LoFLAT: Local Feature Matching using Focused Linear Attention Transformer
作者: Naijian Cao, Renjie He, Yuchao Dai, Mingyi He
分类: cs.CV
发布日期: 2024-10-30
💡 一句话要点
提出LoFLAT:利用聚焦线性注意力Transformer进行局部特征匹配
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱六:视频提取与匹配 (Video Extraction)
关键词: 局部特征匹配 Transformer 线性注意力 图像匹配 深度学习
📋 核心要点
- 现有基于Transformer的局部特征匹配方法在高分辨率图像中计算复杂度高,且难以捕捉局部细节。
- LoFLAT通过聚焦线性注意力机制,在降低计算复杂度的同时,增强了特征表示能力和局部交互。
- 实验结果表明,LoFLAT在效率和准确性上均优于LoFTR,证明了其有效性。
📝 摘要(中文)
局部特征匹配是图像匹配中的一项关键技术,在各种基于视觉的应用中起着至关重要的作用。然而,现有的基于Transformer的无检测器局部特征匹配方法由于注意力机制的二次计算复杂度而面临挑战,尤其是在高分辨率下。虽然现有的方法使用线性注意力机制降低了计算成本,但它们仍然难以捕捉到详细的局部交互,这影响了精确局部对应关系的准确性和鲁棒性。为了在保持低计算复杂度的同时增强注意力机制的表示能力,本文提出了一种新的LoFLAT,即使用聚焦线性注意力Transformer的局部特征匹配方法。我们的LoFLAT由三个主要模块组成:特征提取模块、特征Transformer模块和匹配模块。具体而言,特征提取模块首先使用ResNet和特征金字塔网络来提取分层特征。特征Transformer模块进一步采用聚焦线性注意力,通过聚焦映射函数来细化注意力分布,并通过深度卷积来增强特征多样性。最后,匹配模块通过粗到精的策略预测准确而鲁棒的匹配。大量的实验评估表明,所提出的LoFLAT在效率和准确性方面均优于LoFTR方法。
🔬 方法详解
问题定义:论文旨在解决现有基于Transformer的局部特征匹配方法在高分辨率图像下计算复杂度过高,且难以有效捕捉局部细节的问题。现有方法虽然尝试使用线性注意力降低计算量,但在局部特征交互建模方面仍存在不足,影响了匹配的精度和鲁棒性。
核心思路:论文的核心思路是设计一种聚焦线性注意力机制,在保持线性计算复杂度的前提下,增强Transformer对局部特征交互的建模能力。通过聚焦映射函数细化注意力分布,并利用深度卷积增强特征的多样性,从而提升匹配的准确性和鲁棒性。
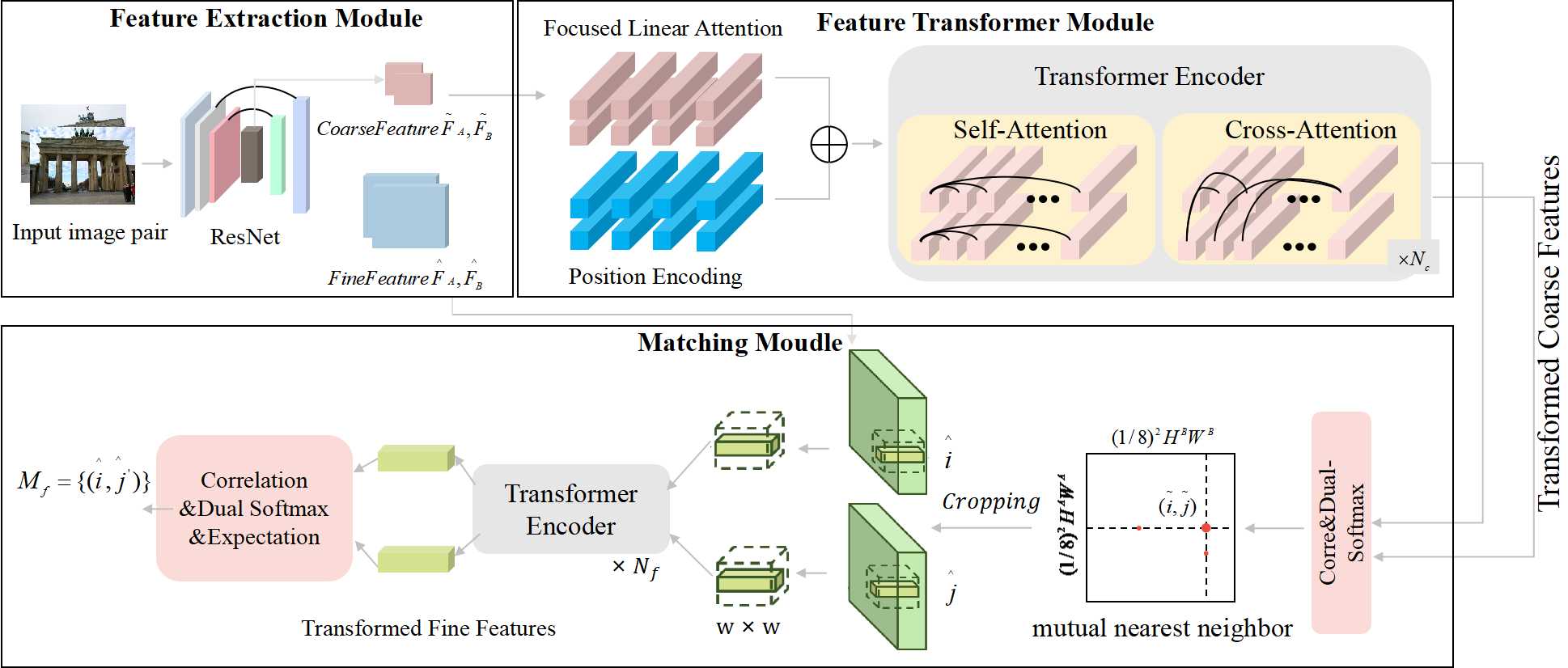
技术框架:LoFLAT包含三个主要模块:特征提取模块、特征Transformer模块和匹配模块。首先,特征提取模块使用ResNet和特征金字塔网络提取多尺度特征。然后,特征Transformer模块利用聚焦线性注意力机制对特征进行增强。最后,匹配模块采用粗到精的策略预测精确的匹配关系。
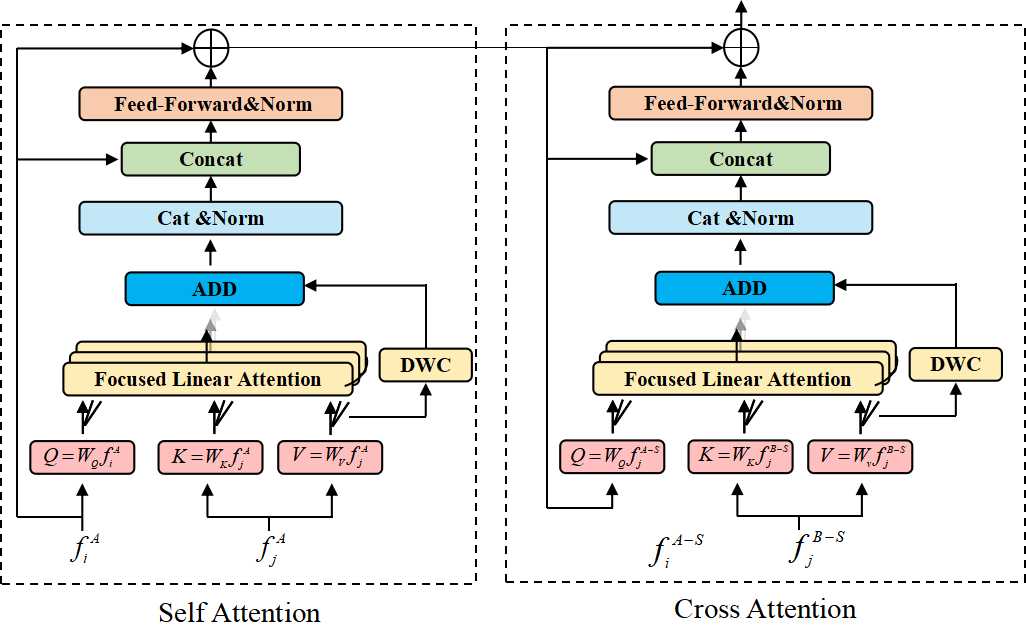
关键创新:LoFLAT的关键创新在于提出的聚焦线性注意力机制。与传统的线性注意力相比,该机制引入了聚焦映射函数,能够更有效地关注重要的局部特征,从而提升特征的区分性和匹配的准确性。同时,深度卷积的引入增强了特征的多样性,进一步提升了模型的鲁棒性。
关键设计:聚焦线性注意力机制中的聚焦映射函数是关键设计之一,其具体形式未知,但其作用是细化注意力分布,使模型更加关注重要的局部特征。此外,深度卷积的具体参数设置也对特征多样性的增强起着重要作用。匹配模块采用粗到精的策略,首先进行粗略的匹配,然后逐步细化,以提高匹配的准确性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LoFLAT在效率和准确性方面均优于LoFTR。具体性能数据未知,但摘要明确指出LoFLAT在两个关键指标上都超越了LoFTR,证明了其在局部特征匹配方面的优越性。该方法在保持低计算复杂度的同时,实现了更高的匹配精度,具有显著的优势。
