PESFormer: Boosting Macro- and Micro-expression Spotting with Direct Timestamp Encoding
作者: Wang-Wang Yu, Kai-Fu Yang, Xiangrui Hu, Jingwen Jiang, Hong-Mei Yan, Yong-Jie Li
分类: cs.CV
发布日期: 2024-10-24
💡 一句话要点
PESFormer:基于直接时间戳编码提升宏表情和微表情定位性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 微表情识别 宏表情识别 时间戳编码 视觉Transformer 长视频分析
📋 核心要点
- 现有基于anchor的表情定位方法难以覆盖所有训练区间,且滑动窗口切片易造成信息丢失。
- PESFormer采用直接时间戳编码(DTE)替代anchor,保留所有训练区间,实现点到区间的表情定位。
- 通过零填充将未裁剪视频处理成统一长度,避免信息丢失,实验表明PESFormer性能优于现有方法。
📝 摘要(中文)
宏表情和微表情定位旨在精确地定位和分类未裁剪视频中的时间表达实例。鉴于表情的稀疏分布和持续时间变化,现有的基于anchor的方法通常通过编码与预定义anchor的偏差来表示实例。此外,这些方法通常将未裁剪的视频切片成固定长度的滑动窗口。然而,基于anchor的编码通常无法捕获所有训练区间,并且将原始视频切片为滑动窗口可能导致有价值的训练区间被丢弃。为了克服这些限制,我们引入了PESFormer,一个基于视觉Transformer架构的简单而有效的模型,以实现点到区间的表情定位。PESFormer采用直接时间戳编码(DTE)方法来替换anchor,从而实现每个时间戳的二元分类,而不是优化整个ground truth。因此,所有训练区间都以离散时间戳的形式保留。为了最大限度地利用训练区间,我们通过替换滑动窗口方法产生的短视频来增强预处理过程。相反,我们实施了一种策略,涉及对未裁剪的训练视频进行零填充,以创建统一的、更长的预定持续时间的视频。此操作有效地保留了原始训练区间,并消除了视频切片增强。在三个数据集CAS(ME)^2、CAS(ME)^3和SAMM-LV上的大量定性和定量评估表明,我们的PESFormer优于现有技术,实现了最佳性能。
🔬 方法详解
问题定义:宏表情和微表情定位旨在从长视频中准确识别和定位表情的起始和结束时间点。现有方法依赖于预定义的anchor,通过预测表情与anchor的偏差来进行定位,但这种方式无法覆盖所有可能的表情持续时间和位置,导致信息丢失。此外,常用的滑动窗口切片方法也会丢弃部分有价值的训练区间。
核心思路:PESFormer的核心思路是抛弃anchor机制,直接对视频中的每个时间戳进行二元分类,判断该时间戳是否属于一个表情的起始或结束点。通过这种“点到区间”的方式,模型可以更灵活地捕捉不同长度和位置的表情。同时,为了避免滑动窗口带来的信息损失,论文采用零填充的方式将所有视频处理成统一长度。
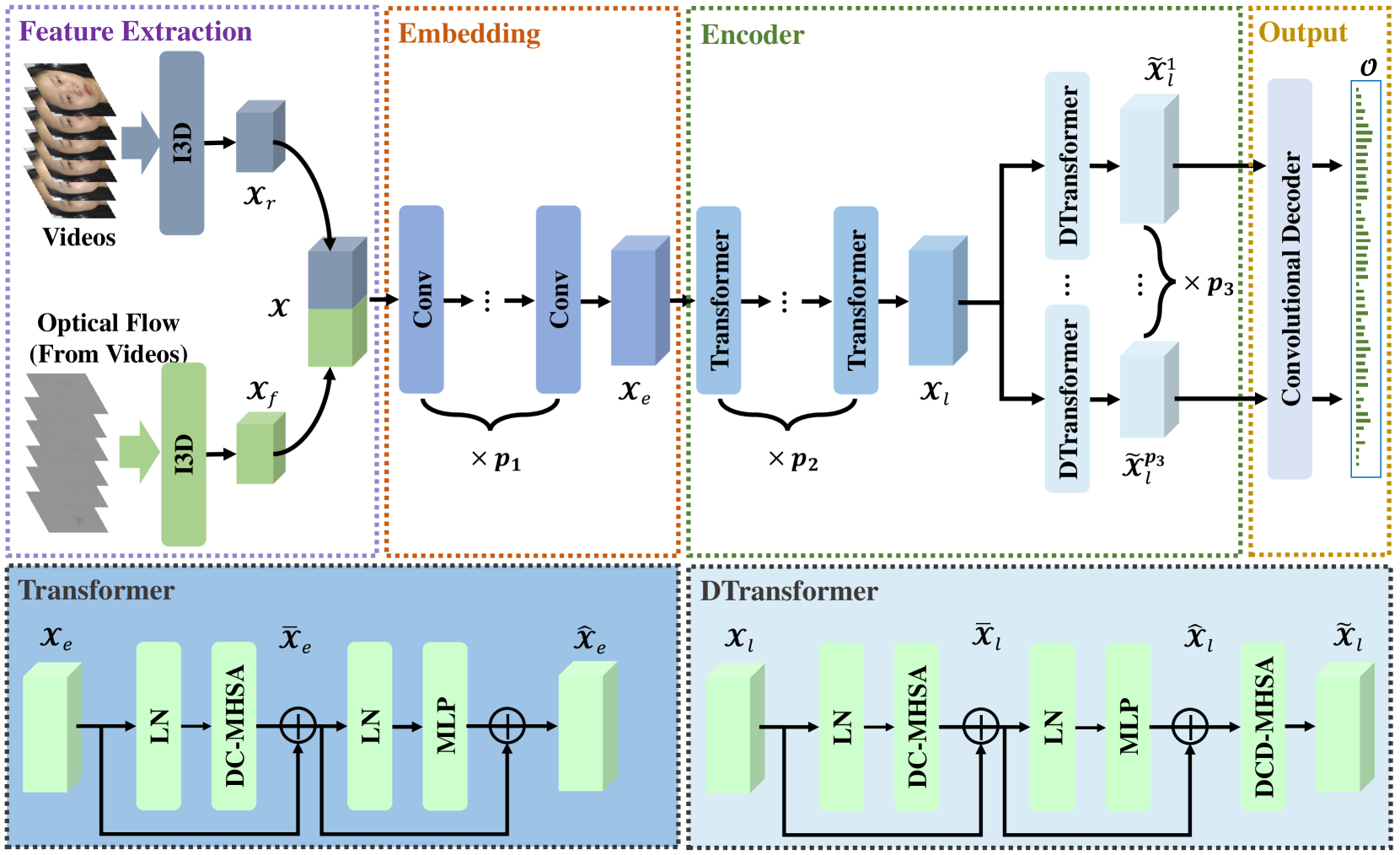
技术框架:PESFormer基于视觉Transformer架构。整体流程如下:1) 输入:未裁剪的长视频;2) 预处理:对视频进行零填充,使其长度统一;3) 特征提取:使用视觉Transformer提取视频帧的特征;4) 时间戳编码:对每个时间戳进行直接编码,得到时间戳特征;5) 分类:使用分类器预测每个时间戳是否属于表情的起始或结束点;6) 后处理:将预测结果转换为表情的起始和结束时间区间。
关键创新:PESFormer的关键创新在于直接时间戳编码(DTE)。与传统的anchor-based方法相比,DTE避免了预定义anchor带来的局限性,能够更灵活地捕捉不同长度和位置的表情。此外,通过零填充处理长视频,避免了滑动窗口切片造成的信息损失。
关键设计:PESFormer使用视觉Transformer作为特征提取器,具体结构未知。损失函数采用二元交叉熵损失函数,用于训练时间戳分类器。零填充的长度需要根据数据集中的表情长度分布进行调整,以保证所有表情都能够完整地包含在处理后的视频中。具体参数设置未知。
🖼️ 关键图片


📊 实验亮点
