Referring Human Pose and Mask Estimation in the Wild
作者: Bo Miao, Mingtao Feng, Zijie Wu, Mohammed Bennamoun, Yongsheng Gao, Ajmal Mian
分类: cs.CV, cs.HC
发布日期: 2024-10-27
备注: Accepted by NeurIPS 2024. https://github.com/bo-miao/RefHuman
🔗 代码/项目: GITHUB
💡 一句话要点
提出RefHuman数据集和UniPHD模型,用于解决野外环境下基于文本或位置提示的人体姿态和掩码估计问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人体姿态估计 掩码预测 指代理解 多模态学习 深度学习
📋 核心要点
- 现有方法缺乏在野外环境下,根据文本或位置提示精准定位并估计特定人物姿态和掩码的能力。
- UniPHD模型通过多模态表示学习和姿态中心的分层解码器,实现了基于提示的端到端人体姿态和掩码估计。
- 实验结果表明,UniPHD在RefHuman和MS COCO数据集上均取得了优异的性能,验证了其有效性。
📝 摘要(中文)
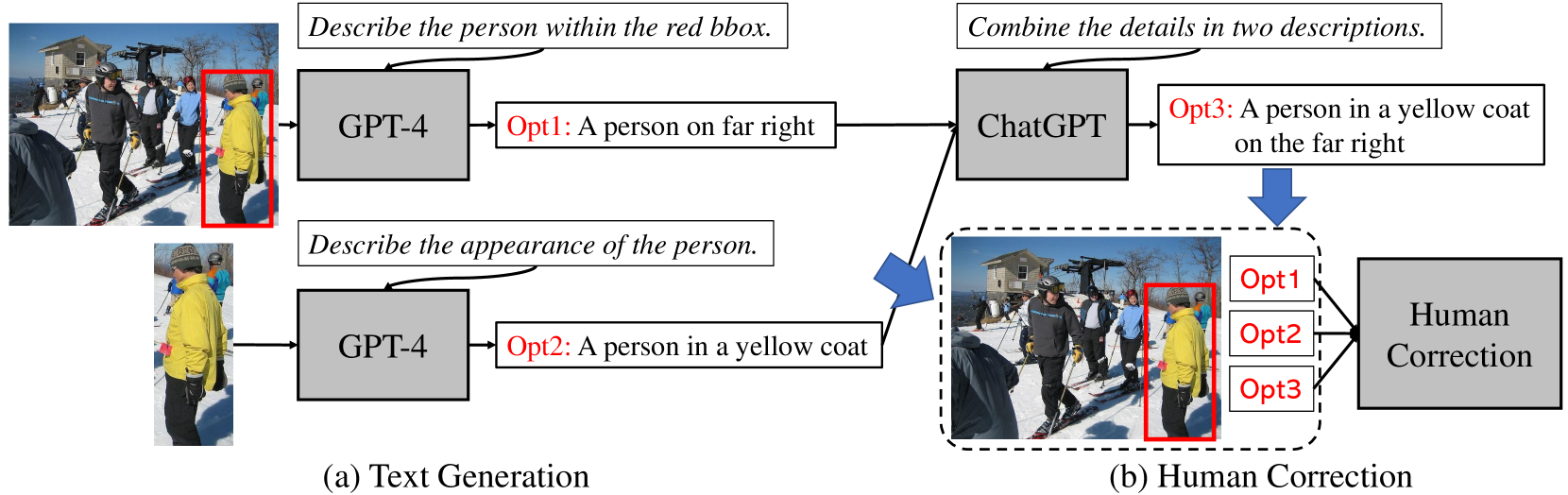
本文提出了野外环境下基于指代的人体姿态和掩码估计(R-HPM)任务,即通过文本或位置提示来指定图像中感兴趣的人。这项新任务在以人为中心的应用程序中具有巨大的潜力,例如辅助机器人和体育分析。与之前的工作相比,R-HPM (i) 确保了与被指代人对应的高质量、身份感知的姿态和掩码估计结果,并且 (ii) 同时预测人体姿态和掩码,以实现全面的表示。为了实现这一目标,我们引入了一个名为RefHuman的大规模数据集,该数据集通过额外的文本和位置提示注释大大扩展了MS COCO数据集。RefHuman包括超过50,000个野外环境中的标注实例,每个实例都配备了关键点、掩码和提示注释。为了实现提示条件下的估计,我们提出了第一个名为UniPHD的端到端可提示方法用于R-HPM。UniPHD提取多模态表示,并采用提出的以姿态为中心的层次解码器来处理(文本或位置)实例查询和关键点查询,从而生成特定于被指代人的结果。大量的实验表明,UniPHD可以基于用户友好的提示产生高质量的结果,并在RefHuman val和MS COCO val2017上实现了顶级的性能。数据和代码可在https://github.com/bo-miao/RefHuman 获取。
🔬 方法详解
问题定义:论文旨在解决野外环境下,如何根据文本或位置提示准确地估计图像中特定人物的姿态和掩码的问题。现有方法通常无法处理复杂的野外场景,并且缺乏对人物身份的感知,导致姿态和掩码估计结果不准确。
核心思路:论文的核心思路是利用多模态信息(图像、文本/位置提示)来引导姿态和掩码估计。通过学习图像和提示之间的关联,模型可以准确地识别出被指代的人物,并预测其姿态和掩码。这种方法能够有效地解决野外场景中的复杂性和歧义性问题。
技术框架:UniPHD模型采用端到端的架构,主要包括以下几个模块:1) 多模态特征提取器:用于提取图像和提示的特征表示。2) 实例查询和关键点查询:用于根据提示信息生成实例查询和关键点查询。3) 以姿态为中心的层次解码器:用于处理实例查询和关键点查询,并预测被指代人物的姿态和掩码。
关键创新:论文的关键创新在于提出了以姿态为中心的层次解码器。该解码器能够有效地融合实例查询和关键点查询的信息,从而实现对被指代人物姿态和掩码的准确估计。与现有方法相比,该解码器能够更好地利用姿态信息来指导掩码预测,从而提高整体性能。
关键设计:UniPHD模型采用Transformer架构作为多模态特征提取器和层次解码器的基础。损失函数包括关键点损失、掩码损失和实例损失,用于优化模型的参数。在训练过程中,采用了数据增强技术来提高模型的鲁棒性。具体的网络结构和参数设置在论文中有详细描述。
