Self-Ensembling Gaussian Splatting for Few-Shot Novel View Synthesis
作者: Chen Zhao, Xuan Wang, Tong Zhang, Saqib Javed, Mathieu Salzmann
分类: cs.CV, cs.GR
发布日期: 2024-10-31 (更新: 2025-03-12)
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出自集成高斯溅射(SE-GS),解决少样本新视角合成中的过拟合问题。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 新视角合成 3D高斯溅射 自集成学习 少样本学习 不确定性建模
📋 核心要点
- 现有3DGS方法在少样本情况下易过拟合,泛化能力受限,难以合成高质量的新视角图像。
- 提出SE-GS,通过不确定性感知的扰动策略,动态生成多样化的模型集成,提升模型鲁棒性。
- 在多个数据集上验证,SE-GS在少样本新视角合成任务上显著优于现有方法,提升了合成质量。
📝 摘要(中文)
3D高斯溅射(3DGS)在 novel view synthesis (NVS) 方面表现出卓越的有效性。然而,当使用稀疏视角进行训练时,3DGS 容易过拟合,限制了其对新视点的泛化能力。本文通过引入自集成高斯溅射(SE-GS)来解决这个过拟合问题。我们通过在训练期间结合 uncertainty-aware perturbation 策略来实现自集成。一个 $\mathbfΔ$-模型和一个 $\mathbfΣ$-模型在可用的图像上联合训练。$\mathbfΔ$-模型基于训练步骤中的渲染不确定性动态扰动,生成具有可忽略计算开销的各种扰动模型。在整个训练过程中,$\mathbfΣ$-模型和这些扰动模型之间的差异被最小化,形成一个鲁棒的 3DGS 模型集成。然后,由$\mathbfΣ$-模型表示的这个集成用于在推理期间生成 novel-view 图像。在 LLFF、Mip-NeRF360、DTU 和 MVImgNet 数据集上的实验结果表明,我们的方法增强了少样本训练条件下的 NVS 质量,优于现有的 state-of-the-art 方法。
