Efficient Neural Implicit Representation for 3D Human Reconstruction
作者: Zexu Huang, Sarah Monazam Erfani, Siying Lu, Mingming Gong
分类: cs.CV
发布日期: 2024-10-23
期刊: Pattern Recognition, Vol. 156, 2024, Article No. 110758
DOI: 10.1016/j.patcog.2024.110758
💡 一句话要点
提出HumanAvatar,融合HuMoR、Instant-NGP和Fast-SNARF,高效重建3D人体化身。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱六:视频提取与匹配 (Video Extraction)
关键词: 3D人体重建 神经辐射场 单目视频 人体运动估计 姿态估计 快速渲染 虚拟化身
📋 核心要点
- 传统3D人体运动重建方法依赖昂贵硬件,计算成本高昂,难以满足快速增长的数字世界需求。
- HumanAvatar融合HuMoR、Instant-NGP和Fast-SNARF,利用姿态敏感空间缩减技术,提升重建速度和精度。
- 实验表明,HumanAvatar在重建质量上与现有技术相当或超越,训练速度提升110倍,仅需30秒即可提供有效视觉效果。
📝 摘要(中文)
本文提出了一种名为HumanAvatar的创新方法,旨在从单目视频源高效地重建精确的人体化身。该方法集成了预训练的HuMoR模型(擅长人体运动估计)、先进的神经辐射场技术Instant-NGP以及最先进的铰接模型Fast-SNARF,以提高重建的保真度和速度。通过结合这些技术,系统能够快速有效地渲染,并提供无与伦比的人体姿态参数估计精度。此外,系统还采用了一种先进的姿态敏感空间缩减技术,以优化渲染质量和计算效率之间的平衡。在人工和真实单目视频上的实验分析表明,HumanAvatar在质量上始终与当代领先的重建技术相当或超越,并且能够在几分钟内完成复杂的重建,这只是现有方法所需时间的一小部分。该模型实现了比最先进的基于NeRF的模型快110倍的训练速度,并且在相同的运行时间限制下,性能明显优于最先进的动态人体NeRF方法。HumanAvatar仅需30秒的训练即可提供有效的视觉效果。
🔬 方法详解
问题定义:现有3D人体重建方法,特别是基于NeRF的方法,通常需要大量的计算资源和训练时间,难以实现快速、高效的重建,限制了其在交互式远程呈现、AR/VR等实时应用中的应用。此外,在单目视频输入的情况下,重建的精度和鲁棒性也面临挑战。
核心思路:HumanAvatar的核心思路是将预训练的人体运动估计模型HuMoR与神经辐射场技术Instant-NGP以及铰接模型Fast-SNARF相结合,利用HuMoR提供准确的姿态先验,指导Instant-NGP进行快速渲染,并借助Fast-SNARF提升重建的几何细节。通过姿态敏感的空间缩减技术,进一步优化计算效率,实现快速且高质量的3D人体化身重建。
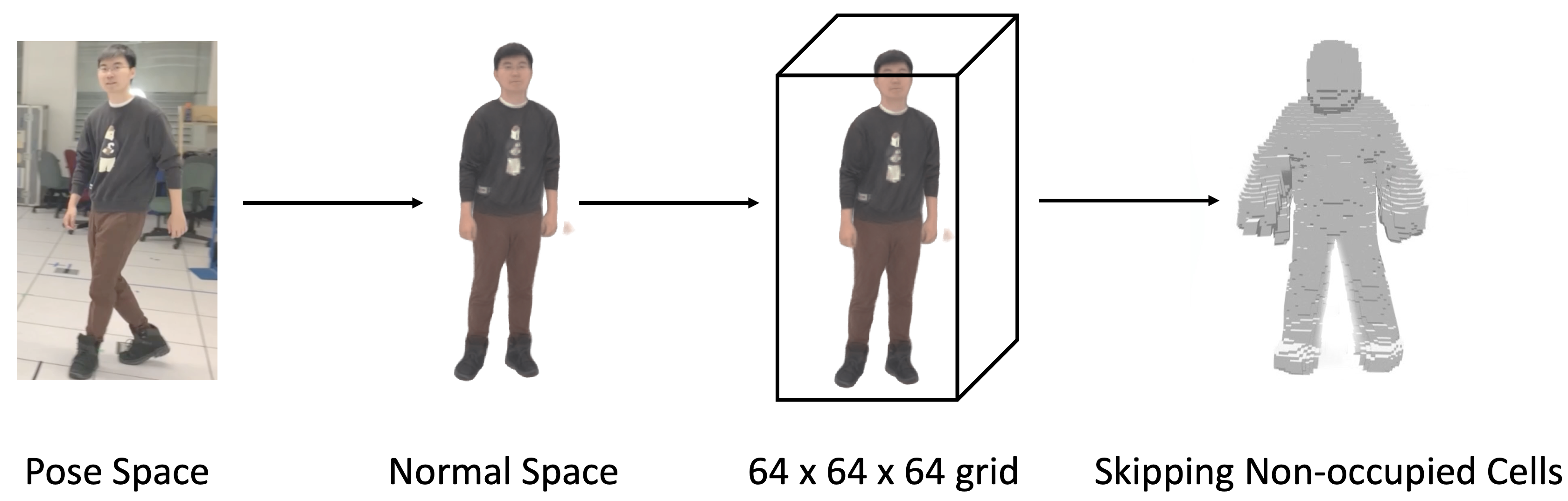
