Modality and Task Adaptation for Enhanced Zero-shot Composed Image Retrieval
作者: Haiwen Li, Fei Su, Zhicheng Zhao
分类: cs.CV, cs.IR
发布日期: 2024-10-31 (更新: 2025-08-06)
💡 一句话要点
提出MoTa-Adapter,解决零样本组合图像检索中的模态和任务差异问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 零样本学习 组合图像检索 模态适配 任务适配 大型语言模型 参数高效微调 混合专家网络
📋 核心要点
- 现有ZS-CIR方法依赖反演网络,但反演训练与检索目标不一致,导致任务差异。
- 提出MoTa-Adapter,通过文本锚定三元组构建和参数高效微调,解决模态和任务差异。
- 实验表明,该方法在四个基准测试中显著提升了基于反演的方法的性能,达到SOTA。
📝 摘要(中文)
零样本组合图像检索(ZS-CIR)是一项具有挑战性的视觉-语言任务,旨在通过双模态(图像+文本)查询检索目标图像。典型的ZS-CIR方法采用反演网络生成伪单词token来有效表示输入语义。然而,基于反演的方法存在两个固有的问题:首先,反演训练和CIR推理涉及不同的目标,因此存在任务差异。其次,训练和推理之间的输入特征分布不匹配导致模态差异。为此,我们提出了一个轻量级的后处理框架,包含两个组件:(1)一种新的文本锚定三元组构建流程,利用大型语言模型(LLM)将标准图像-文本数据集转换为三元组数据集,其中文本描述作为每个三元组的目标。(2)MoTa-Adapter,一种新颖的参数高效微调方法,使用我们构建的三元组数据将双编码器适配到CIR任务。具体来说,在文本侧,通过混合专家(MoE)层集成多组可学习的任务提示,以捕获特定于任务的先验并处理不同类型的修改。在图像侧,MoTa-Adapter调制反演网络的输入,以更好地匹配下游文本编码器。此外,提出了一种基于熵的优化策略,为具有挑战性的样本分配更大的权重,从而确保高效的适配。实验表明,通过结合我们提出的组件,基于反演的方法取得了显著的改进,在四个广泛使用的基准测试中达到了最先进的性能。所有数据和代码都将公开。
🔬 方法详解
问题定义:零样本组合图像检索(ZS-CIR)旨在通过组合图像和文本描述来检索目标图像。现有基于反演网络的方法,虽然能生成伪单词token表示输入语义,但存在任务差异和模态差异。任务差异是指反演网络的训练目标(重建输入)与CIR的推理目标(检索匹配)不一致。模态差异是指训练时图像和文本的特征分布与推理时不同,导致性能下降。
核心思路:论文的核心思路是通过一个轻量级的后处理框架,显式地解决任务差异和模态差异。首先,利用大型语言模型(LLM)构建更适合CIR任务的三元组数据集。然后,通过参数高效的微调方法MoTa-Adapter,将预训练的双编码器适配到CIR任务上。MoTa-Adapter在文本侧使用混合专家(MoE)层来学习任务相关的先验知识,在图像侧调制反演网络的输入,使其更好地匹配文本编码器。
技术框架:整体框架包含两个主要部分:1)文本锚定三元组构建流程:利用LLM将图像-文本对转换为三元组,其中文本描述作为锚点,正样本是原始图像,负样本是与文本描述不匹配的图像。2)MoTa-Adapter:一个参数高效的微调模块,包含文本侧的任务提示学习和图像侧的反演网络输入调制。文本侧使用MoE层集成多个任务提示,图像侧通过调制反演网络的输入来减小模态差异。
关键创新:1) 提出文本锚定三元组构建流程,利用LLM生成更适合CIR任务的数据。2) 提出MoTa-Adapter,一种参数高效的微调方法,通过任务提示学习和反演网络输入调制,同时解决任务差异和模态差异。3) 提出基于熵的优化策略,为具有挑战性的样本分配更大的权重,提高训练效率。与现有方法相比,该方法不需要从头训练整个模型,而是通过微调的方式适配预训练模型,更加高效。
关键设计:1) 文本侧的任务提示:使用多个可学习的prompt,并通过MoE层进行集成,以捕获不同类型的修改信息。2) 图像侧的输入调制:通过一个线性层将图像特征映射到与文本特征相同的空间,然后将其添加到反演网络的输入中,从而减小模态差异。3) 基于熵的优化策略:计算每个样本的损失熵,并将其作为权重,用于调整损失函数,使得模型更加关注具有挑战性的样本。
🖼️ 关键图片


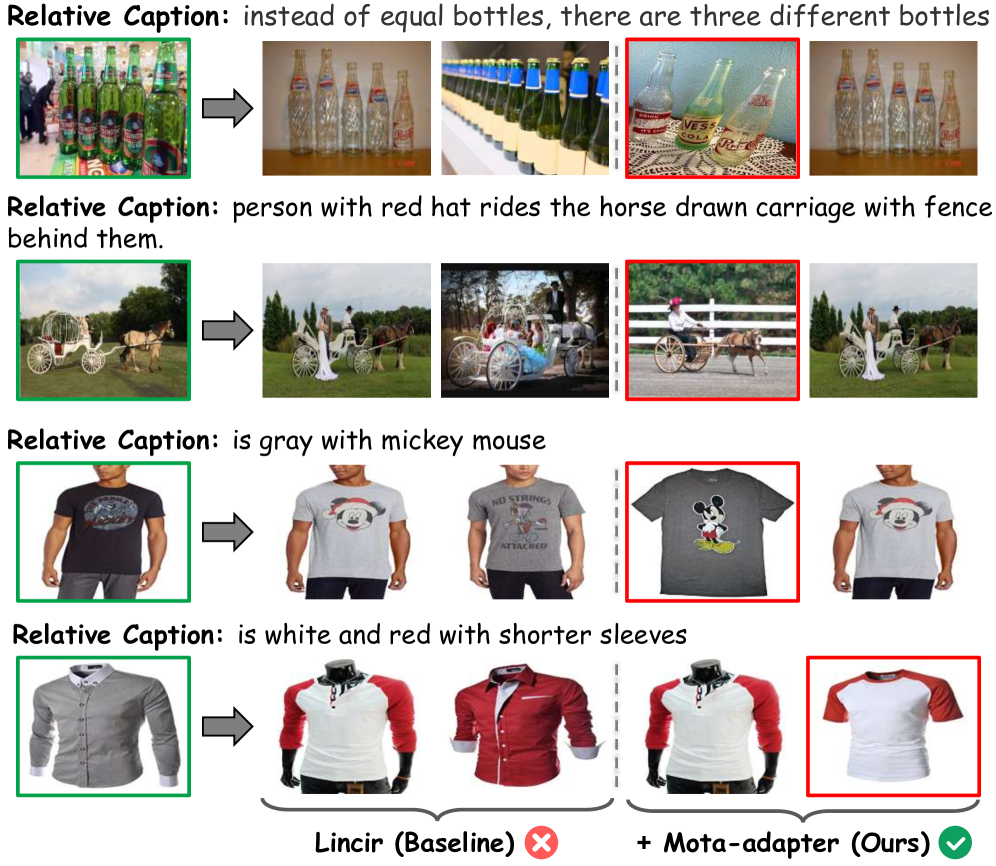
📊 实验亮点
