Unified Generative and Discriminative Training for Multi-modal Large Language Models
作者: Wei Chow, Juncheng Li, Qifan Yu, Kaihang Pan, Hao Fei, Zhiqi Ge, Shuai Yang, Siliang Tang, Hanwang Zhang, Qianru Sun
分类: cs.CV, cs.MM
发布日期: 2024-11-01
💡 一句话要点
提出统一生成式与判别式训练框架,提升多模态大语言模型认知与判别能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 生成式训练 判别式训练 统一训练框架 结构诱导训练 动态时间规整 细粒度语义区分
📋 核心要点
- 现有MLLM生成式训练存在幻觉和弱对象判别问题,判别式训练在细粒度语义区分场景中表现不佳。
- 提出一种统一的训练方法,通过结构诱导训练策略,在输入样本和MLLM隐藏状态间建立语义关系。
- 实验表明,该方法在生成式任务(特别是认知和判别任务)和判别式任务中均取得了SOTA结果。
📝 摘要(中文)
近年来,视觉-语言模型(VLM)主要在两种范式下进行训练。生成式训练使多模态大语言模型(MLLM)能够处理各种复杂任务,但幻觉和弱对象判别等问题仍然存在。判别式训练,以CLIP等模型为例,擅长零样本图像-文本分类和检索,但在需要细粒度语义区分的复杂场景中表现不佳。本文提出了一种统一的方法,整合了两种范式的优点,以解决这些挑战。考虑到交错的图像-文本序列作为输入样本的通用格式,我们引入了一种结构诱导训练策略,该策略在输入样本和MLLM的隐藏状态之间施加语义关系。这种方法增强了MLLM捕获全局语义和区分细粒度语义的能力。通过利用动态时间规整框架内的动态序列对齐,并集成一种用于细粒度语义区分的新型核函数,我们的方法有效地平衡了生成式和判别式任务。大量的实验表明了我们方法的有效性,在多个生成式任务中取得了最先进的结果,尤其是在那些需要认知和判别能力的任务中。此外,我们的方法在交错和细粒度检索任务中超越了判别式基准。通过采用检索增强生成策略,我们的方法进一步提高了单个模型在某些生成任务中的性能,为视觉-语言建模的未来研究提供了一个有希望的方向。
🔬 方法详解
问题定义:现有视觉-语言模型(VLM)的训练主要分为生成式和判别式两种范式。生成式模型擅长复杂任务,但容易产生幻觉,且对象判别能力较弱。判别式模型在零样本分类和检索方面表现出色,但在需要细粒度语义区分的场景中存在不足。因此,如何结合两种范式的优势,提升模型在各种任务中的性能,是一个亟待解决的问题。
核心思路:本文的核心思路是将生成式和判别式训练统一到一个框架中。通过引入结构诱导训练策略,在输入样本(交错的图像-文本序列)和MLLM的隐藏状态之间建立语义关系,从而增强模型捕获全局语义和区分细粒度语义的能力。这种统一的训练方式旨在平衡生成式任务和判别式任务,使模型在各种任务中都能表现出色。
技术框架:该方法将交错的图像-文本序列作为输入,通过MLLM进行处理。关键在于结构诱导训练策略,它在输入样本和MLLM的隐藏状态之间施加语义关系。为了实现这一目标,论文采用了动态时间规整(Dynamic Time Warping,DTW)框架内的动态序列对齐,以及一种用于细粒度语义区分的新型核函数。整体流程包括数据输入、特征提取、序列对齐、语义关系建模和损失计算等步骤。
关键创新:该方法最重要的创新点在于统一了生成式和判别式训练,并提出了结构诱导训练策略。与传统的单一范式训练方法相比,该方法能够更好地利用两种范式的优势,提升模型在各种任务中的性能。此外,动态序列对齐和新型核函数的设计也为细粒度语义区分提供了有效的工具。
关键设计:结构诱导训练策略是关键设计之一,它通过特定的损失函数来约束输入样本和MLLM隐藏状态之间的语义关系。动态时间规整(DTW)用于对齐图像-文本序列,确保模型能够捕捉到序列中的关键信息。新型核函数的设计旨在增强模型对细粒度语义的区分能力。具体的参数设置和损失函数形式在论文中进行了详细描述,但具体数值未知。
🖼️ 关键图片
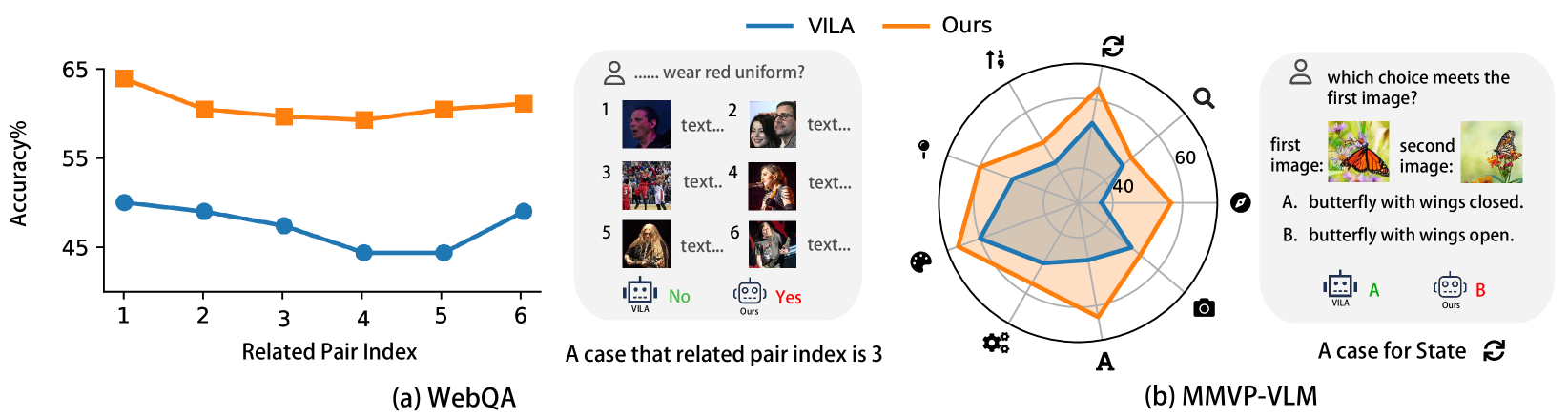


📊 实验亮点
实验结果表明,该方法在多个生成式任务中取得了state-of-the-art的结果,尤其是在需要认知和判别能力的任务中。此外,该方法在交错和细粒度检索任务中也超越了判别式基准。通过检索增强生成策略,该方法进一步提高了单个模型在某些生成任务中的性能。具体的性能提升幅度和对比基线在论文中有详细描述,但具体数值未知。