技术框架:HumanAvatar的整体框架包含以下几个主要模块:1) HuMoR姿态估计模块:从单目视频中提取人体姿态参数。2) Fast-SNARF铰接模型:提供人体形状和拓扑结构的先验知识。3) Instant-NGP神经辐射场:利用多分辨率哈希编码加速场景表示和渲染。4) 姿态敏感空间缩减模块:根据人体姿态动态调整渲染空间,减少计算量。整个流程首先利用HuMoR估计姿态,然后结合Fast-SNARF的先验信息,指导Instant-NGP进行训练和渲染,最后通过姿态敏感的空间缩减进一步提升效率。
关键创新:HumanAvatar的关键创新在于将预训练的人体运动估计模型与神经辐射场技术相结合,并引入姿态敏感的空间缩减技术。与传统的NeRF方法相比,HumanAvatar利用HuMoR提供的姿态先验,加速了NeRF的训练过程,并提高了重建的精度。姿态敏感的空间缩减技术则进一步优化了计算效率,使得HumanAvatar能够在短时间内完成高质量的重建。
关键设计:HumanAvatar的关键设计包括:1) HuMoR的集成:利用HuMoR预训练的强大姿态估计能力,为NeRF提供准确的姿态先验。2) Instant-NGP的多分辨率哈希编码:加速场景表示和渲染。3) Fast-SNARF的铰接模型:提供人体形状和拓扑结构的先验知识,提升重建的几何细节。4) 姿态敏感的空间缩减:根据人体姿态动态调整渲染空间,减少计算量。具体的损失函数设计未知,但推测会包含重建损失、姿态约束损失等。
🖼️ 关键图片
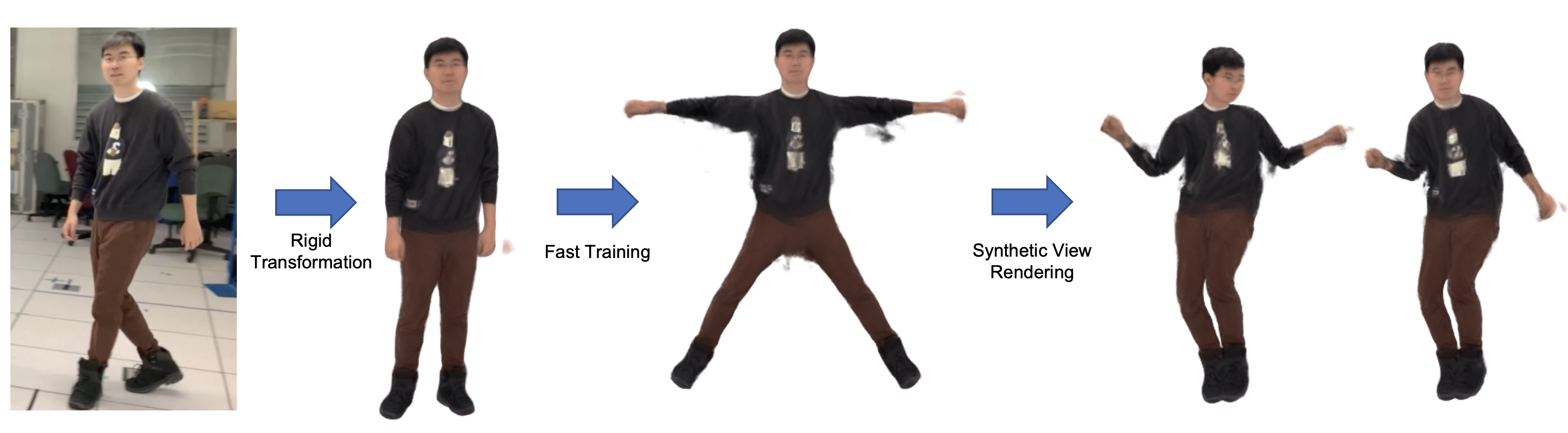

📊 实验亮点
HumanAvatar在人工和真实单目视频上进行了实验,结果表明其重建质量与现有最先进技术相当或超越。更重要的是,HumanAvatar的训练速度比最先进的基于NeRF的模型快110倍,并且在相同的运行时间限制下,性能明显优于最先进的动态人体NeRF方法。仅需30秒的训练即可提供有效的视觉效果,这大大缩短了重建时间,使其更适用于实时应用。
🎯 应用场景
HumanAvatar在交互式远程呈现、AR/VR、3D图形以及快速发展的元宇宙等领域具有广泛的应用前景。它可以用于创建逼真的虚拟化身,实现沉浸式的远程交流和协作,提升AR/VR体验的真实感和互动性。此外,该技术还可以应用于游戏开发、电影制作等领域,降低3D人体建模的成本和时间。
📄 摘要(原文)
High-fidelity digital human representations are increasingly in demand in the digital world, particularly for interactive telepresence, AR/VR, 3D graphics, and the rapidly evolving metaverse. Even though they work well in small spaces, conventional methods for reconstructing 3D human motion frequently require the use of expensive hardware and have high processing costs. This study presents HumanAvatar, an innovative approach that efficiently reconstructs precise human avatars from monocular video sources. At the core of our methodology, we integrate the pre-trained HuMoR, a model celebrated for its proficiency in human motion estimation. This is adeptly fused with the cutting-edge neural radiance field technology, Instant-NGP, and the state-of-the-art articulated model, Fast-SNARF, to enhance the reconstruction fidelity and speed. By combining these two technologies, a system is created that can render quickly and effectively while also providing estimation of human pose parameters that are unmatched in accuracy. We have enhanced our system with an advanced posture-sensitive space reduction technique, which optimally balances rendering quality with computational efficiency. In our detailed experimental analysis using both artificial and real-world monocular videos, we establish the advanced performance of our approach. HumanAvatar consistently equals or surpasses contemporary leading-edge reconstruction techniques in quality. Furthermore, it achieves these complex reconstructions in minutes, a fraction of the time typically required by existing methods. Our models achieve a training speed that is 110X faster than that of State-of-The-Art (SoTA) NeRF-based models. Our technique performs noticeably better than SoTA dynamic human NeRF methods if given an identical runtime limit. HumanAvatar can provide effective visuals after only 30 seconds of training.