TimeSuite: Improving MLLMs for Long Video Understanding via Grounded Tuning
作者: Xiangyu Zeng, Kunchang Li, Chenting Wang, Xinhao Li, Tianxiang Jiang, Ziang Yan, Songze Li, Yansong Shi, Zhengrong Yue, Yi Wang, Yali Wang, Yu Qiao, Limin Wang
分类: cs.CV, cs.AI, cs.MM
发布日期: 2024-10-25 (更新: 2025-02-12)
备注: Accepted by ICLR2025
💡 一句话要点
TimeSuite:通过Grounded Tuning提升MLLM在长视频理解中的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长视频理解 多模态学习 Grounded Tuning 时间建模 指令微调
📋 核心要点
- 现有MLLM在长视频理解方面面临挑战,无法有效处理长序列和捕捉时间信息。
- TimeSuite通过token shuffling压缩视频tokens,引入时间自适应位置编码增强时间感知,并构建高质量Grounded数据集。
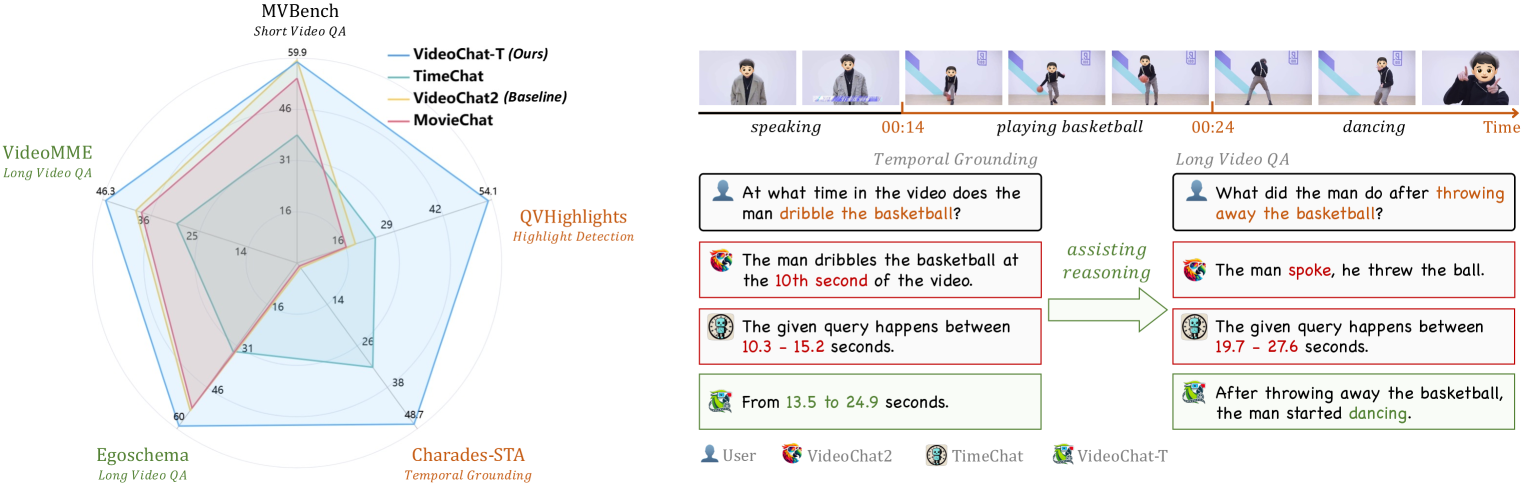
- 实验表明,TimeSuite显著提升了MLLM在长视频理解任务上的性能,并在零样本时间Grounded方面表现出色。
📝 摘要(中文)
多模态大型语言模型(MLLMs)在短视频理解方面表现出了令人印象深刻的性能。然而,理解长视频对于MLLMs来说仍然具有挑战性。本文提出了TimeSuite,这是一系列新的设计,旨在使现有的短视频MLLMs适应长视频理解,包括一个简单而高效的框架来处理长视频序列,一个高质量的视频数据集用于MLLMs的Grounded Tuning,以及一个精心设计的指令微调任务,以在传统的QA格式中显式地结合Grounded监督。具体来说,基于VideoChat,我们提出了我们的长视频MLLM,命名为VideoChat-T,通过实现token shuffling来压缩长视频tokens,并引入时间自适应位置编码(TAPE)来增强视觉表示的时间感知能力。同时,我们引入了TimePro,这是一个综合的以Grounded为中心的指令微调数据集,由9个任务和349k高质量的Grounded标注组成。值得注意的是,我们设计了一种新的指令微调任务类型,称为时间Grounded字幕,以执行详细的视频描述以及相应的时间戳预测。这种显式的时间位置预测将引导MLLM在生成描述时正确地关注视觉内容,从而降低由LLMs引起的幻觉风险。实验结果表明,我们的TimeSuite为增强短视频MLLM的长视频理解能力提供了一个成功的解决方案,在Egoschema和VideoMME的基准测试中分别实现了5.6%和6.8%的改进。此外,VideoChat-T表现出强大的零样本时间Grounded能力,显著优于现有的最先进的MLLMs。经过微调后,它的性能与传统的监督专家模型相当。
🔬 方法详解
问题定义:现有的多模态大型语言模型(MLLMs)在处理长视频时面临挑战。主要痛点在于:1) 长视频序列包含大量tokens,直接输入MLLM会导致计算成本过高;2) 现有模型缺乏对视频中时间信息的有效建模,难以准确理解视频内容的时间演变过程;3) 缺乏高质量的、带有时间Grounded标注的数据集用于训练。
