EMMA: End-to-End Multimodal Model for Autonomous Driving
作者: Jyh-Jing Hwang, Runsheng Xu, Hubert Lin, Wei-Chih Hung, Jingwei Ji, Kristy Choi, Di Huang, Tong He, Paul Covington, Benjamin Sapp, Yin Zhou, James Guo, Dragomir Anguelov, Mingxing Tan
分类: cs.CV, cs.AI, cs.CL, cs.LG, cs.RO
发布日期: 2024-10-30 (更新: 2025-09-23)
备注: Accepted by TMLR. Blog post: https://waymo.com/blog/2024/10/introducing-emma/
💡 一句话要点
EMMA:用于自动驾驶的端到端多模态模型,实现规划、感知和道路图构建的统一。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶 多模态学习 端到端模型 大型语言模型 运动规划 目标检测 道路图构建
📋 核心要点
- 现有自动驾驶系统通常依赖于多个独立模块,导致误差累积和优化困难,缺乏全局一致性。
- EMMA将所有输入和输出表示为自然语言,利用大型语言模型的知识,实现多任务联合处理和端到端优化。
- EMMA在运动规划和3D目标检测任务上取得了领先或具有竞争力的结果,验证了其作为通用自动驾驶模型的潜力。
📝 摘要(中文)
本文介绍了一种用于自动驾驶的端到端多模态模型EMMA。EMMA基于Gemini等多模态大型语言模型,直接将原始相机传感器数据映射到各种驾驶相关的输出,包括规划轨迹、感知对象和道路图元素。EMMA通过将所有非传感器输入(例如导航指令和自车状态)和输出(例如轨迹和3D位置)表示为自然语言文本,从而最大限度地利用预训练大型语言模型的知识。这种方法允许EMMA在统一的语言空间中联合处理各种驾驶任务,并使用特定于任务的提示生成每个任务的输出。实验结果表明,EMMA在nuScenes上的运动规划方面取得了最先进的性能,并在Waymo Open Motion Dataset (WOMD)上取得了具有竞争力的结果。EMMA还在Waymo Open Dataset (WOD)上针对相机主导的3D目标检测产生了有竞争力的结果。通过联合训练EMMA进行规划轨迹、目标检测和道路图任务,在所有三个领域都取得了改进,突显了EMMA作为自动驾驶应用通用模型的潜力。希望我们的结果能够激发研究,进一步发展自动驾驶模型架构的最新技术。
🔬 方法详解
问题定义:现有自动驾驶系统通常由多个独立的模块组成,例如感知、预测和规划。这些模块通常是独立训练和优化的,导致误差累积,并且难以实现全局最优。此外,不同模块之间的数据传递和接口设计也增加了系统的复杂性。因此,如何构建一个端到端的多任务模型,实现自动驾驶系统的整体优化,是一个重要的挑战。
