EZ-HOI: VLM Adaptation via Guided Prompt Learning for Zero-Shot HOI Detection
作者: Qinqian Lei, Bo Wang, Robby T. Tan
分类: cs.CV
发布日期: 2024-10-31 (更新: 2024-12-19)
备注: Accepted by NeurIPS 2024
🔗 代码/项目: GITHUB
💡 一句话要点
提出EZ-HOI,通过引导式Prompt学习实现零样本HOI检测中的VLM自适应
🎯 匹配领域: 支柱五:交互与反应 (Interaction & Reaction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 零样本学习 人-物交互检测 视觉-语言模型 Prompt学习 大语言模型
📋 核心要点
- 现有零样本HOI检测方法依赖大型VLM,计算成本高且训练困难,泛化性不足。
- EZ-HOI通过LLM和VLM引导Prompt学习,利用已见类别信息辅助未见类别学习,提升VLM对HOI任务的适应性。
- 实验表明,EZ-HOI在零样本HOI检测中取得了SOTA性能,且训练参数显著减少。
📝 摘要(中文)
本文提出了一种新颖的基于Prompt学习的框架,用于高效的零样本人-物交互(HOI)检测,称为EZ-HOI。现有方法依赖于将视觉编码器与大型视觉-语言模型(VLM)对齐,以利用VLM的广泛知识,但需要大型、计算成本高的模型,并且面临训练困难。EZ-HOI通过LLM和VLM引导可学习的Prompt,整合详细的HOI描述和视觉语义,使VLM适应HOI任务。针对训练数据集仅包含已见类别标签的问题,EZ-HOI利用来自相关已见类别的信息,为未见类别设计Prompt学习,并使用LLM突出未见类别和相关已见类别之间的差异。在基准数据集上的定量评估表明,与现有方法相比,EZ-HOI在各种零样本设置下实现了最先进的性能,且可训练参数仅为现有方法的10.35%至33.95%。
🔬 方法详解
问题定义:零样本HOI检测旨在检测模型未见过的HOI类别。现有方法通常需要训练大型VLM或对视觉编码器进行对齐,计算成本高昂,且容易过拟合已见类别,导致在未见类别上的性能不佳。这些方法难以充分利用VLM的先验知识,泛化能力受限。
核心思路:本文的核心思路是利用Prompt学习,通过少量可学习的参数来引导VLM适应HOI检测任务。为了解决训练数据集中只有已见类别标签的问题,本文利用LLM的知识,将已见类别的信息迁移到未见类别,从而提升模型在未见类别上的检测性能。通过这种方式,可以更有效地利用VLM的先验知识,并减少对大量训练数据的依赖。
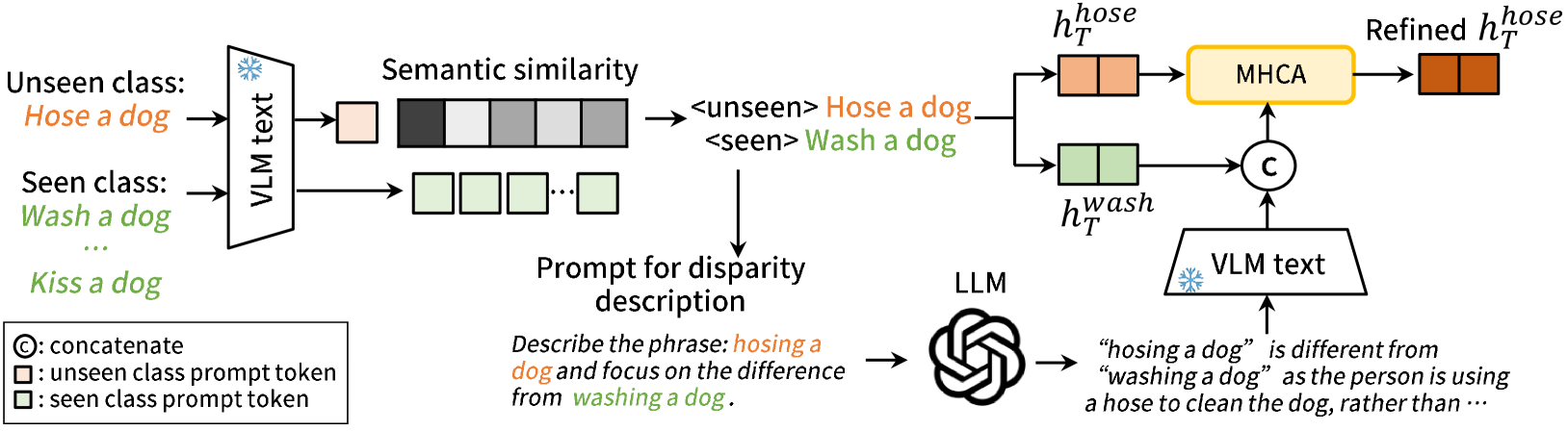
技术框架:EZ-HOI框架主要包含以下几个模块:1) VLM和LLM引导的Prompt生成模块,用于生成可学习的Prompt,将HOI描述和视觉语义信息融入VLM;2) 基于已见类别信息的未见类别Prompt学习模块,利用LLM突出已见类别和未见类别之间的差异,从而指导未见类别的Prompt学习;3) HOI检测模块,利用学习到的Prompt对图像中的HOI进行检测。整体流程是先利用LLM和VLM生成初始Prompt,然后利用已见类别信息对未见类别的Prompt进行优化,最后利用学习到的Prompt进行HOI检测。
关键创新:本文最重要的技术创新点在于利用LLM的知识来指导Prompt学习,从而实现更好的零样本HOI检测性能。与现有方法相比,EZ-HOI不需要训练大型VLM或对视觉编码器进行对齐,而是通过少量可学习的Prompt来引导VLM适应HOI检测任务。此外,EZ-HOI还利用已见类别的信息来辅助未见类别的学习,从而提升模型在未见类别上的泛化能力。
关键设计:在Prompt生成模块中,使用了LLM来生成HOI描述,并利用VLM提取视觉语义信息。在未见类别Prompt学习模块中,设计了一种损失函数,用于衡量已见类别和未见类别之间的差异,并利用该损失函数来优化未见类别的Prompt。具体的参数设置包括Prompt的长度、LLM和VLM的选择等。网络结构主要包括VLM和LLM,以及一些用于Prompt学习的可学习参数。
🖼️ 关键图片


📊 实验亮点