实验结果表明,提出的MoTa-Adapter在四个广泛使用的基准测试(包括MIT-Adobe FiveK, CIRR, Fashion IQ, 和 VSRN)上显著提升了基于反演的方法的性能,达到了state-of-the-art水平。例如,在Fashion IQ数据集上,R@1指标提升了超过5个百分点,证明了该方法的有效性。
🎯 应用场景
该研究成果可应用于智能图像检索、跨模态信息检索、视觉问答等领域。例如,用户可以通过上传一张图片并添加文本描述(如“把这件红色的衣服换成蓝色”)来检索类似的图像。该技术在电商、搜索引擎、智能客服等领域具有广泛的应用前景,能够提升用户体验和信息检索效率。
📄 摘要(原文)
As a challenging vision-language task, Zero-Shot Composed Image Retrieval (ZS-CIR) is designed to retrieve target images using bi-modal (image+text) queries. Typical ZS-CIR methods employ an inversion network to generate pseudo-word tokens that effectively represent the input semantics. However, the inversion-based methods suffer from two inherent issues: First, the task discrepancy exists because inversion training and CIR inference involve different objectives. Second, the modality discrepancy arises from the input feature distribution mismatch between training and inference. To this end, we propose a lightweight post-hoc framework, consisting of two components: (1) A new text-anchored triplet construction pipeline leverages a large language model (LLM) to transform a standard image-text dataset into a triplet dataset, where a textual description serves as the target of each triplet. (2) The MoTa-Adapter, a novel parameter-efficient fine-tuning method, adapts the dual encoder to the CIR task using our constructed triplet data. Specifically, on the text side, multiple sets of learnable task prompts are integrated via a Mixture-of-Experts (MoE) layer to capture task-specific priors and handle different types of modifications. On the image side, MoTa-Adapter modulates the inversion network's input to better match the downstream text encoder. In addition, an entropy-based optimization strategy is proposed to assign greater weight to challenging samples, thus ensuring efficient adaptation. Experiments show that, with the incorporation of our proposed components, inversion-based methods achieve significant improvements, reaching state-of-the-art performance across four widely-used benchmarks. All data and code will be made publicly available.