Dreaming Out Loud: A Self-Synthesis Approach For Training Vision-Language Models With Developmentally Plausible Data
作者: Badr AlKhamissi, Yingtian Tang, Abdülkadir Gökce, Johannes Mehrer, Martin Schrimpf
分类: cs.CV, cs.LG
发布日期: 2024-10-29
备注: Accepted to BabyLM Challenge at CoNLL 2024
💡 一句话要点
提出一种自合成方法,利用类人认知发展方式训练视觉-语言模型。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 自监督学习 认知发展 数据增强 多模态学习
📋 核心要点
- 现有大型语言模型需要海量数据进行训练,限制了其在数据稀缺场景下的应用。
- 论文提出一种自合成方法,模拟人类认知发展过程,通过迭代训练提升模型性能。
- 该方法在有限数据条件下,验证了多模态模型训练的可行性,为未来研究提供参考。
📝 摘要(中文)
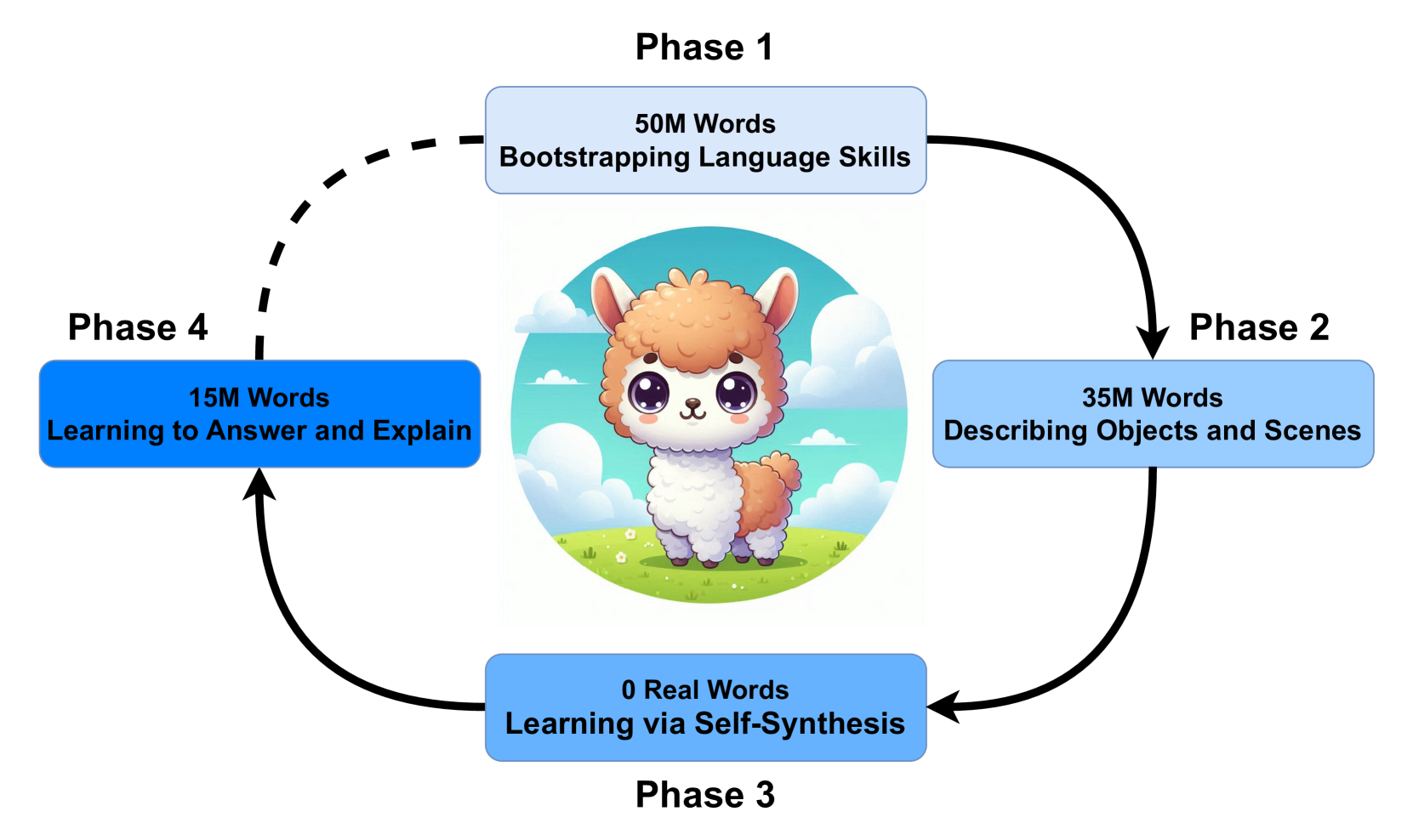
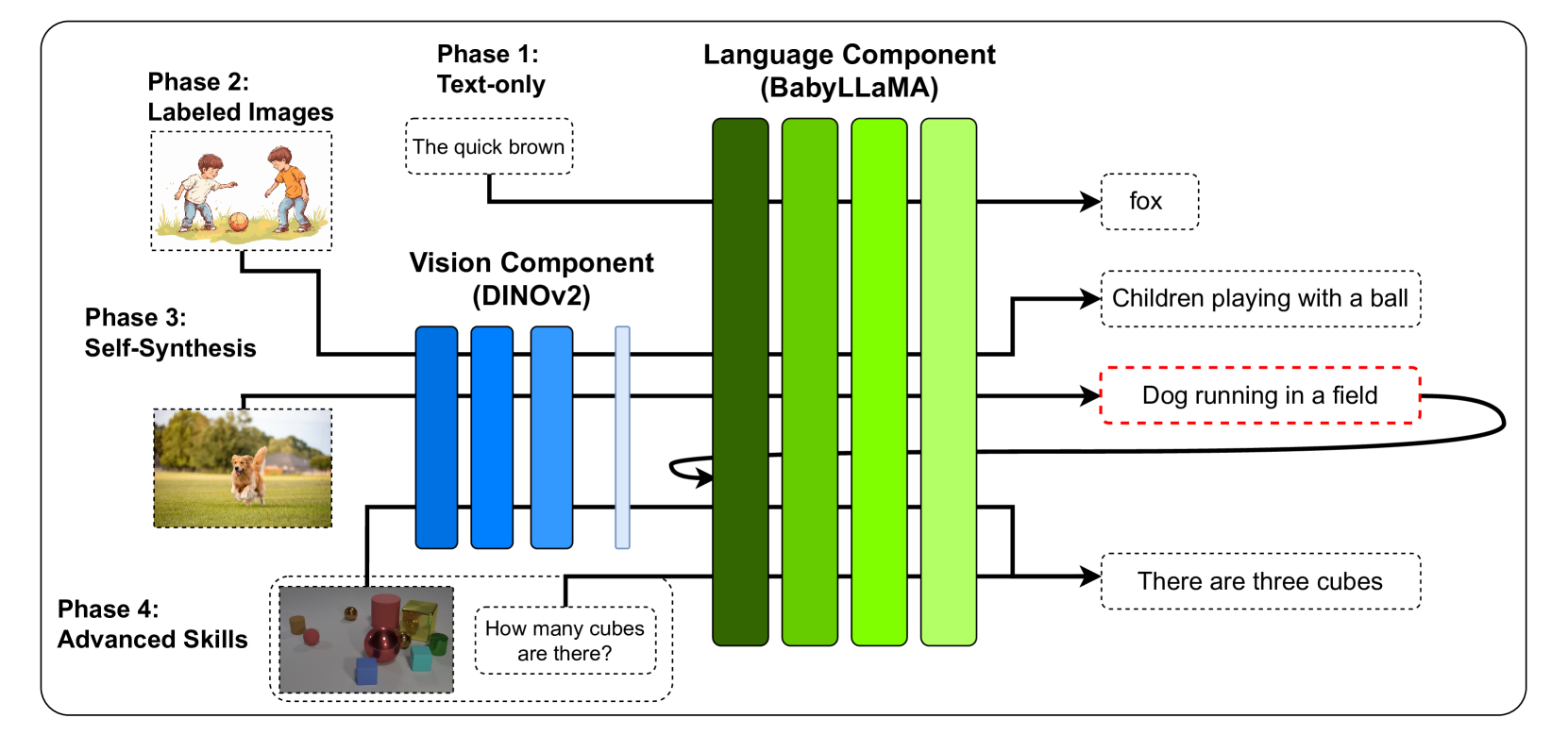
本文提出了一种自合成方法,旨在以有限的数据条件下训练模型,灵感来源于人类认知发展。该方法迭代四个阶段:第一阶段建立基本的语言能力,从头开始在一个小型语料库上训练模型。第二阶段将语言与视觉环境关联,集成视觉编码器以从标记图像生成描述性标题。在第三个“自合成”阶段,模型为未标记图像生成标题,然后使用这些标题以及之前的真实文本来进一步训练其语言组件。此阶段旨在扩展模型的语言能力,类似于人类自我标注新体验。最后,第四阶段通过训练模型执行视觉问答和推理等特定任务来发展高级认知技能。该方法为使用类人认知发展数量的数据训练多模态模型提供了一个概念验证。
🔬 方法详解
问题定义:现有的大型语言模型在生成类人文本方面表现出色,但它们需要大量的训练数据。这限制了它们在数据有限的环境中的应用。因此,需要一种方法,能够在数据量有限的情况下,训练出具有良好性能的视觉-语言模型。
