Handwriting Recognition in Historical Documents with Multimodal LLM
作者: Lucian Li
分类: cs.CV
发布日期: 2024-10-31
💡 一句话要点
利用多模态LLM解决历史手写文档识别难题,探索Gemini模型的潜力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 光学字符识别 多模态大语言模型 手写识别 历史文档 文化遗产保护
📋 核心要点
- 现有手写文档识别方法依赖大量标注数据,且泛化能力弱,难以适应不同书写者。
- 论文探索了多模态LLM(如Gemini)在少量样本提示下的手写文档识别能力。
- 通过实验评估Gemini在手写文档转录任务上的准确性,并与Transformer模型对比。
📝 摘要(中文)
现存大量的历史和文化文档仅以手写稿形式存在。相对于印刷文档的数字化,跨语种和不同手写风格的光学字符识别(OCR)被证明是一个极其困难的问题。虽然最近基于Transformer的模型取得了相对较强的性能,但它们严重依赖于手动转录的训练数据,并且难以在不同的书写者之间泛化。多模态大型语言模型(LLM),如GPT-4v和Gemini,已经证明了它们在少量样本提示下执行OCR和计算机视觉任务的有效性。本文评估了Gemini生成的历史手写文档转录的准确性,并将其与当前最先进的基于Transformer的方法进行了比较。
🔬 方法详解
问题定义:论文旨在解决历史手写文档识别的难题。现有基于Transformer的方法虽然取得了一定的进展,但对大量手动标注的训练数据依赖性强,并且难以泛化到不同的书写者,导致在实际应用中效果不佳。
核心思路:论文的核心思路是利用多模态大型语言模型(LLM)强大的视觉理解和语言生成能力,通过少量样本提示(few-shot prompting)的方式,直接进行手写文档的识别和转录,从而避免对大量标注数据的依赖,并提高模型的泛化能力。
技术框架:论文主要采用Gemini等多模态LLM,输入手写文档图像,通过模型的视觉编码器提取图像特征,然后结合少量样本提示,利用模型的语言解码器生成对应的文本转录结果。整体流程简洁明了,无需复杂的训练过程。
关键创新:论文的关键创新在于将多模态LLM应用于历史手写文档识别领域,并探索了少量样本提示的学习范式。这种方法摆脱了对大量标注数据的依赖,使得模型能够快速适应新的书写风格和语种。
关键设计:论文侧重于评估不同多模态LLM在手写文档识别任务上的性能,并未详细描述模型的具体参数设置、损失函数或网络结构等技术细节。关键在于如何设计有效的少量样本提示,以引导模型生成准确的转录结果。具体提示工程的设计细节未知。
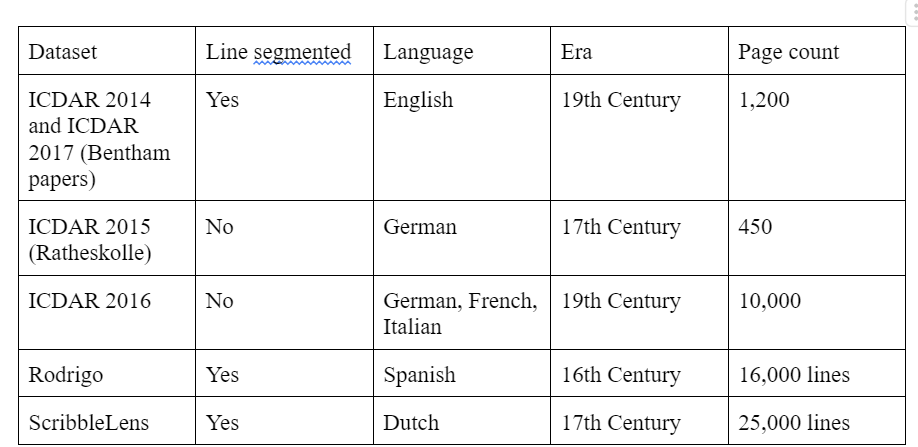
🖼️ 关键图片


📊 实验亮点
论文主要评估了Gemini在手写文档转录任务上的准确性,并与基于Transformer的方法进行了比较。具体的性能数据和提升幅度在摘要中未明确给出,但强调了Gemini在少量样本提示下的有效性,暗示其在一定程度上优于需要大量训练数据的Transformer模型。更详细的实验结果需要在论文正文中查找。
🎯 应用场景
该研究成果可应用于历史文献的数字化保护、古籍整理、档案管理等领域。通过自动识别和转录手写文档,可以大大提高文献整理的效率,降低人工成本,并为历史研究提供更便捷的途径。未来,该技术有望应用于更广泛的手写内容识别场景,例如医疗记录、法律文件等。
📄 摘要(原文)
There is an immense quantity of historical and cultural documentation that exists only as handwritten manuscripts. At the same time, performing OCR across scripts and different handwriting styles has proven to be an enormously difficult problem relative to the process of digitizing print. While recent Transformer based models have achieved relatively strong performance, they rely heavily on manually transcribed training data and have difficulty generalizing across writers. Multimodal LLM, such as GPT-4v and Gemini, have demonstrated effectiveness in performing OCR and computer vision tasks with few shot prompting. In this paper, I evaluate the accuracy of handwritten document transcriptions generated by Gemini against the current state of the art Transformer based methods. Keywords: Optical Character Recognition, Multimodal Language Models, Cultural Preservation, Mass digitization, Handwriting Recognitio