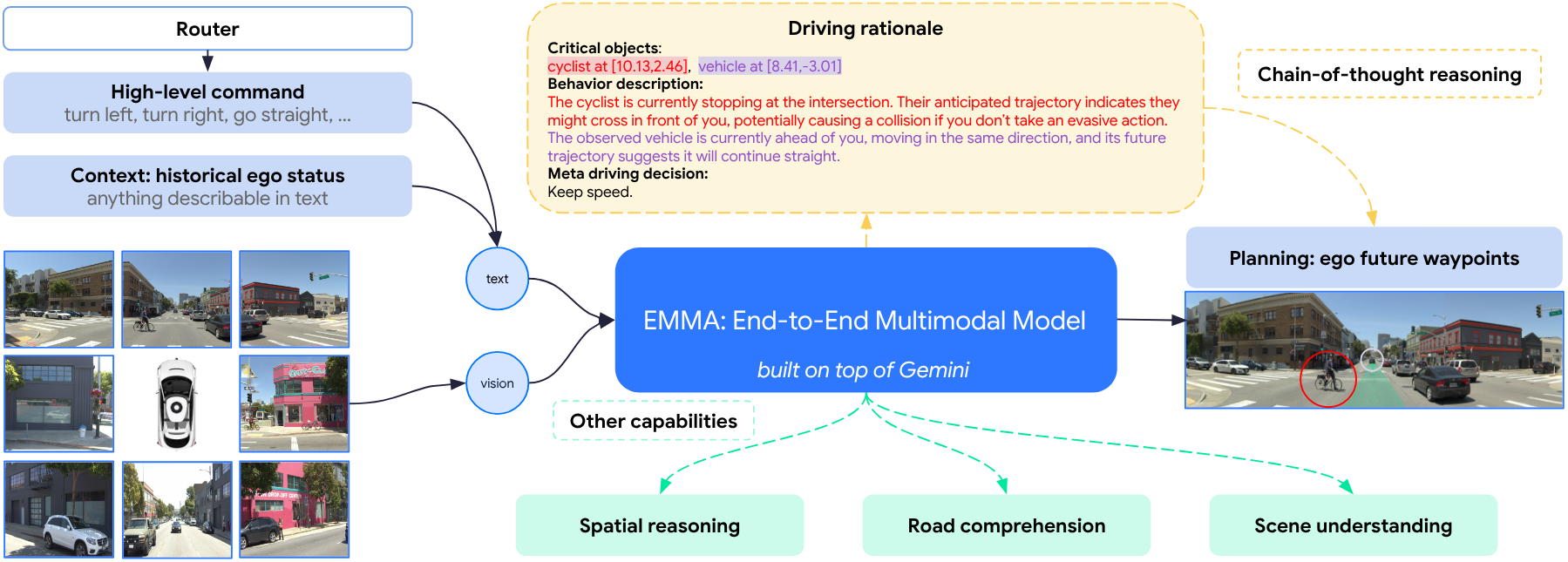
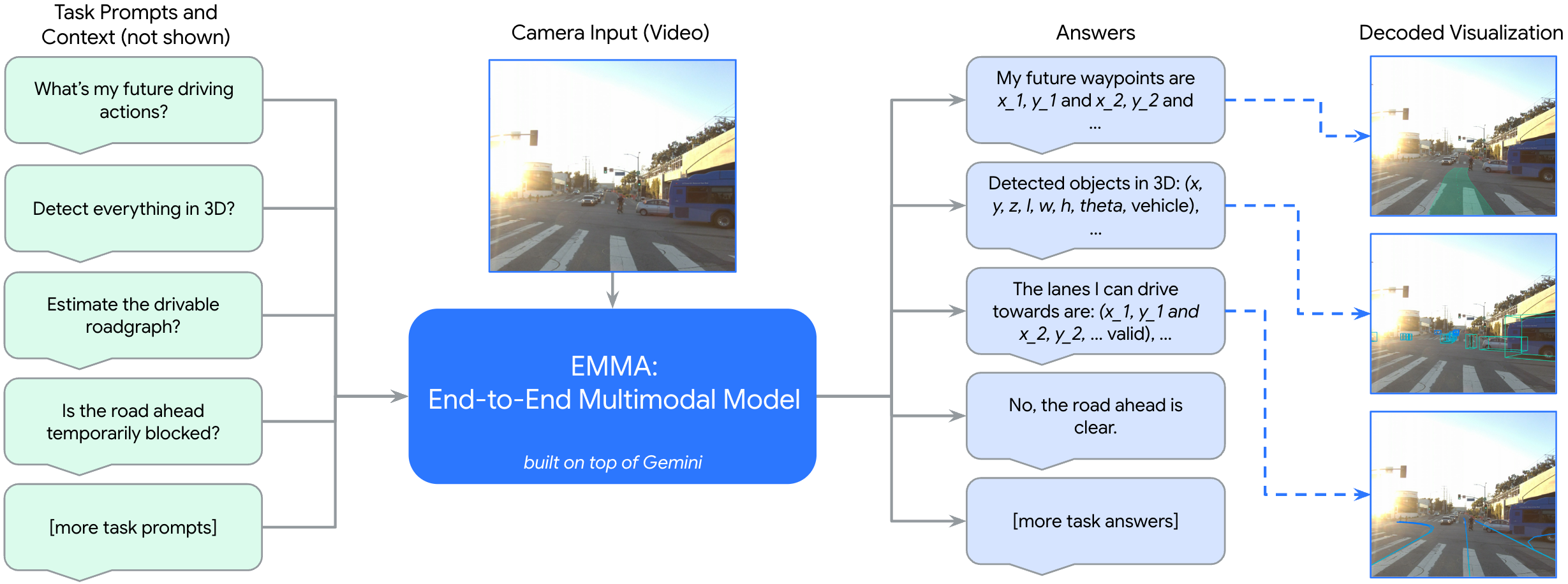
核心思路:EMMA的核心思路是将自动驾驶任务中的所有输入(包括传感器数据、导航指令、自车状态等)和输出(包括轨迹、3D位置、道路图等)都表示为自然语言文本。这样,就可以利用大型语言模型(LLM)强大的语言理解和生成能力,将不同的任务统一到一个语言空间中进行处理。通过使用特定于任务的提示(prompt),可以引导LLM生成特定任务的输出。
技术框架:EMMA的整体架构是一个基于多模态大型语言模型的端到端模型。它主要包含以下几个模块:1) 传感器数据编码器:将原始相机传感器数据编码为特征向量。2) 文本编码器:将导航指令、自车状态等文本信息编码为特征向量。3) 多模态融合模块:将传感器数据和文本信息的特征向量进行融合。4) 大型语言模型:利用融合后的特征向量和特定于任务的提示,生成自然语言形式的输出。5) 输出解码器:将自然语言形式的输出解码为具体的驾驶行为,例如轨迹、3D位置等。
关键创新:EMMA最重要的技术创新点在于将自动驾驶任务中的所有输入和输出都表示为自然语言文本,从而实现了多任务的统一处理。这种方法充分利用了大型语言模型的知识,并且可以方便地扩展到新的任务。与传统的模块化方法相比,EMMA可以实现端到端的优化,从而提高系统的整体性能。
关键设计:EMMA的关键设计包括:1) 使用预训练的多模态大型语言模型(例如Gemini)作为基础模型。2) 设计特定于任务的提示(prompt),以引导LLM生成特定任务的输出。3) 使用对比学习等方法,对传感器数据编码器和文本编码器进行训练,以提高特征向量的表达能力。4) 使用多任务学习的方法,联合训练EMMA进行规划轨迹、目标检测和道路图任务。
🖼️ 关键图片
📊 实验亮点
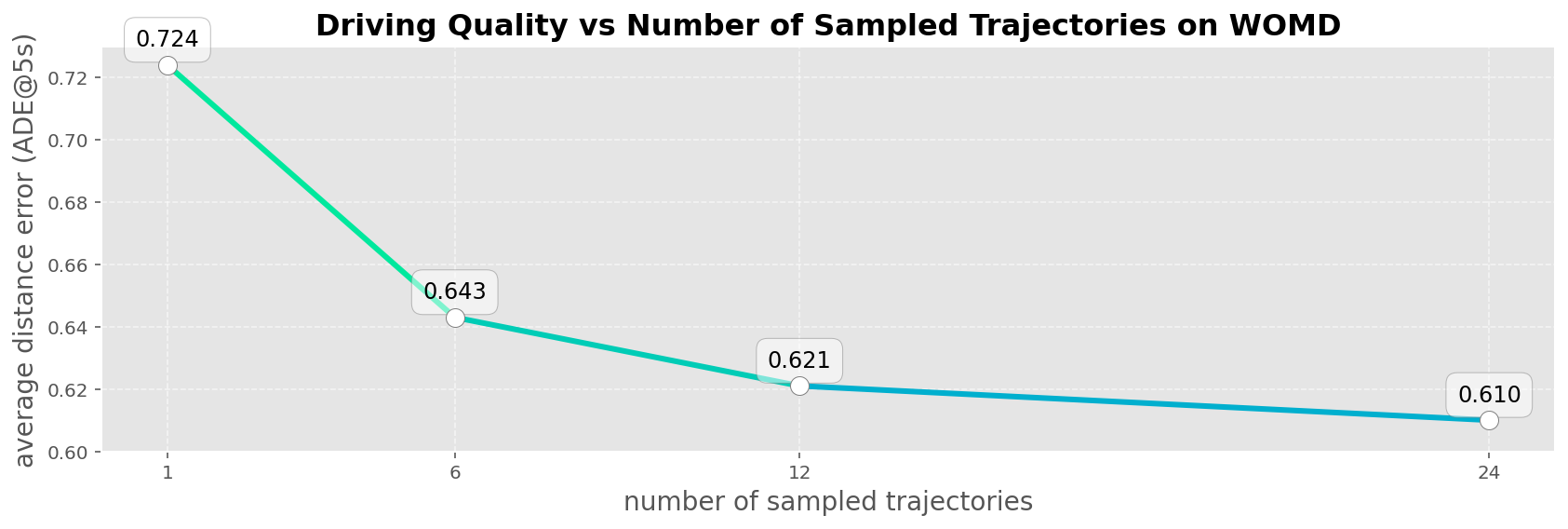
EMMA在nuScenes数据集上实现了最先进的运动规划性能,并在Waymo Open Motion Dataset (WOMD)上取得了具有竞争力的结果。此外,EMMA还在Waymo Open Dataset (WOD)上针对相机主导的3D目标检测产生了有竞争力的结果。通过联合训练EMMA进行规划轨迹、目标检测和道路图任务,在所有三个领域都取得了改进,证明了EMMA作为通用自动驾驶模型的有效性。
🎯 应用场景
EMMA作为一种通用的自动驾驶模型,具有广泛的应用前景。它可以应用于各种自动驾驶场景,例如城市道路、高速公路和越野环境。此外,EMMA还可以用于辅助驾驶系统,例如自动泊车和车道保持。未来,EMMA有望成为自动驾驶系统的核心组件,推动自动驾驶技术的进一步发展。
📄 摘要(原文)
We introduce EMMA, an End-to-end Multimodal Model for Autonomous driving. Built upon a multi-modal large language model foundation like Gemini, EMMA directly maps raw camera sensor data into various driving-specific outputs, including planner trajectories, perception objects, and road graph elements. EMMA maximizes the utility of world knowledge from the pre-trained large language models, by representing all non-sensor inputs (e.g. navigation instructions and ego vehicle status) and outputs (e.g. trajectories and 3D locations) as natural language text. This approach allows EMMA to jointly process various driving tasks in a unified language space, and generate the outputs for each task using task-specific prompts. Empirically, we demonstrate EMMA's effectiveness by achieving state-of-the-art performance in motion planning on nuScenes as well as competitive results on the Waymo Open Motion Dataset (WOMD). EMMA also yields competitive results for camera-primary 3D object detection on the Waymo Open Dataset (WOD). We show that co-training EMMA with planner trajectories, object detection, and road graph tasks yields improvements across all three domains, highlighting EMMA's potential as a generalist model for autonomous driving applications. We hope that our results will inspire research to further evolve the state of the art in autonomous driving model architectures.