KptLLM: Unveiling the Power of Large Language Model for Keypoint Comprehension
作者: Jie Yang, Wang Zeng, Sheng Jin, Lumin Xu, Wentao Liu, Chen Qian, Ruimao Zhang
分类: cs.CV
发布日期: 2024-11-04
备注: NeurIPS 2024
💡 一句话要点
提出KptLLM,利用大语言模型进行关键点语义理解,解决像素级语义细节捕捉难题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 关键点检测 多模态大语言模型 语义理解 思维链 图像理解
📋 核心要点
- 现有多模态大语言模型在像素级语义细节(如关键点)的理解上存在不足,限制了其应用。
- KptLLM采用“先识别语义,后检测位置”的策略,通过思维链过程提升关键点理解能力。
- 实验结果表明,KptLLM在关键点检测任务上优于现有方法,并展现出独特的语义理解能力。
📝 摘要(中文)
多模态大语言模型(MLLMs)在图像理解方面取得了显著进展。然而,这些模型通常难以掌握像素级的语义细节,例如物体的关键点。为了弥合这一差距,我们提出了语义关键点理解这一新挑战,旨在理解不同任务场景中的关键点,包括关键点语义理解、基于视觉提示的关键点检测和基于文本提示的关键点检测。此外,我们引入了KptLLM,一个统一的多模态模型,它利用identify-then-detect策略来有效地应对这些挑战。KptLLM强调首先识别关键点的语义,然后通过思维链过程精确确定其位置。通过几个精心设计的模块,KptLLM能够熟练地处理各种模态输入,从而促进对语义内容和关键点位置的解释。大量的实验表明,KptLLM在各种关键点检测基准测试中表现出色,并且在解释关键点方面具有独特的语义能力。
🔬 方法详解
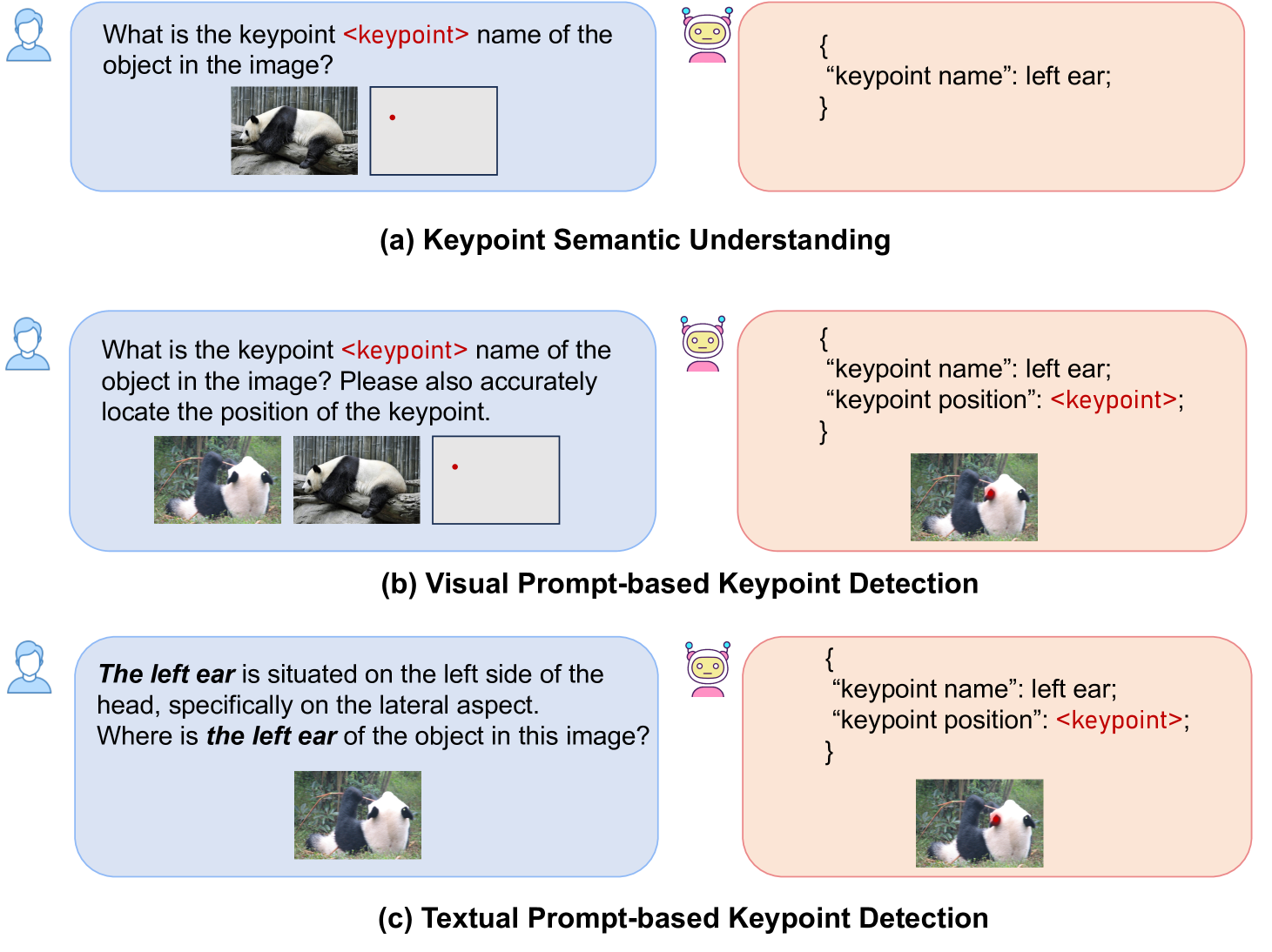
问题定义:现有MLLM模型在处理图像时,难以精确理解像素级别的语义信息,尤其是在关键点检测任务中,无法有效识别和定位目标的关键点。这限制了模型在需要精细化理解图像内容的任务中的应用,例如人体姿态估计、物体部件定位等。现有方法缺乏对关键点语义信息的有效利用,导致检测精度不高。
核心思路:KptLLM的核心思路是首先识别关键点的语义信息,然后再基于这些语义信息进行关键点位置的精确检测。这种“identify-then-detect”的策略模拟了人类的认知过程,即先理解目标是什么,再确定其位置。通过引入语义理解环节,可以有效提升关键点检测的准确性和鲁棒性。
技术框架:KptLLM是一个统一的多模态模型,其整体架构包含以下几个主要模块:1) 多模态输入处理模块:负责处理来自不同模态的输入,例如图像和文本提示。2) 关键点语义识别模块:用于识别关键点的语义信息,例如“左肘”、“右膝”等。3) 思维链推理模块:通过思维链过程,逐步推理出关键点的位置信息。4) 关键点位置检测模块:基于语义信息和推理结果,精确检测关键点的位置。
关键创新:KptLLM的关键创新在于其“identify-then-detect”的策略以及对思维链推理的运用。与现有方法直接进行关键点检测不同,KptLLM首先关注关键点的语义信息,这使得模型能够更好地理解图像内容,从而提升检测精度。此外,思维链推理的引入使得模型能够逐步推理出关键点的位置,避免了直接预测可能带来的误差。
