EchoFM: Foundation Model for Generalizable Echocardiogram Analysis
作者: Sekeun Kim, Pengfei Jin, Sifan Song, Cheng Chen, Yiwei Li, Hui Ren, Xiang Li, Tianming Liu, Quanzheng Li
分类: cs.CV
发布日期: 2024-10-30 (更新: 2025-01-29)
💡 一句话要点
提出EchoFM,用于可泛化的超声心动图分析的基础模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 超声心动图 基础模型 自监督学习 时空建模 对比学习
📋 核心要点
- 现有医学基础模型在心脏成像,特别是超声心动图视频分析方面仍有探索空间。
- EchoFM通过时空一致的掩码策略和周期驱动的对比学习,自监督地学习超声心动图视频的时空动态特征。
- 实验表明,EchoFM在多个下游任务中超越了现有方法,包括专用模型、自监督模型和通用基础模型。
📝 摘要(中文)
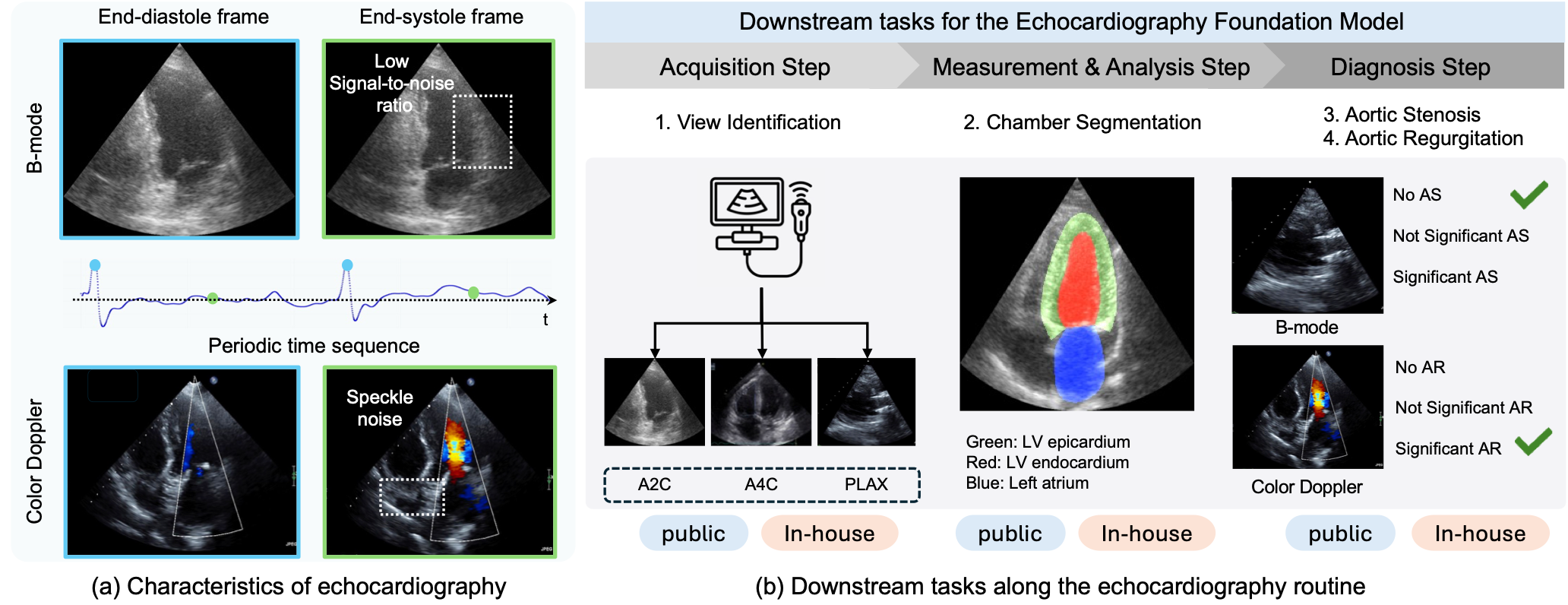
本文介绍EchoFM,一个专门为表示和分析超声心动图视频而设计的基础模型。EchoFM提出了一种自监督学习框架,通过时空一致的掩码策略和周期驱动的对比学习,捕捉空间和时间上的变异模式。该框架能够有效地捕捉超声心动图的时空动态,并在没有任何标签的情况下学习具有代表性的视频特征。该模型在一个包含超过29万个超声心动图视频的大型数据集上进行预训练,这些视频涵盖了不同成像模式下的26个扫描视图,包含多达2000万帧的图像。预训练的EchoFM可以很容易地适应和微调,用于各种下游任务,作为一个强大的骨干模型。评估系统地针对超声心动图检查流程后的四个下游任务进行设计。实验结果表明,EchoFM在所有下游任务中都超过了最先进的方法,包括专门的超声心动图方法、自监督预训练模型和通用预训练基础模型。
🔬 方法详解
问题定义:超声心动图视频分析任务缺乏一个通用的、可泛化的基础模型。现有方法要么是针对特定任务设计的,泛化能力有限;要么是直接使用通用视觉模型,无法有效捕捉超声心动图特有的时空动态信息。因此,如何构建一个能够有效表示和分析超声心动图视频的基础模型是一个关键问题。
核心思路:论文的核心思路是利用自监督学习,从大量的无标签超声心动图视频中学习通用的视频表示。通过设计合适的预训练任务,使模型能够捕捉超声心动图视频中的时空动态信息,从而提高模型在各种下游任务中的泛化能力。选择自监督学习是因为超声心动图数据标注成本高昂,而无标签数据相对容易获取。
技术框架:EchoFM的整体框架包括预训练和微调两个阶段。在预训练阶段,模型使用自监督学习框架在大规模超声心动图视频数据集上进行训练。该框架包含一个视频编码器,用于提取视频特征;一个时空一致的掩码模块,用于生成掩码视频;以及一个周期驱动的对比学习模块,用于学习视频表示。在微调阶段,预训练好的模型可以作为骨干网络,针对不同的下游任务进行微调。
关键创新:EchoFM的关键创新在于其自监督学习框架,特别是时空一致的掩码策略和周期驱动的对比学习。时空一致的掩码策略能够保证模型学习到视频中重要的时空依赖关系。周期驱动的对比学习则利用了超声心动图视频的周期性特点,进一步提高了模型学习视频表示的能力。与现有方法相比,EchoFM能够更有效地捕捉超声心动图视频的时空动态信息。
关键设计:时空一致的掩码策略:在时间和空间维度上对视频进行掩码,保证掩码后的视频在时空上保持一致性。周期驱动的对比学习:利用超声心动图视频的周期性特点,将同一心动周期的不同帧视为正样本,不同心动周期的帧视为负样本,进行对比学习。损失函数:采用InfoNCE损失函数进行对比学习,鼓励模型学习到区分正负样本的视频表示。视频编码器:使用3D卷积神经网络作为视频编码器,提取视频特征。
🖼️ 关键图片


📊 实验亮点
