Pay Attention and Move Better: Harnessing Attention for Interactive Motion Generation and Training-free Editing
作者: Ling-Hao Chen, Shunlin Lu, Wenxun Dai, Zhiyang Dou, Xuan Ju, Jingbo Wang, Taku Komura, Lei Zhang
分类: cs.CV
发布日期: 2024-10-24 (更新: 2025-01-22)
备注: Updated MotionCLR technical report
💡 一句话要点
提出MotionCLR:一种基于注意力机制的运动扩散模型,用于交互式运动生成与无训练编辑。
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: 运动生成 扩散模型 注意力机制 交互式编辑 文本-运动对齐
📋 核心要点
- 现有运动扩散模型缺乏对文本-运动对应关系的显式建模,限制了细粒度编辑能力和可解释性。
- MotionCLR通过自注意力和交叉注意力分别建模模态内和跨模态交互,实现细粒度的文本-运动对齐。
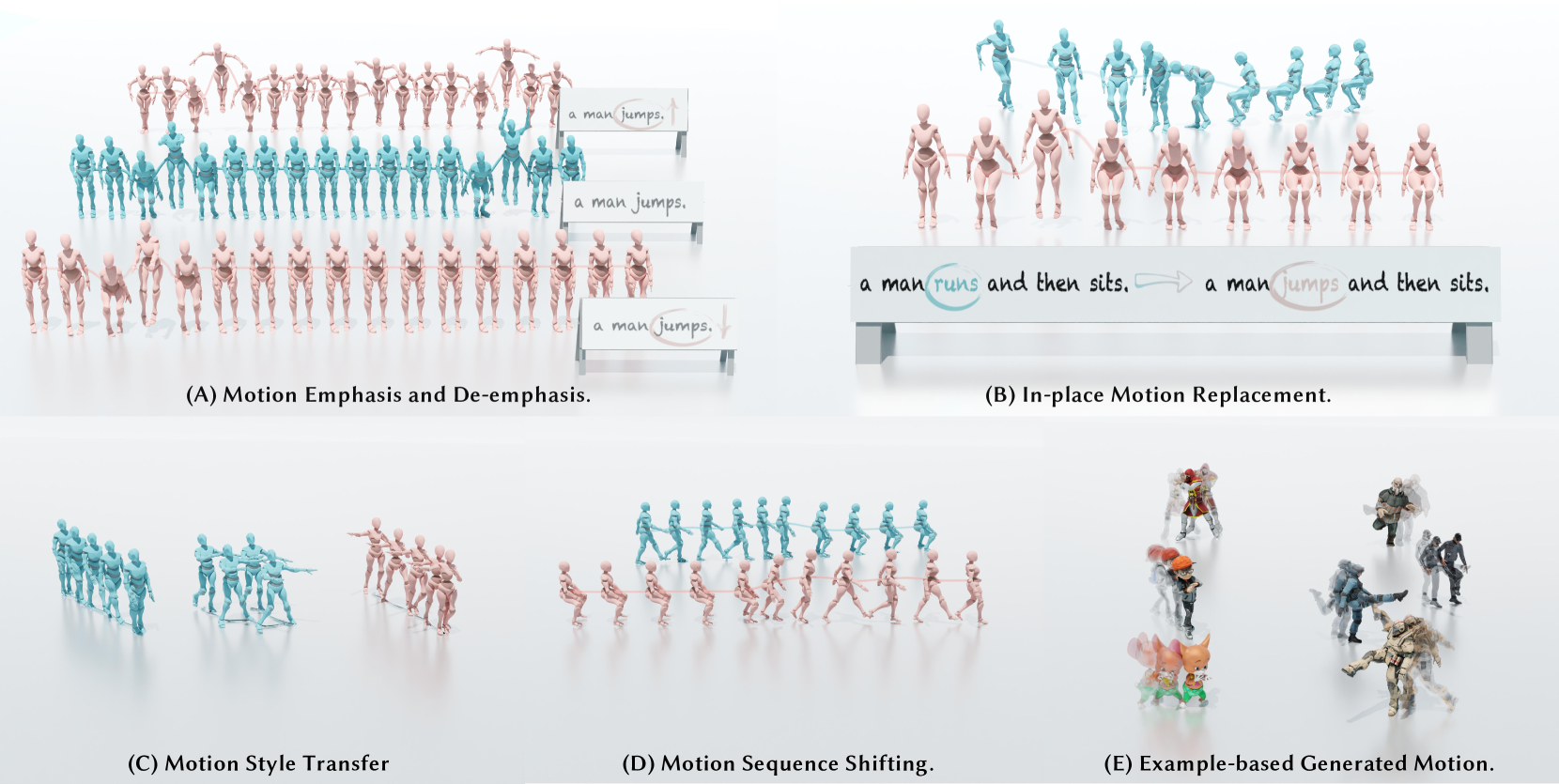
- 通过操纵注意力图,MotionCLR实现了运动编辑,并在动作计数和上下文运动生成方面展现了潜力。
📝 摘要(中文)
本研究深入探讨了人体运动生成的交互式编辑问题。以往的运动扩散模型缺乏对词级别文本-运动对应关系的显式建模和良好的可解释性,从而限制了其细粒度编辑能力。为了解决这个问题,我们提出了一种基于注意力机制的运动扩散模型,即MotionCLR,它以清晰的方式建模注意力机制。在技术上,MotionCLR分别使用自注意力和交叉注意力来建模模态内和跨模态的交互。更具体地说,自注意力机制旨在衡量帧之间的序列相似性,并影响运动特征的顺序。相比之下,交叉注意力机制用于找到细粒度的词序列对应关系,并激活运动序列中相应的时间步。基于这些关键特性,我们开发了一套通用且简单有效的运动编辑方法,通过操纵注意力图来实现,例如运动(去)强调、原地运动替换和基于示例的运动生成等。为了进一步验证注意力机制的可解释性,我们还通过注意力图探索了动作计数和基于上下文的运动生成能力。我们的实验结果表明,我们的方法具有良好的生成和编辑能力,并具有良好的可解释性。
🔬 方法详解
问题定义:现有运动扩散模型在交互式运动编辑方面存在不足,主要体现在两个方面:一是缺乏对词级别文本-运动对应关系的显式建模,导致无法进行细粒度的编辑;二是可解释性较差,难以理解模型生成运动的原因,从而限制了编辑的灵活性和可控性。这些问题使得用户难以精确地控制运动的生成过程,例如,无法针对特定词语调整运动的幅度或替换特定动作。
