Improving Domain Generalization in Self-supervised Monocular Depth Estimation via Stabilized Adversarial Training
作者: Yuanqi Yao, Gang Wu, Kui Jiang, Siao Liu, Jian Kuai, Xianming Liu, Junjun Jiang
分类: cs.CV
发布日期: 2024-11-04 (更新: 2024-11-05)
备注: Accepted to ECCV 2024
DOI: 10.1007/978-3-031-72691-0_11
💡 一句话要点
提出SCAT框架,通过稳定对抗训练提升自监督单目深度估计的领域泛化性
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 自监督学习 单目深度估计 领域泛化 对抗训练 深度网络
📋 核心要点
- 自监督单目深度估计模型在领域泛化性方面面临挑战,直接应用对抗训练易导致过度正则化和性能下降。
- 论文提出稳定冲突优化对抗训练(SCAT)框架,旨在平衡训练的稳定性和模型的泛化能力。
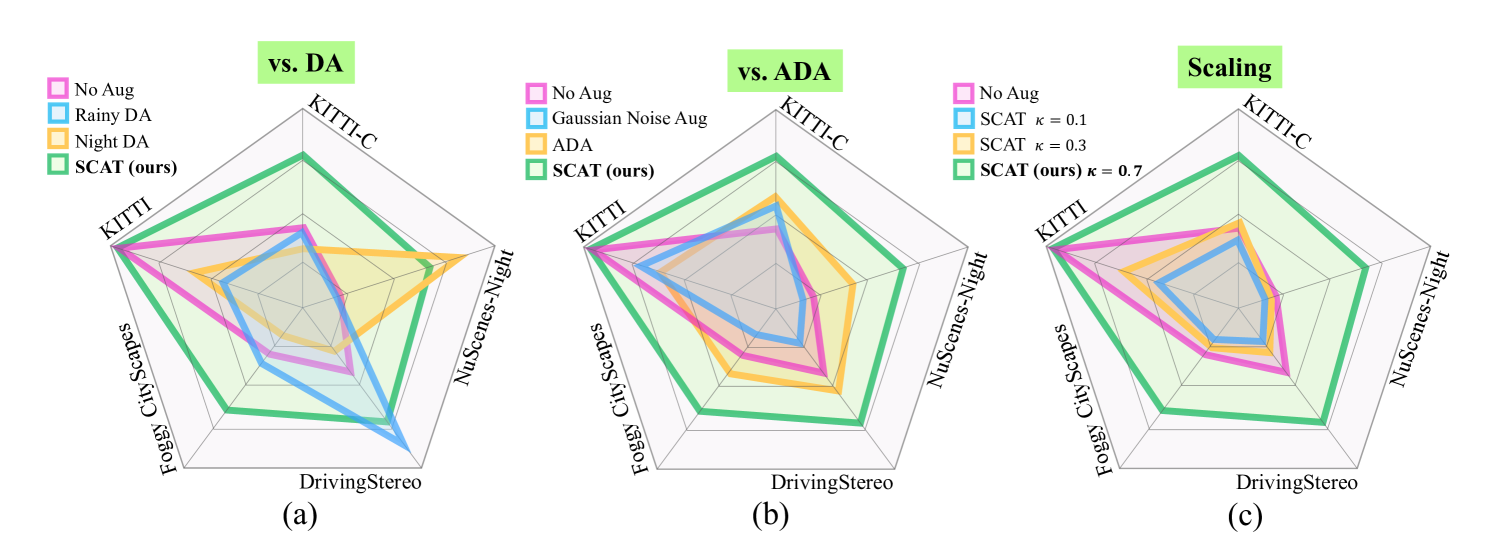
- 实验结果表明,SCAT在多个基准测试中取得了最先进的性能,并显著提升了现有方法的泛化能力。
📝 摘要(中文)
本文致力于解决自监督单目深度估计(MDE)模型泛化性差的问题。尽管对抗数据增强在监督学习泛化中取得了成功,但将其直接应用于自监督MDE模型可能导致过度正则化,从而严重降低性能。通过定性分析,我们揭示了主要原因:(i)类UNet深度网络的固有敏感性;(ii)过度正则化引起的双重优化冲突。为了解决这些问题,我们提出了一个通用的对抗训练框架,名为稳定冲突优化对抗训练(SCAT),将对抗数据增强集成到自监督MDE方法中,以实现稳定性和泛化性之间的平衡。具体来说,我们设计了一个有效的缩放深度网络,调整长跳跃连接的系数,有效地稳定训练过程。然后,我们提出了一种冲突梯度手术策略,逐步整合对抗梯度,并朝着无冲突的方向优化模型。在五个基准数据集上的大量实验表明,SCAT可以实现最先进的性能,并显著提高现有自监督MDE方法的泛化能力。
🔬 方法详解
问题定义:自监督单目深度估计(MDE)模型在不同领域的数据上泛化能力较差。简单地将对抗训练引入自监督MDE模型,会因为深度网络的敏感性和优化冲突导致过度正则化,反而降低模型性能。现有方法难以在稳定训练和提升泛化性之间取得平衡。
