Enhancing Motion in Text-to-Video Generation with Decomposed Encoding and Conditioning
作者: Penghui Ruan, Pichao Wang, Divya Saxena, Jiannong Cao, Yuhui Shi
分类: cs.CV
发布日期: 2024-10-31
备注: Accepted at NeurIPS 2024, code available at https://github.com/PR-Ryan/DEMO
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
DEMO:通过解耦编码与条件化增强文本到视频生成中的运动效果
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: 文本到视频生成 运动合成 解耦编码 条件化机制 文本运动监督 视频运动监督 深度学习
📋 核心要点
- 现有文本到视频生成模型难以捕捉文本描述的复杂运动,导致生成视频缺乏动态性。
- DEMO框架通过解耦文本编码和条件化过程,分别处理内容和运动信息,从而增强运动合成。
- 实验结果表明,DEMO在多个基准测试中表现出色,能够生成具有更强运动效果和更高视觉质量的视频。
📝 摘要(中文)
本文提出了一种名为DEcomposed MOtion (DEMO)的新框架,旨在提升文本到视频(T2V)生成中运动合成的质量。现有模型常生成静态或动态性不足的视频,无法捕捉文本描述的复杂运动。DEMO通过将文本编码和条件化过程解耦为内容和运动两个组成部分来解决此问题。该方法包含一个用于静态元素的内容编码器和一个用于时间动态的运动编码器,以及独立的内容和运动条件化机制。此外,引入了文本-运动和视频-运动监督,以提高模型对运动的理解和生成能力。在MSR-VTT、UCF-101、WebVid-10M、EvalCrafter和VBench等基准测试上的评估表明,DEMO能够生成具有增强运动动态且保持高视觉质量的视频。该方法通过直接从文本描述中整合全面的运动理解,显著推进了T2V生成技术。
🔬 方法详解
问题定义:当前文本到视频生成模型在生成具有真实运动的视频方面存在困难。现有方法生成的视频往往是静态的或者运动幅度很小,无法准确地反映文本描述中复杂的运动信息。这主要是由于文本编码器内部的偏差,忽略了运动信息,以及T2V生成模型中条件化机制的不足。
核心思路:DEMO的核心思路是将文本编码和条件化过程解耦为内容和运动两个独立的组成部分。通过分别处理静态的内容信息和动态的运动信息,模型可以更好地理解和生成视频中的运动。
技术框架:DEMO框架包含以下主要模块:1) 内容编码器:用于提取文本中的静态内容信息。2) 运动编码器:用于提取文本中的时间动态信息。3) 内容条件化模块:用于将内容信息融入到视频生成过程中。4) 运动条件化模块:用于将运动信息融入到视频生成过程中。5) 视频生成器:基于内容和运动信息生成最终的视频。
关键创新:DEMO的关键创新在于解耦了文本编码和条件化过程,并引入了文本-运动和视频-运动监督。这种解耦使得模型能够更好地关注和理解运动信息,而监督机制则进一步提高了模型生成运动的能力。与现有方法相比,DEMO能够更准确地捕捉文本描述中的运动信息,并生成具有更真实运动的视频。
关键设计:DEMO的关键设计包括:1) 使用Transformer网络作为内容和运动编码器。2) 设计了专门的文本-运动损失函数和视频-运动损失函数,用于监督模型学习运动信息。3) 采用了自适应的条件化机制,根据内容和运动信息的强度动态地调整其在视频生成过程中的权重。具体参数设置和网络结构细节未在摘要中详细说明,需要参考论文全文。
🖼️ 关键图片
