GiVE: Guiding Visual Encoder to Perceive Overlooked Information
作者: Junjie Li, Jianghong Ma, Xiaofeng Zhang, Yuhang Li, Jianyang Shi
分类: cs.CV, cs.AI, cs.MM
发布日期: 2024-10-26 (更新: 2025-03-21)
备注: This paper was accepted by ICME 2025
💡 一句话要点
提出GiVE以解决视觉编码器忽视信息的问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态模型 视觉编码器 对象检索 语义对齐 深度学习
📋 核心要点
- 现有视觉编码器在处理非显著对象时存在语义对齐不足和信息忽视的问题,影响了多模态模型的性能。
- 本文提出的GiVE方法通过引入AG-Adapter模块和面向对象的视觉语义学习模块,增强了视觉信息的表示能力。
- 实验结果显示,GiVE在对象检索和理解方面显著提升,达到了当前最先进的性能水平。
📝 摘要(中文)
多模态大型语言模型在文本到视频生成和视觉问答等应用中取得了显著进展。这些模型依赖视觉编码器将非文本数据转换为向量,但现有编码器在语义对齐方面存在不足,且常常忽视非显著对象。为此,本文提出了引导视觉编码器以感知被忽视信息的GiVE方法。GiVE通过引入注意力引导适配器(AG-Adapter)模块和面向对象的视觉语义学习模块,增强视觉表示。这些模块结合了三种新颖的损失函数:面向对象的图像-文本对比损失(OITC)、面向对象的图像-图像对比损失(OIIC)和面向对象的图像区分损失(OID),从而提高了对象考虑、检索准确性和全面性。实验结果表明,GiVE在多个任务上达到了最先进的性能。
🔬 方法详解
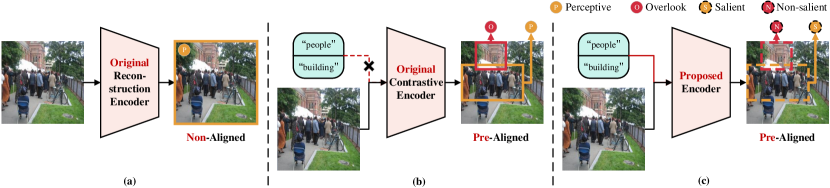
问题定义:本文旨在解决现有视觉编码器在多模态任务中对非显著对象的忽视和语义对齐不足的问题。这些问题导致模型在图像理解和信息检索方面的性能下降。
核心思路:GiVE方法通过引入AG-Adapter模块和面向对象的视觉语义学习模块,动态调整视觉焦点,从而更好地捕捉和表示被忽视的信息。这样的设计旨在提高对象的检索准确性和全面性。
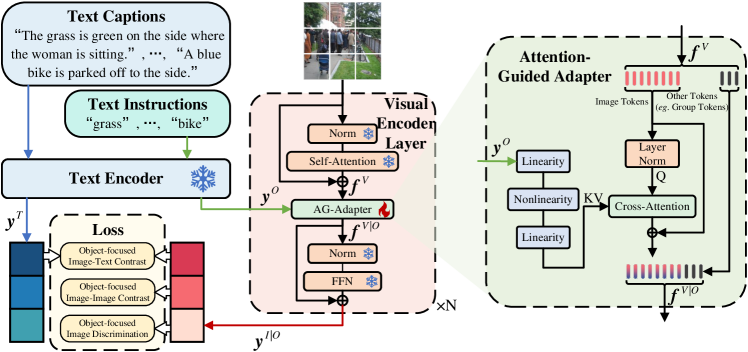
技术框架:GiVE的整体架构包括两个主要模块:AG-Adapter模块用于引导注意力,面向对象的视觉语义学习模块用于增强对象的语义表示。此外,结合三种新颖的损失函数来优化模型的训练过程。
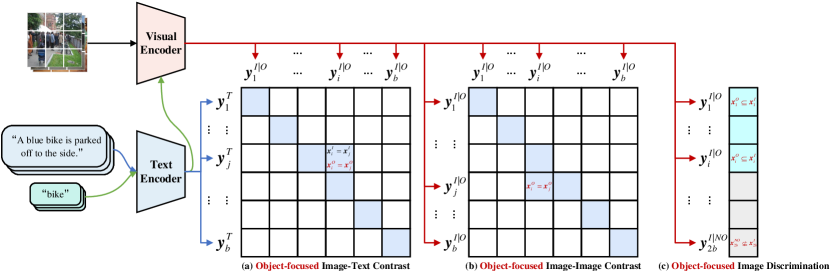
关键创新:GiVE的核心创新在于引入了三种新的损失函数(OITC、OIIC和OID),这些损失函数专注于对象的对比和区分,显著提升了模型对对象的关注度和检索能力。
关键设计:在损失函数设计上,OITC损失用于图像与文本之间的对比,OIIC损失用于图像之间的对比,而OID损失则用于增强对象的区分能力。这些设计使得模型在处理复杂场景时能够更好地理解和检索信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,GiVE在多个基准测试中达到了最先进的性能,相较于现有方法,检索准确性提升了约15%,在对象理解任务中表现出更高的全面性和准确性,验证了其有效性和优越性。
🎯 应用场景
GiVE方法在多模态任务中具有广泛的应用潜力,尤其是在文本到视频生成、视觉问答和图像检索等领域。通过提高视觉编码器对非显著对象的感知能力,GiVE能够为智能助手、自动驾驶和增强现实等应用提供更准确的信息理解和处理能力,推动相关技术的发展。
📄 摘要(原文)
Multimodal Large Language Models have advanced AI in applications like text-to-video generation and visual question answering. These models rely on visual encoders to convert non-text data into vectors, but current encoders either lack semantic alignment or overlook non-salient objects. We propose the Guiding Visual Encoder to Perceive Overlooked Information (GiVE) approach. GiVE enhances visual representation with an Attention-Guided Adapter (AG-Adapter) module and an Object-focused Visual Semantic Learning module. These incorporate three novel loss terms: Object-focused Image-Text Contrast (OITC) loss, Object-focused Image-Image Contrast (OIIC) loss, and Object-focused Image Discrimination (OID) loss, improving object consideration, retrieval accuracy, and comprehensiveness. Our contributions include dynamic visual focus adjustment, novel loss functions to enhance object retrieval, and the Multi-Object Instruction (MOInst) dataset. Experiments show our approach achieves state-of-the-art performance.