核心思路:通过稳定网络结构和优化策略来解决对抗训练中的冲突,从而提升模型的泛化能力。核心思想是避免过度正则化,同时利用对抗训练提升模型的鲁棒性。
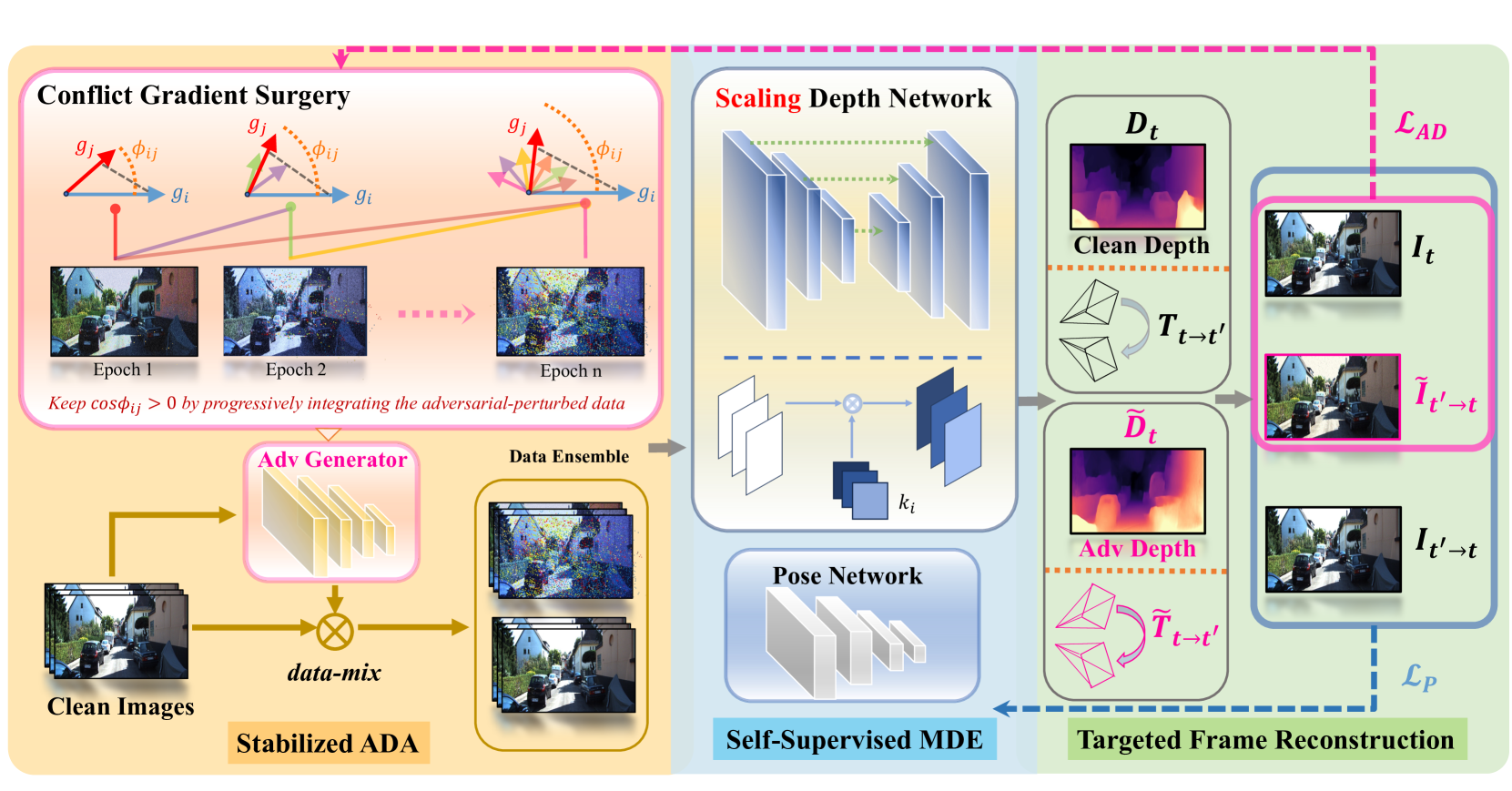
技术框架:SCAT框架主要包含两个关键模块:(1) 缩放深度网络(Scaling Depth Network):通过调整长跳跃连接的系数来稳定训练过程,降低网络对对抗扰动的敏感性。(2) 冲突梯度手术策略(Conflict Gradient Surgery):逐步整合对抗梯度,避免优化方向冲突,使模型朝着一个更优的方向收敛。整体流程是先使用缩放深度网络进行训练,然后使用冲突梯度手术策略来优化模型。
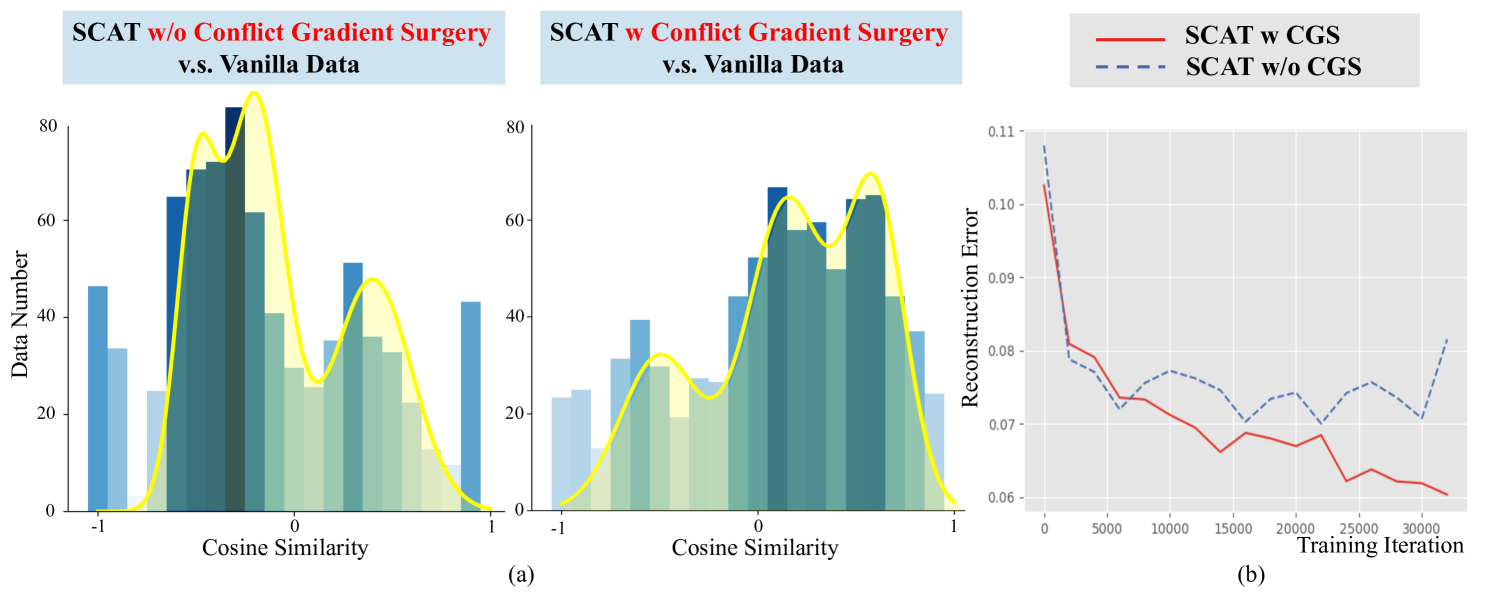
关键创新:关键创新在于同时解决了深度网络的敏感性和优化冲突问题。缩放深度网络通过调整跳跃连接的权重,降低了网络对输入扰动的敏感性,从而稳定了训练过程。冲突梯度手术策略则通过逐步整合对抗梯度,避免了优化方向的冲突,使得模型能够更好地学习到具有泛化能力的特征。
关键设计:缩放深度网络的关键设计在于对长跳跃连接的系数进行调整,具体实现方式未知。冲突梯度手术策略的关键在于如何判断和处理冲突梯度,具体实现方式未知。损失函数方面,除了深度估计常用的损失函数外,还引入了对抗损失来提升模型的鲁棒性。具体参数设置未知。
🖼️ 关键图片
📊 实验亮点
SCAT在五个基准数据集上进行了广泛的实验,结果表明其能够显著提高现有自监督MDE方法的泛化能力,并取得了state-of-the-art的性能。具体性能数据和对比基线未知,但摘要强调了“显著提高”和“最先进的性能”,表明提升幅度较大。
🎯 应用场景
该研究成果可应用于自动驾驶、机器人导航、虚拟现实等领域,提升这些系统在不同环境下的感知能力和鲁棒性。通过提高单目深度估计的泛化性,可以降低对特定训练数据的依赖,从而降低部署成本和提高应用范围。未来,该技术有望在更多视觉感知任务中发挥作用。
📄 摘要(原文)
Learning a self-supervised Monocular Depth Estimation (MDE) model with great generalization remains significantly challenging. Despite the success of adversarial augmentation in the supervised learning generalization, naively incorporating it into self-supervised MDE models potentially causes over-regularization, suffering from severe performance degradation. In this paper, we conduct qualitative analysis and illuminate the main causes: (i) inherent sensitivity in the UNet-alike depth network and (ii) dual optimization conflict caused by over-regularization. To tackle these issues, we propose a general adversarial training framework, named Stabilized Conflict-optimization Adversarial Training (SCAT), integrating adversarial data augmentation into self-supervised MDE methods to achieve a balance between stability and generalization. Specifically, we devise an effective scaling depth network that tunes the coefficients of long skip connection and effectively stabilizes the training process. Then, we propose a conflict gradient surgery strategy, which progressively integrates the adversarial gradient and optimizes the model toward a conflict-free direction. Extensive experiments on five benchmarks demonstrate that SCAT can achieve state-of-the-art performance and significantly improve the generalization capability of existing self-supervised MDE methods.