核心思路:TimeSuite的核心思路是:1) 通过token shuffling压缩长视频序列,降低计算复杂度;2) 引入时间自适应位置编码(TAPE)增强模型对时间信息的感知能力;3) 构建高质量的、以Grounded为中心的指令微调数据集TimePro,显式地引导模型学习视频内容与时间戳之间的对应关系。这样设计的目的是为了让MLLM能够更有效地处理长视频,并准确理解视频内容的时间信息。
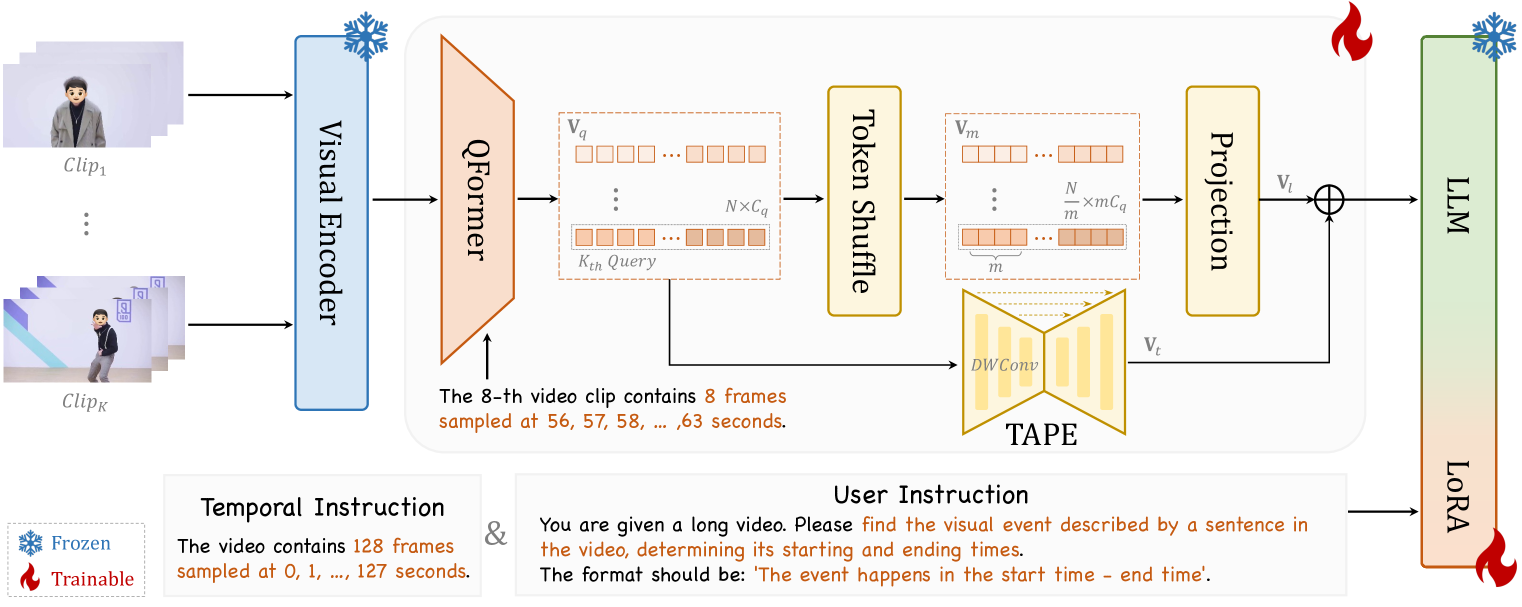
技术框架:TimeSuite基于VideoChat框架,提出了VideoChat-T模型。整体流程如下:1) 输入长视频序列;2) 使用token shuffling对视频tokens进行压缩;3) 使用时间自适应位置编码(TAPE)对视觉表示进行增强;4) 将增强后的视觉表示输入MLLM进行处理;5) 输出视频理解结果,例如问答、字幕生成等。此外,TimeSuite还引入了TimePro数据集,用于指令微调,提升模型的Grounded能力。
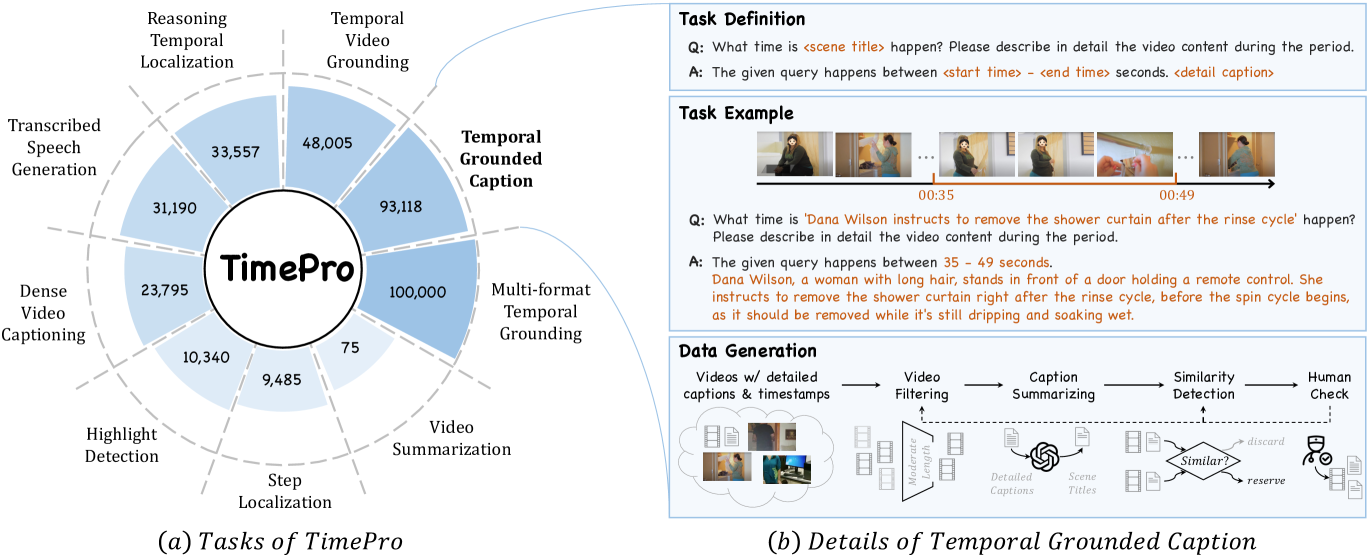
关键创新:TimeSuite的主要创新点在于:1) 提出了token shuffling方法,有效压缩长视频序列,降低计算成本;2) 引入了时间自适应位置编码(TAPE),增强了模型对时间信息的感知能力;3) 构建了高质量的、以Grounded为中心的指令微调数据集TimePro,显式地引导模型学习视频内容与时间戳之间的对应关系;4) 设计了一种新的指令微调任务类型,称为时间Grounded字幕,要求模型生成带有时间戳的视频描述。
关键设计:在token shuffling方面,具体实现方式未知。在时间自适应位置编码(TAPE)方面,具体实现细节未知,但其目的是为了让模型能够更好地感知视频内容的时间信息。TimePro数据集包含9个任务和349k高质量的Grounded标注。时间Grounded字幕任务要求模型预测与视频描述相对应的时间戳,损失函数的设计未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,TimeSuite在Egoschema和VideoMME基准测试中分别实现了5.6%和6.8%的改进。VideoChat-T表现出强大的零样本时间Grounded能力,显著优于现有的最先进的MLLMs。经过微调后,它的性能与传统的监督专家模型相当。这些结果表明,TimeSuite为增强短视频MLLM的长视频理解能力提供了一个有效的解决方案。
🎯 应用场景
该研究成果可应用于视频监控、自动驾驶、智能家居、在线教育等领域。例如,在视频监控中,可以利用该技术对监控视频进行分析,自动识别异常事件并生成报警信息。在自动驾驶中,可以利用该技术对车载摄像头拍摄的视频进行分析,帮助车辆更好地理解周围环境。在在线教育中,可以利用该技术对教学视频进行分析,自动生成字幕和摘要,方便学生学习。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) have demonstrated impressive performance in short video understanding. However, understanding long-form videos still remains challenging for MLLMs. This paper proposes TimeSuite, a collection of new designs to adapt the existing short-form video MLLMs for long