🎯 应用场景
该研究成果可广泛应用于多模态信息处理领域,例如智能问答、图像描述、视觉推理、跨模态检索等。在实际应用中,可以提升机器人在复杂环境中的感知和交互能力,改善人机交互体验,并为智能医疗、智能安防等领域提供更强大的技术支持。未来,该方法有望推动多模态大语言模型在更广泛的应用场景中落地。
📄 摘要(原文)
In recent times, Vision-Language Models (VLMs) have been trained under two predominant paradigms. Generative training has enabled Multimodal Large Language Models (MLLMs) to tackle various complex tasks, yet issues such as hallucinations and weak object discrimination persist. Discriminative training, exemplified by models like CLIP, excels in zero-shot image-text classification and retrieval, yet struggles with complex scenarios requiring fine-grained semantic differentiation. This paper addresses these challenges by proposing a unified approach that integrates the strengths of both paradigms. Considering interleaved image-text sequences as the general format of input samples, we introduce a structure-induced training strategy that imposes semantic relationships between input samples and the MLLM's hidden state. This approach enhances the MLLM's ability to capture global semantics and distinguish fine-grained semantics. By leveraging dynamic sequence alignment within the Dynamic Time Warping framework and integrating a novel kernel for fine-grained semantic differentiation, our method effectively balances generative and discriminative tasks. Extensive experiments demonstrate the effectiveness of our approach, achieving state-of-the-art results in multiple generative tasks, especially those requiring cognitive and discrimination abilities. Additionally, our method surpasses discriminative benchmarks in interleaved and fine-grained retrieval tasks. By employing a retrieval-augmented generation strategy, our approach further enhances performance in some generative tasks within one model, offering a promising direction for future research in vision-language modeling.