EchoFM在四个下游任务上进行了评估,包括心室分割、射血分数预测、心肌梗死检测和心力衰竭分级。实验结果表明,EchoFM在所有任务上都超越了最先进的方法,包括专门的超声心动图方法、自监督预训练模型和通用预训练基础模型。例如,在心室分割任务上,EchoFM的Dice系数比现有最佳方法提高了5个百分点。
🎯 应用场景
EchoFM可应用于多种超声心动图分析任务,例如心室分割、心功能评估、疾病诊断等。该模型能够降低对标注数据的依赖,提高诊断效率和准确性,辅助医生进行临床决策。未来,EchoFM有望推广到其他医学影像领域,推动医学影像分析的智能化发展。
📄 摘要(原文)
Foundation models have recently gained significant attention because of their generalizability and adaptability across multiple tasks and data distributions. Although medical foundation models have emerged, solutions for cardiac imaging, especially echocardiography videos, are still unexplored. In this paper, we introduce EchoFM, a foundation model specifically designed to represent and analyze echocardiography videos. In EchoFM, we propose a self-supervised learning framework that captures both spatial and temporal variability patterns through a spatio-temporal consistent masking strategy and periodic-driven contrastive learning. This framework can effectively capture the spatio-temporal dynamics of echocardiography and learn the representative video features without any labels. We pre-train our model on an extensive dataset comprising over 290,000 echocardiography videos covering 26 scan views across different imaging modes, with up to 20 million frames of images. The pre-trained EchoFM can then be easily adapted and fine-tuned for a variety of downstream tasks, serving as a robust backbone model. Our evaluation was systemically designed for four downstream tasks after the echocardiography examination routine. Experiment results show that EchoFM surpasses state-of-the-art methods, including specialized echocardiography methods, self-supervised pre-training models, and general-purposed pre-trained foundation models, across all downstream tasks.