PESFormer在CAS(ME)^2、CAS(ME)^3和SAMM-LV三个数据集上都取得了最佳性能,超越了现有的表情定位方法。具体提升幅度未知,但论文强调了PESFormer在处理长视频和捕捉不同长度表情方面的优势。
🎯 应用场景
PESFormer可应用于心理学研究、人机交互、安全监控等领域。例如,在心理学研究中,可以帮助研究人员更准确地分析人类的情绪反应。在人机交互中,可以使机器更好地理解人类的情绪,从而提供更自然和个性化的服务。在安全监控中,可以用于检测潜在的威胁行为,例如欺骗或攻击。
📄 摘要(原文)
The task of macro- and micro-expression spotting aims to precisely localize and categorize temporal expression instances within untrimmed videos. Given the sparse distribution and varying durations of expressions, existing anchor-based methods often represent instances by encoding their deviations from predefined anchors. Additionally, these methods typically slice the untrimmed videos into fixed-length sliding windows. However, anchor-based encoding often fails to capture all training intervals, and slicing the original video as sliding windows can result in valuable training intervals being discarded. To overcome these limitations, we introduce PESFormer, a simple yet effective model based on the vision transformer architecture to achieve point-to-interval expression spotting. PESFormer employs a direct timestamp encoding (DTE) approach to replace anchors, enabling binary classification of each timestamp instead of optimizing entire ground truths. Thus, all training intervals are retained in the form of discrete timestamps. To maximize the utilization of training intervals, we enhance the preprocessing process by replacing the short videos produced through the sliding window method.Instead, we implement a strategy that involves zero-padding the untrimmed training videos to create uniform, longer videos of a predetermined duration. This operation efficiently preserves the original training intervals and eliminates video slice enhancement.Extensive qualitative and quantitative evaluations on three datasets -- CAS(ME)^2, CAS(ME)^3 and SAMM-LV -- demonstrate that our PESFormer outperforms existing techniques, achieving the best performance.