EZ-HOI在多个零样本HOI检测基准数据集上取得了state-of-the-art的性能。例如,在HICO-DET数据集上,EZ-HOI的性能超过了现有方法,并且可训练参数仅为现有方法的10.35%至33.95%。这些结果表明,EZ-HOI是一种高效且有效的零样本HOI检测方法。
🎯 应用场景
该研究成果可应用于智能监控、机器人交互、自动驾驶等领域。例如,在智能监控中,可以利用该技术自动检测视频中人与物体的交互行为,从而实现更智能的安全监控。在机器人交互中,可以使机器人更好地理解人类的意图,从而实现更自然的人机交互。在自动驾驶中,可以帮助车辆更好地理解周围环境,从而提高驾驶安全性。
📄 摘要(原文)
Detecting Human-Object Interactions (HOI) in zero-shot settings, where models must handle unseen classes, poses significant challenges. Existing methods that rely on aligning visual encoders with large Vision-Language Models (VLMs) to tap into the extensive knowledge of VLMs, require large, computationally expensive models and encounter training difficulties. Adapting VLMs with prompt learning offers an alternative to direct alignment. However, fine-tuning on task-specific datasets often leads to overfitting to seen classes and suboptimal performance on unseen classes, due to the absence of unseen class labels. To address these challenges, we introduce a novel prompt learning-based framework for Efficient Zero-Shot HOI detection (EZ-HOI). First, we introduce Large Language Model (LLM) and VLM guidance for learnable prompts, integrating detailed HOI descriptions and visual semantics to adapt VLMs to HOI tasks. However, because training datasets contain seen-class labels alone, fine-tuning VLMs on such datasets tends to optimize learnable prompts for seen classes instead of unseen ones. Therefore, we design prompt learning for unseen classes using information from related seen classes, with LLMs utilized to highlight the differences between unseen and related seen classes. Quantitative evaluations on benchmark datasets demonstrate that our EZ-HOI achieves state-of-the-art performance across various zero-shot settings with only 10.35% to 33.95% of the trainable parameters compared to existing methods. Code is available at https://github.com/ChelsieLei/EZ-HOI.