Towards Unifying Understanding and Generation in the Era of Vision Foundation Models: A Survey from the Autoregression Perspective
作者: Shenghao Xie, Wenqiang Zu, Mingyang Zhao, Duo Su, Shilong Liu, Ruohua Shi, Guoqi Li, Shanghang Zhang, Lei Ma
分类: cs.CV
发布日期: 2024-10-29 (更新: 2024-10-30)
备注: 17 pages, 1 table, 2 figures
🔗 代码/项目: GITHUB
💡 一句话要点
综述:面向视觉基础模型的自回归统一理解与生成方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉基础模型 自回归模型 视觉Transformer 图像生成 视觉理解 token预测 统一建模
📋 核心要点
- 现有视觉基础模型在统一理解和生成任务方面存在局限性,难以实现类似LLM的通用能力。
- 本文探讨了自回归在视觉基础模型中的应用,旨在通过统一的token预测范式实现视觉任务的统一。
- 该综述对自回归视觉基础模型进行了分类和分析,并指出了未来研究的挑战和方向。
📝 摘要(中文)
大型语言模型(LLM)中的自回归通过将所有语言任务统一到下一个token预测范式中,展现了令人印象深刻的可扩展性。最近,人们越来越有兴趣将这种成功扩展到视觉基础模型。本综述回顾了自回归视觉基础模型的最新进展,并讨论了未来的发展方向。首先,我们介绍了下一代视觉基础模型的趋势,即统一视觉任务中的理解和生成。然后,我们分析了现有视觉基础模型的局限性,并给出了自回归的正式定义及其优势。随后,我们根据视觉tokenizers和自回归backbones对自回归视觉基础模型进行了分类。最后,我们讨论了几个有希望的研究挑战和方向。据我们所知,这是第一个全面总结在统一理解和生成趋势下的自回归视觉基础模型的综述。相关资源集合可在https://github.com/EmmaSRH/ARVFM上找到。
🔬 方法详解
问题定义:现有视觉基础模型通常针对特定任务设计,缺乏通用性和可扩展性。它们在理解和生成任务之间存在gap,难以像LLM一样实现统一建模。此外,现有的视觉模型在处理长序列和上下文信息方面也存在挑战。
核心思路:本文的核心思路是借鉴LLM中自回归的成功经验,将其应用于视觉基础模型。通过将视觉任务转化为下一个token预测问题,实现理解和生成的统一建模。自回归模型能够有效地处理序列数据,并捕捉上下文信息,从而提高视觉任务的性能。
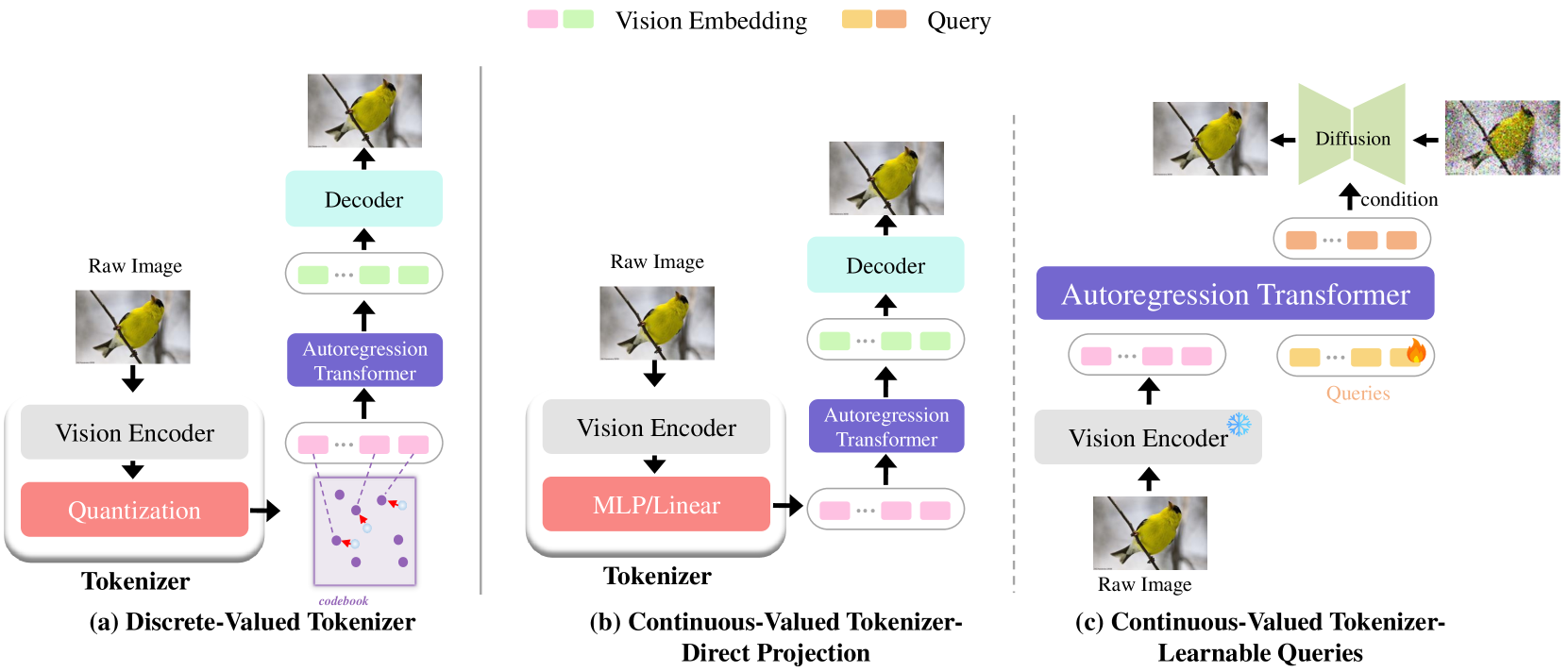
技术框架:自回归视觉基础模型通常包含以下几个主要模块:1) 视觉Tokenizer:将图像转换为离散的视觉token序列。2) 自回归Backbone:利用Transformer等模型对token序列进行建模,预测下一个token。3) 任务Head:根据具体任务,对模型输出进行处理,得到最终结果。整体流程是从图像到token序列,再到token预测,最终完成各种视觉任务。
关键创新:该综述的关键创新在于系统性地总结和分析了自回归在视觉基础模型中的应用。它将视觉任务统一到token预测的框架下,为未来的视觉基础模型研究提供了新的思路。此外,该综述还指出了自回归视觉基础模型面临的挑战和未来的发展方向。