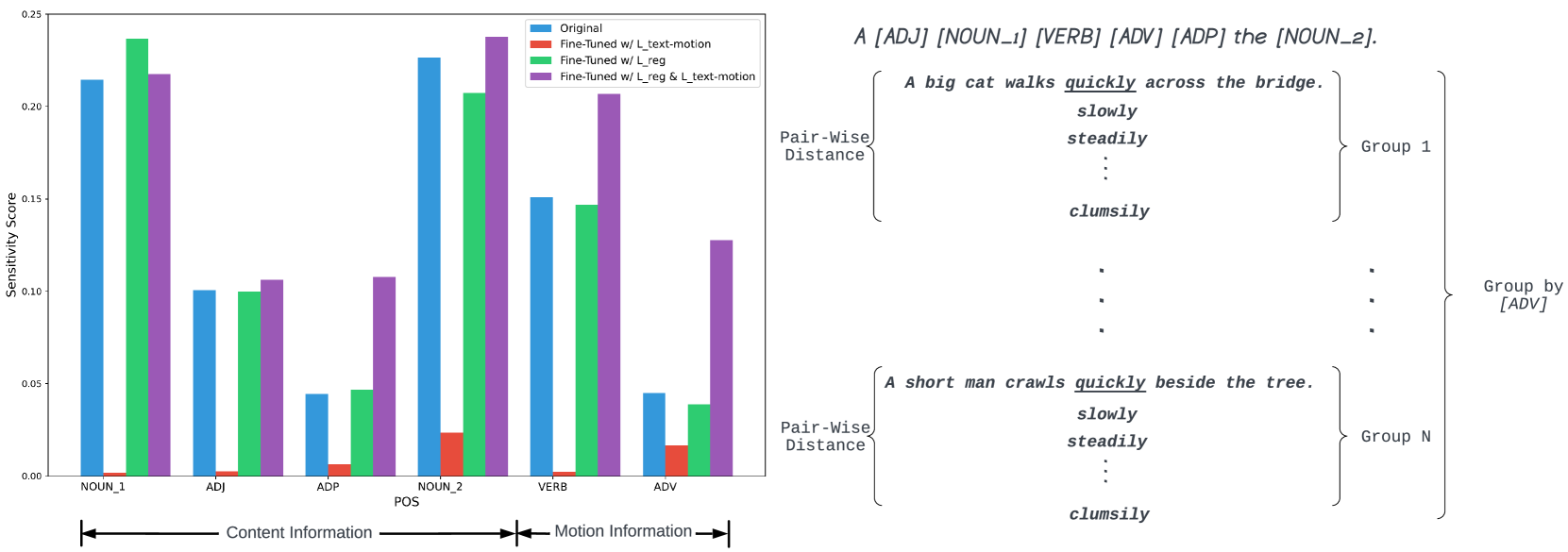


📊 实验亮点
DEMO在MSR-VTT、UCF-101、WebVid-10M、EvalCrafter和VBench等多个基准测试中取得了显著的性能提升。实验结果表明,DEMO能够生成具有更强运动效果和更高视觉质量的视频,证明了其在文本到视频生成任务中的有效性。具体的性能数据和提升幅度需要在论文中查找。
🎯 应用场景
该研究成果可应用于多个领域,如游戏开发、电影制作、虚拟现实和增强现实等。通过DEMO框架,可以更方便地根据文本描述生成具有真实运动的视频,从而降低视频制作的成本和时间。此外,该技术还可以用于教育领域,例如生成教学视频,帮助学生更好地理解抽象概念。
📄 摘要(原文)
Despite advancements in Text-to-Video (T2V) generation, producing videos with realistic motion remains challenging. Current models often yield static or minimally dynamic outputs, failing to capture complex motions described by text. This issue stems from the internal biases in text encoding, which overlooks motions, and inadequate conditioning mechanisms in T2V generation models. To address this, we propose a novel framework called DEcomposed MOtion (DEMO), which enhances motion synthesis in T2V generation by decomposing both text encoding and conditioning into content and motion components. Our method includes a content encoder for static elements and a motion encoder for temporal dynamics, alongside separate content and motion conditioning mechanisms. Crucially, we introduce text-motion and video-motion supervision to improve the model's understanding and generation of motion. Evaluations on benchmarks such as MSR-VTT, UCF-101, WebVid-10M, EvalCrafter, and VBench demonstrate DEMO's superior ability to produce videos with enhanced motion dynamics while maintaining high visual quality. Our approach significantly advances T2V generation by integrating comprehensive motion understanding directly from textual descriptions. Project page: https://PR-Ryan.github.io/DEMO-project/