核心思路:本文的核心思路是模仿人类的认知发展过程,通过一个自合成的训练流程,逐步提升模型的语言和视觉理解能力。这种方法旨在利用有限的数据,让模型能够像人类一样,通过自我学习和经验积累来提升自身能力。
技术框架:该方法包含四个阶段: 1. 语言基础阶段:从零开始,在一个小型语料库上训练语言模型,建立基本的语言能力。 2. 视觉关联阶段:将语言模型与视觉编码器集成,利用带标签的图像生成描述性标题,建立视觉与语言之间的联系。 3. 自合成阶段:模型为未标记的图像生成标题,并将这些合成数据与真实数据混合,用于进一步训练语言模型,扩展其语言能力。 4. 认知技能发展阶段:在特定任务(如视觉问答和推理)上训练模型,发展高级认知技能。
关键创新:该方法最重要的创新点在于其自合成的训练流程,模型能够利用自身生成的数据进行学习,从而在数据有限的情况下提升性能。这与传统的监督学习方法不同,后者需要大量的标注数据。
关键设计:在自合成阶段,如何平衡合成数据和真实数据的使用是一个关键设计。论文中可能采用了某种策略(具体细节未知)来控制合成数据的质量和数量,以避免对模型产生负面影响。此外,视觉编码器的选择和训练,以及各个阶段的损失函数设计,也是影响模型性能的关键因素(具体细节未知)。
🖼️ 关键图片

📊 实验亮点
论文提出了一个概念验证,展示了使用少量数据训练多模态模型的可行性。具体的性能数据和对比基线在摘要中没有明确给出,因此无法量化提升幅度。但该研究为在数据受限环境下训练视觉-语言模型提供了一种新的思路。
🎯 应用场景
该研究成果可应用于资源受限场景下的视觉-语言模型训练,例如在缺乏大量标注数据的特定领域,可以利用该方法训练出具有一定理解能力的模型。此外,该方法模拟人类认知发展的方式,为开发更智能、更具适应性的AI系统提供了新的思路。
📄 摘要(原文)
While today's large language models exhibit impressive abilities in generating human-like text, they require massive amounts of data during training. We here take inspiration from human cognitive development to train models in limited data conditions. Specifically we present a self-synthesis approach that iterates through four phases: Phase 1 sets up fundamental language abilities, training the model from scratch on a small corpus. Language is then associated with the visual environment in phase 2, integrating the model with a vision encoder to generate descriptive captions from labeled images. In the "self-synthesis" phase 3, the model generates captions for unlabeled images, that it then uses to further train its language component with a mix of synthetic, and previous real-world text. This phase is meant to expand the model's linguistic repertoire, similar to humans self-annotating new experiences. Finally, phase 4 develops advanced cognitive skills, by training the model on specific tasks such as visual question answering and reasoning. Our approach offers a proof of concept for training a multimodal model using a developmentally plausible amount of data.