关键设计:视觉Tokenizer的设计至关重要,常见的包括VQ-VAE、dVAE等。自回归Backbone通常采用Transformer结构,并进行针对视觉数据的优化,例如引入稀疏注意力机制。损失函数通常采用交叉熵损失,用于衡量token预测的准确性。关键参数包括token序列长度、Transformer层数、注意力头数等。
🖼️ 关键图片

📊 实验亮点
该综述是首个全面总结自回归视觉基础模型的综述,它系统地分析了现有方法的优缺点,并指出了未来的研究方向。通过对视觉Tokenizer和自回归Backbone的分类,为研究人员提供了清晰的参考框架。该综述还强调了统一理解和生成的重要性,为未来的视觉基础模型研究提供了新的思路。
🎯 应用场景
该研究成果可应用于图像生成、图像编辑、视频预测、视觉问答等领域。通过统一的自回归模型,可以实现更灵活、更强大的视觉智能应用。未来,有望推动通用视觉智能的发展,实现更广泛的实际应用价值。
📄 摘要(原文)
Autoregression in large language models (LLMs) has shown impressive scalability by unifying all language tasks into the next token prediction paradigm. Recently, there is a growing interest in extending this success to vision foundation models. In this survey, we review the recent advances and discuss future directions for autoregressive vision foundation models. First, we present the trend for next generation of vision foundation models, i.e., unifying both understanding and generation in vision tasks. We then analyze the limitations of existing vision foundation models, and present a formal definition of autoregression with its advantages. Later, we categorize autoregressive vision foundation models from their vision tokenizers and autoregression backbones. Finally, we discuss several promising research challenges and directions. To the best of our knowledge, this is the first survey to comprehensively summarize autoregressive vision foundation models under the trend of unifying understanding and generation. A collection of related resources is available at https://github.com/EmmaSRH/ARVFM.