🎯 应用场景
LoFLAT在图像匹配领域具有广泛的应用前景,例如三维重建、视觉定位、SLAM、图像拼接等。该方法能够提升这些应用在复杂场景下的性能和鲁棒性,具有重要的实际应用价值。未来,可以进一步探索LoFLAT在其他视觉任务中的应用,例如目标检测、图像分割等。
📄 摘要(原文)
Local feature matching is an essential technique in image matching and plays a critical role in a wide range of vision-based applications. However, existing Transformer-based detector-free local feature matching methods encounter challenges due to the quadratic computational complexity of attention mechanisms, especially at high resolutions. However, while existing Transformer-based detector-free local feature matching methods have reduced computational costs using linear attention mechanisms, they still struggle to capture detailed local interactions, which affects the accuracy and robustness of precise local correspondences. In order to enhance representations of attention mechanisms while preserving low computational complexity, we propose the LoFLAT, a novel Local Feature matching using Focused Linear Attention Transformer in this paper. Our LoFLAT consists of three main modules: the Feature Extraction Module, the Feature Transformer Module, and the Matching Module. Specifically, the Feature Extraction Module firstly uses ResNet and a Feature Pyramid Network to extract hierarchical features. The Feature Transformer Module further employs the Focused Linear Attention to refine attention distribution with a focused mapping function and to enhance feature diversity with a depth-wise convolution. Finally, the Matching Module predicts accurate and robust matches through a coarse-to-fine strategy. Extensive experimental evaluations demonstrate that the proposed LoFLAT outperforms the LoFTR method in terms of both efficiency and accuracy.