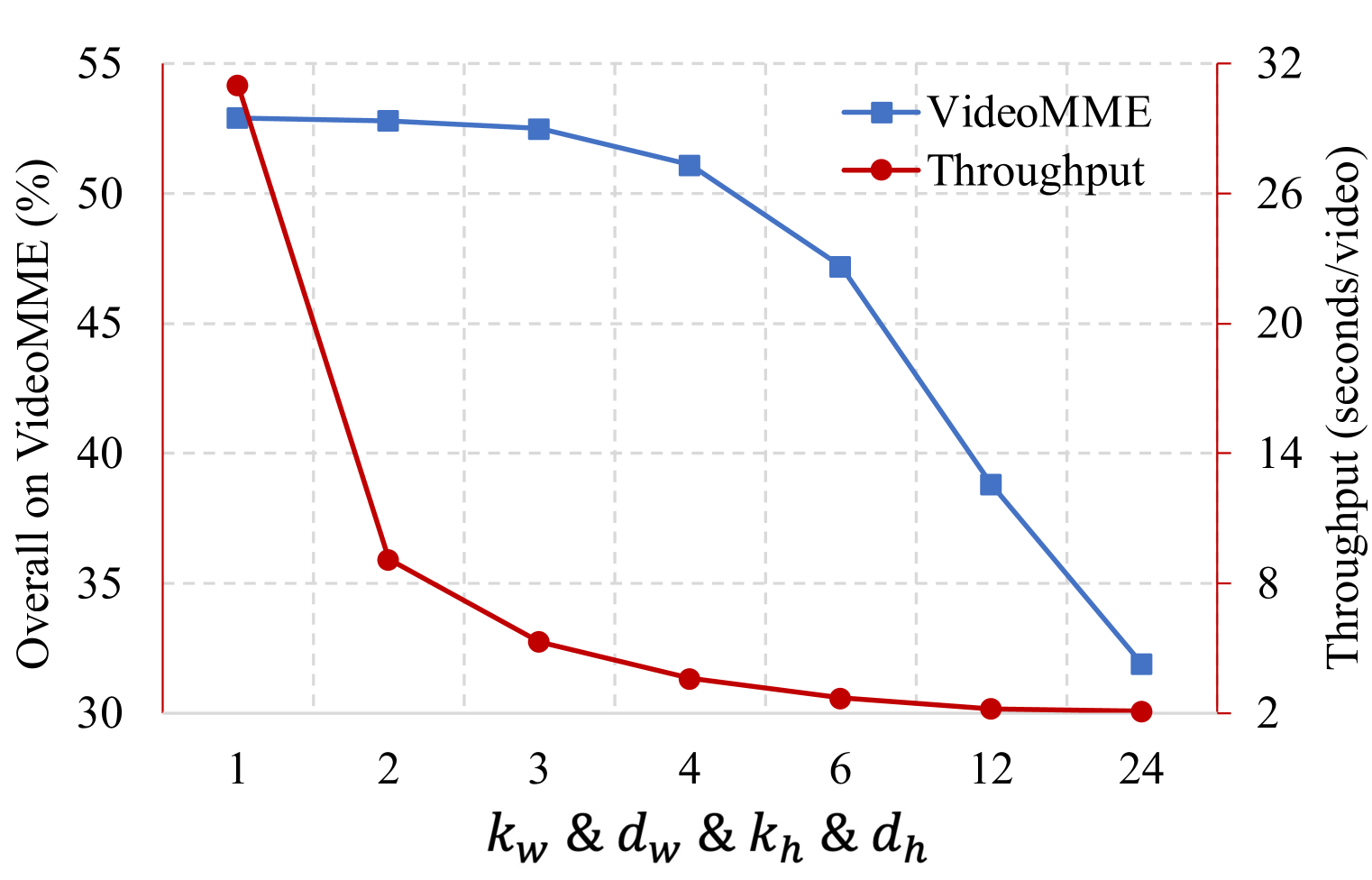
📊 实验亮点
PPLLaVA在图像基准测试中取得了优于其他视频LLM的结果,同时在各种视频基准测试中实现了最先进的性能。该模型仅使用1024个视觉上下文,就能够处理从几秒到几小时的视频,并且在字幕生成和多项选择题等任务中表现出色。实验结果表明,PPLLaVA在吞吐量和性能方面都具有显著优势。
🎯 应用场景
PPLLaVA可应用于各种视频理解任务,例如视频字幕生成、视频问答、视频摘要等。该模型能够处理不同长度的视频,使其在实际应用中具有广泛的适用性。例如,可以用于智能监控、视频内容分析、在线教育等领域,提升视频处理的效率和准确性。
📄 摘要(原文)
The past year has witnessed the significant advancement of video-based large language models. However, the challenge of developing a unified model for both short and long video understanding remains unresolved. Most existing video LLMs cannot handle hour-long videos, while methods custom for long videos tend to be ineffective for shorter videos and images. In this paper, we identify the key issue as the redundant content in videos. To address this, we propose a novel pooling strategy that simultaneously achieves token compression and instruction-aware visual feature aggregation. Our model is termed Prompt-guided Pooling LLaVA, or PPLLaVA for short. Specifically, PPLLaVA consists of three core components: the CLIP-based visual-prompt alignment that extracts visual information relevant to the user's instructions, the prompt-guided pooling that compresses the visual sequence to arbitrary scales using convolution-style pooling, and the clip context extension designed for lengthy prompt common in visual dialogue. Moreover, our codebase also integrates the most advanced video Direct Preference Optimization (DPO) and visual interleave training. Extensive experiments have validated the performance of our model. With superior throughput and only 1024 visual context, PPLLaVA achieves better results on image benchmarks as a video LLM, while achieving state-of-the-art performance across various video benchmarks, excelling in tasks ranging from caption generation to multiple-choice questions, and handling video lengths from seconds to hours. Codes have been available at https://github.com/farewellthree/PPLLaVA.