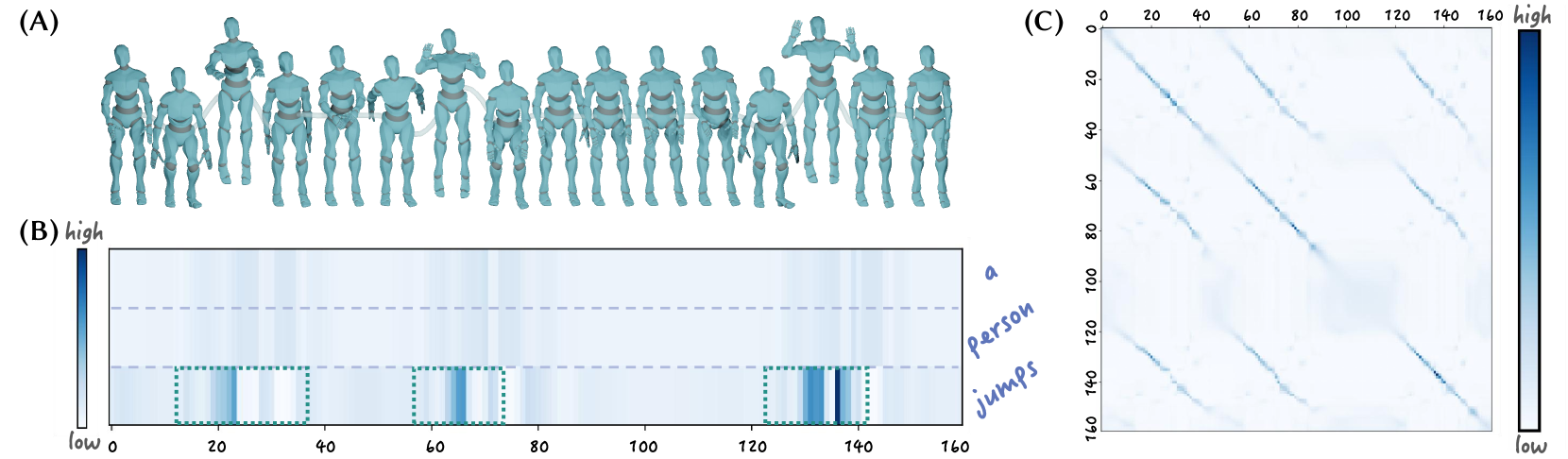
核心思路:MotionCLR的核心思路是利用注意力机制显式地建模文本和运动之间的对应关系。通过自注意力机制捕捉运动序列内部的依赖关系,通过交叉注意力机制建立文本和运动之间的关联。这种设计使得模型能够理解文本描述中每个词语对运动序列的影响,从而实现细粒度的运动编辑和可解释的运动生成。
技术框架:MotionCLR的整体框架是一个基于扩散模型的运动生成模型,其核心在于注意力机制的运用。模型包含以下主要模块:1) 运动编码器:将运动序列编码为潜在空间表示。2) 文本编码器:将文本描述编码为潜在空间表示。3) 扩散过程:逐步向运动序列添加噪声。4) 逆扩散过程:通过迭代去噪生成运动序列。在逆扩散过程中,自注意力机制用于建模运动序列内部的依赖关系,交叉注意力机制用于融合文本信息,指导运动生成。
关键创新:MotionCLR的关键创新在于CLeaR建模的注意力机制。具体来说,它显式地建模了自注意力和交叉注意力,使得模型能够学习到运动序列内部的依赖关系以及文本和运动之间的对应关系。这种显式建模使得模型具有更好的可解释性和更强的编辑能力。与现有方法相比,MotionCLR不需要额外的训练即可进行运动编辑,更加灵活和高效。
关键设计:MotionCLR的关键设计包括:1) 自注意力机制:用于捕捉运动序列内部的依赖关系,例如,相邻帧之间的平滑过渡。2) 交叉注意力机制:用于建立文本和运动之间的对应关系,例如,文本中的“跳跃”对应于运动序列中的跳跃动作。3) 注意力图可视化:用于解释模型生成运动的原因,例如,可以观察到哪些词语对哪些时间步的运动产生了影响。具体的参数设置和网络结构细节在论文中有详细描述,但摘要中未提及。
🖼️ 关键图片

📊 实验亮点
MotionCLR在运动生成和编辑方面表现出色,通过操纵注意力图,实现了运动强调、原地替换和基于示例的生成等多种编辑功能。此外,该模型还展现了良好的可解释性,能够通过注意力图进行动作计数和上下文运动生成。具体的性能数据和对比基线在论文中给出,摘要中未提及。
🎯 应用场景
MotionCLR具有广泛的应用前景,例如:1) 虚拟现实和增强现实:可以用于生成逼真的人体运动,增强用户的沉浸感。2) 游戏开发:可以用于生成各种角色的运动动画,提高游戏的真实性和趣味性。3) 机器人控制:可以用于控制机器人执行复杂的运动任务。未来,该研究可以进一步扩展到其他类型的运动生成,例如,动物运动和车辆运动。
📄 摘要(原文)
This research delves into the problem of interactive editing of human motion generation. Previous motion diffusion models lack explicit modeling of the word-level text-motion correspondence and good explainability, hence restricting their fine-grained editing ability. To address this issue, we propose an attention-based motion diffusion model, namely MotionCLR, with CLeaR modeling of attention mechanisms. Technically, MotionCLR models the in-modality and cross-modality interactions with self-attention and cross-attention, respectively. More specifically, the self-attention mechanism aims to measure the sequential similarity between frames and impacts the order of motion features. By contrast, the cross-attention mechanism works to find the fine-grained word-sequence correspondence and activate the corresponding timesteps in the motion sequence. Based on these key properties, we develop a versatile set of simple yet effective motion editing methods via manipulating attention maps, such as motion (de-)emphasizing, in-place motion replacement, and example-based motion generation, etc. For further verification of the explainability of the attention mechanism, we additionally explore the potential of action-counting and grounded motion generation ability via attention maps. Our experimental results show that our method enjoys good generation and editing ability with good explainability.