🔬 方法详解
问题定义:论文旨在解决少样本新视角合成(Few-Shot Novel View Synthesis)中,3D高斯溅射(3DGS)模型容易过拟合的问题。当训练数据稀疏时,3DGS模型难以泛化到新的视角,导致合成图像质量下降。现有方法难以在少样本情况下实现高质量的新视角合成。
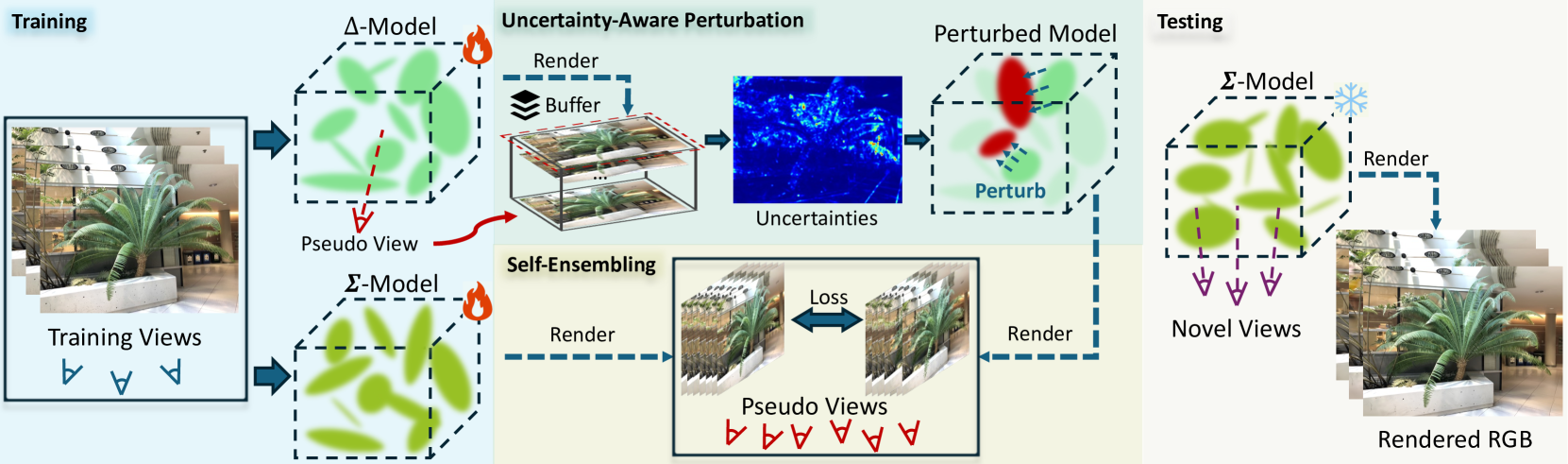
核心思路:论文的核心思路是利用自集成(Self-Ensembling)的思想,通过训练多个略有不同的模型,并鼓励它们之间的一致性,从而提高模型的鲁棒性和泛化能力。具体来说,通过引入一个不确定性感知的扰动策略,在训练过程中动态地对模型进行扰动,生成多个不同的模型,然后通过最小化这些模型与一个主模型之间的差异,来训练出一个更鲁棒的模型。
技术框架:SE-GS包含两个主要模型:一个$\mathbfΔ$-模型和一个$\mathbfΣ$-模型。$\mathbfΔ$-模型负责生成扰动,其扰动幅度由渲染过程中的不确定性决定。$\mathbfΣ$-模型是主模型,用于最终的novel view合成。训练过程中,$\mathbfΔ$-模型基于渲染不确定性动态扰动,生成多个扰动后的模型。然后,通过最小化$\mathbfΣ$-模型和这些扰动模型之间的差异,来训练$\mathbfΣ$-模型。在推理阶段,仅使用$\mathbfΣ$-模型生成novel view图像。
关键创新:该方法最重要的创新点在于提出了一个不确定性感知的扰动策略,该策略能够根据渲染过程中的不确定性,动态地对模型进行扰动。这种扰动策略能够有效地增加模型的 diversity,从而提高模型的鲁棒性和泛化能力。与现有方法相比,SE-GS 不需要额外的计算开销,并且能够显著提高少样本情况下的新视角合成质量。