🖼️ 关键图片


📊 实验亮点
UniPHD模型在RefHuman val数据集上取得了显著的性能提升,相较于基线方法,在姿态估计和掩码预测方面均有明显改善。此外,UniPHD在MS COCO val2017数据集上也表现出竞争力,验证了其泛化能力。实验结果表明,UniPHD能够有效地利用文本和位置提示信息,实现对特定人物姿态和掩码的准确估计。
🎯 应用场景
该研究成果可广泛应用于辅助机器人、体育分析、智能监控、人机交互等领域。例如,在辅助机器人中,可以通过语音或手势提示机器人识别并跟踪特定人物,从而提供个性化的服务。在体育分析中,可以根据运动员的名称或位置信息,自动分析其运动姿态和技术动作。该研究有助于提升人机交互的智能化水平,并为相关应用提供更精准、可靠的技术支持。
📄 摘要(原文)
We introduce Referring Human Pose and Mask Estimation (R-HPM) in the wild, where either a text or positional prompt specifies the person of interest in an image. This new task holds significant potential for human-centric applications such as assistive robotics and sports analysis. In contrast to previous works, R-HPM (i) ensures high-quality, identity-aware results corresponding to the referred person, and (ii) simultaneously predicts human pose and mask for a comprehensive representation. To achieve this, we introduce a large-scale dataset named RefHuman, which substantially extends the MS COCO dataset with additional text and positional prompt annotations. RefHuman includes over 50,000 annotated instances in the wild, each equipped with keypoint, mask, and prompt annotations. To enable prompt-conditioned estimation, we propose the first end-to-end promptable approach named UniPHD for R-HPM. UniPHD extracts multimodal representations and employs a proposed pose-centric hierarchical decoder to process (text or positional) instance queries and keypoint queries, producing results specific to the referred person. Extensive experiments demonstrate that UniPHD produces quality results based on user-friendly prompts and achieves top-tier performance on RefHuman val and MS COCO val2017. Data and Code: https://github.com/bo-miao/RefHuman