video understanding, including a simple yet efficient framework to process long video sequence, a high-quality video dataset for grounded tuning of MLLMs, and a carefully-designed instruction tuning task to explicitly incorporate the grounding supervision in the traditional QA format. Specifically, based on VideoChat, we propose our long-video MLLM, coined as VideoChat-T, by implementing a token shuffling to compress long video tokens and introducing Temporal Adaptive Position Encoding (TAPE) to enhance the temporal awareness of visual representation. Meanwhile, we introduce the TimePro, a comprehensive grounding-centric instruction tuning dataset composed of 9 tasks and 349k high-quality grounded annotations. Notably, we design a new instruction tuning task type, called Temporal Grounded Caption, to peform detailed video descriptions with the corresponding time stamps prediction. This explicit temporal location prediction will guide MLLM to correctly attend on the visual content when generating description, and thus reduce the hallucination risk caused by the LLMs. Experimental results demonstrate that our TimeSuite provides a successful solution to enhance the long video understanding capability of short-form MLLM, achieving improvement of 5.6% and 6.8% on the benchmarks of Egoschema and VideoMME, respectively. In addition, VideoChat-T exhibits robust zero-shot temporal grounding capabilities, significantly outperforming the existing state-of-the-art MLLMs. After fine-tuning, it performs on par with the traditional supervised expert models.