关键设计:KptLLM的关键设计包括:1) 精心设计的多模态输入处理模块,能够有效融合图像和文本信息。2) 基于Transformer的关键点语义识别模块,能够准确识别关键点的语义信息。3) 基于思维链的推理模块,通过逐步推理提升关键点定位的准确性。4) 损失函数的设计,综合考虑了语义识别和位置检测的准确性。
🖼️ 关键图片


📊 实验亮点
KptLLM在多个关键点检测基准测试中取得了显著的性能提升。实验结果表明,KptLLM在关键点检测精度上优于现有方法,尤其是在复杂场景和遮挡情况下,其鲁棒性更强。此外,KptLLM展现出独特的语义理解能力,能够根据文本提示准确识别和定位关键点。
🎯 应用场景
KptLLM在人体姿态估计、物体部件定位、图像编辑、机器人导航等领域具有广泛的应用前景。通过精确理解和定位关键点,可以提升相关任务的性能和鲁棒性。例如,在机器人导航中,KptLLM可以帮助机器人理解环境中的关键物体,从而更好地规划路径和执行任务。未来,KptLLM有望成为多模态图像理解的重要组成部分。
📄 摘要(原文)
Recent advancements in Multimodal Large Language Models (MLLMs) have greatly improved their abilities in image understanding. However, these models often struggle with grasping pixel-level semantic details, e.g., the keypoints of an object. To bridge this gap, we introduce the novel challenge of Semantic Keypoint Comprehension, which aims to comprehend keypoints across different task scenarios, including keypoint semantic understanding, visual prompt-based keypoint detection, and textual prompt-based keypoint detection. Moreover, we introduce KptLLM, a unified multimodal model that utilizes an identify-then-detect strategy to effectively address these challenges. KptLLM underscores the initial discernment of semantics in keypoints, followed by the precise determination of their positions through a chain-of-thought process. With several carefully designed modules, KptLLM adeptly handles various modality inputs, facilitating the interpretation of both semantic contents and keypoint locations. Our extensive experiments demonstrate KptLLM's superiority in various keypoint detection benchmarks and its unique semantic capabilities in interpreting keypoints.