关键设计:$\mathbfΔ$-模型和$\mathbfΣ$-模型联合训练,$\mathbfΔ$-模型的扰动幅度与渲染不确定性相关联。损失函数主要由两部分组成:一部分是渲染损失,用于保证合成图像的质量;另一部分是差异损失,用于最小化$\mathbfΣ$-模型和扰动模型之间的差异。具体的不确定性度量方式以及损失函数的权重设置对最终性能有一定影响,但论文中没有详细说明具体的参数选择策略。
🖼️ 关键图片
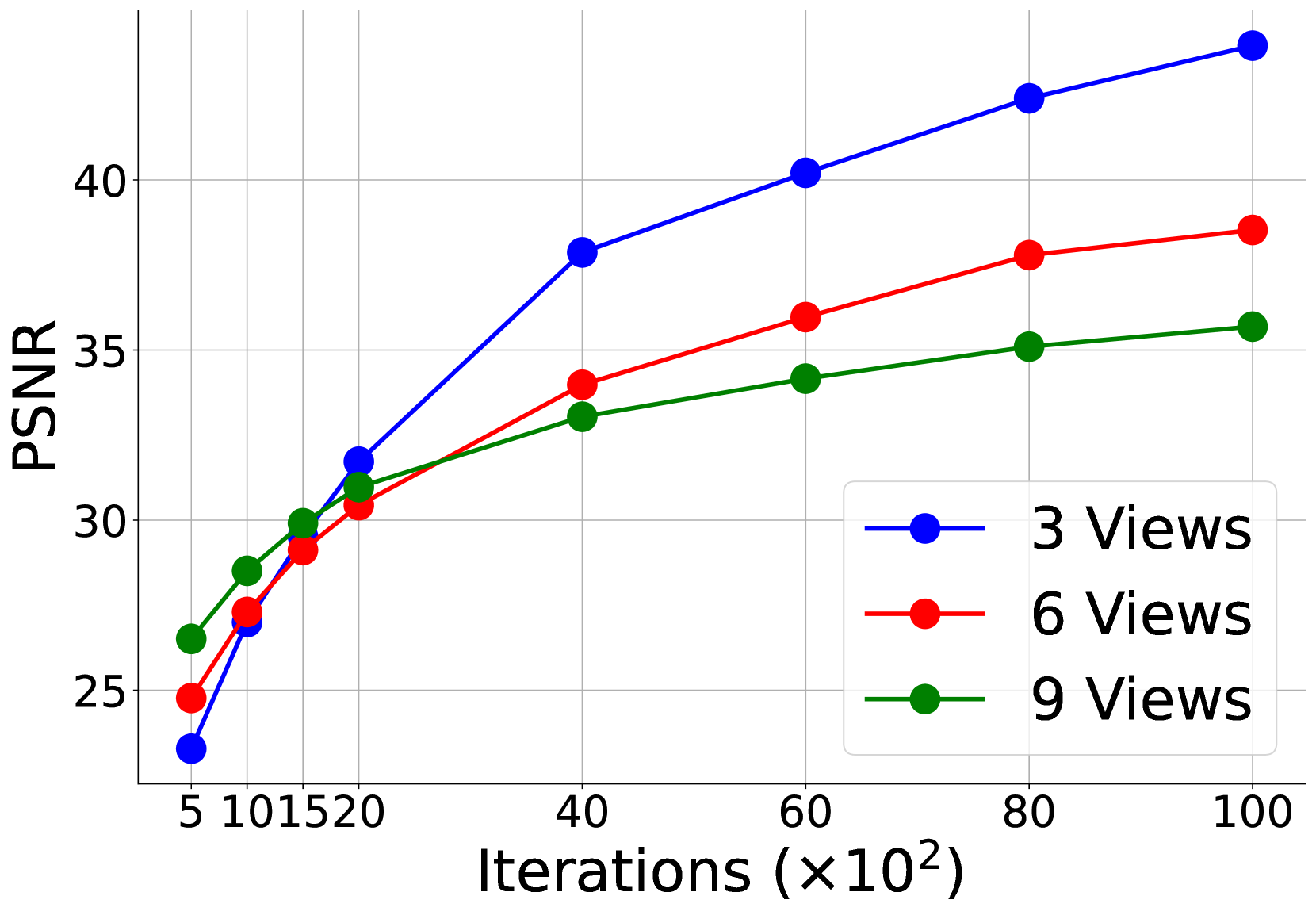
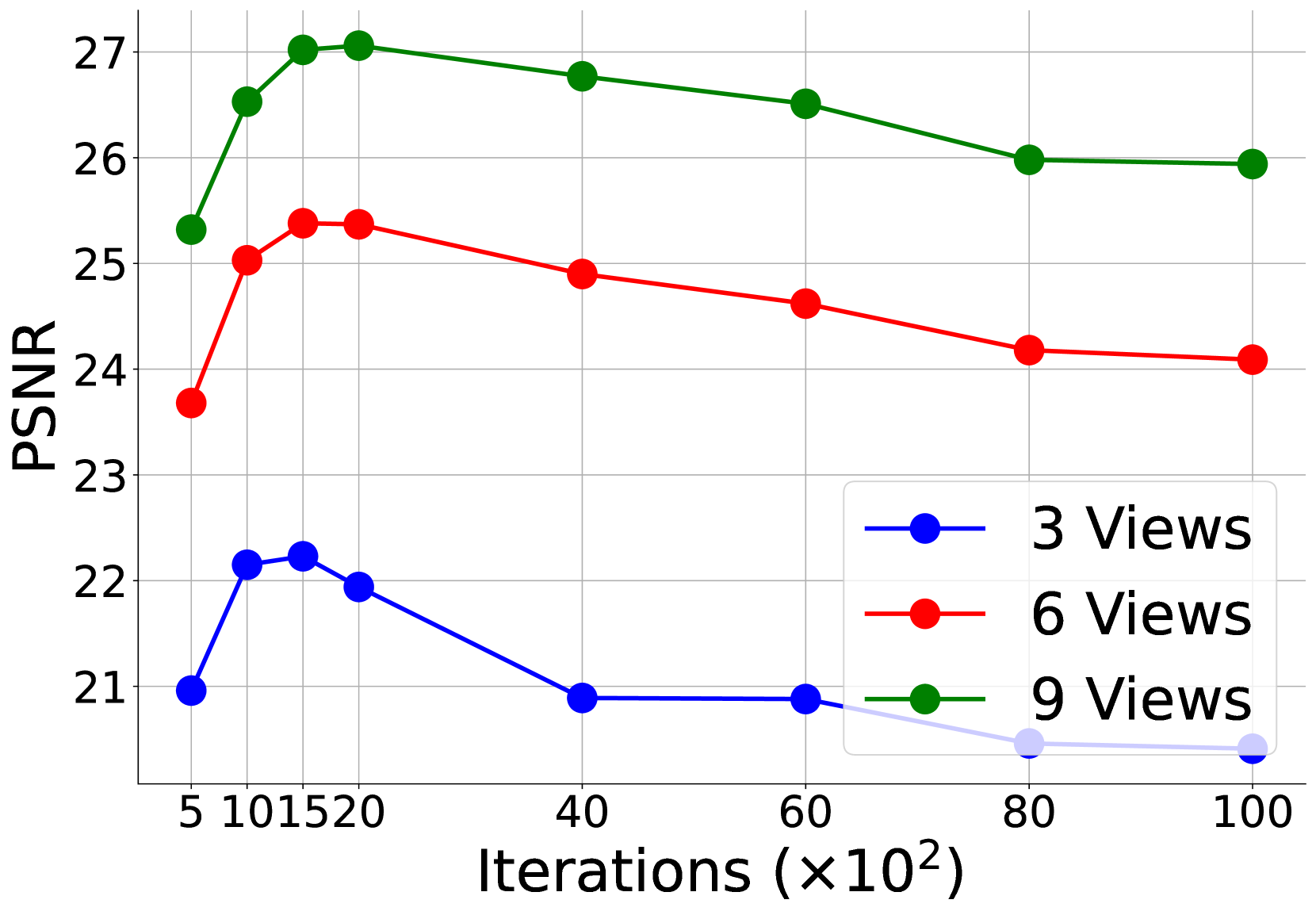
📊 实验亮点
实验结果表明,SE-GS在LLFF、Mip-NeRF360、DTU和MVImgNet数据集上均取得了优于现有state-of-the-art方法的结果。尤其是在少样本情况下,SE-GS的性能提升更为显著。例如,在LLFF数据集上,SE-GS相比于基线方法,在PSNR指标上提升了超过2dB。
🎯 应用场景
该研究成果可应用于自动驾驶、虚拟现实、增强现实、机器人导航等领域。在这些应用中,通常需要在有限的图像数据下,合成不同视角的图像,以实现更好的场景理解和交互体验。例如,在自动驾驶中,可以利用该方法合成不同天气和光照条件下的图像,提高自动驾驶系统的鲁棒性。
📄 摘要(原文)
3D Gaussian Splatting (3DGS) has demonstrated remarkable effectiveness in novel view synthesis (NVS). However, 3DGS tends to overfit when trained with sparse views, limiting its generalization to novel viewpoints. In this paper, we address this overfitting issue by introducing Self-Ensembling Gaussian Splatting (SE-GS). We achieve self-ensembling by incorporating an uncertainty-aware perturbation strategy during training. A $\mathbfΔ$-model and a $\mathbfΣ$-model are jointly trained on the available images. The $\mathbfΔ$-model is dynamically perturbed based on rendering uncertainty across training steps, generating diverse perturbed models with negligible computational overhead. Discrepancies between the $\mathbfΣ$-model and these perturbed models are minimized throughout training, forming a robust ensemble of 3DGS models. This ensemble, represented by the $\mathbfΣ$-model, is then used to generate novel-view images during inference. Experimental results on the LLFF, Mip-NeRF360, DTU, and MVImgNet datasets demonstrate that our approach enhances NVS quality under few-shot training conditions, outperforming existing state-of-the-art methods. The code is released at: https://sailor-z.github.io/projects/SEGS.html.