Adversarial Score identity Distillation: Rapidly Surpassing the Teacher in One Step
作者: Mingyuan Zhou, Huangjie Zheng, Yi Gu, Zhendong Wang, Hai Huang
分类: cs.CV, cs.LG
发布日期: 2024-10-19 (更新: 2024-12-24)
备注: 10 pages (main text), 34 figures, and 10 tables
🔗 代码/项目: GITHUB
💡 一句话要点
提出SiDA:通过对抗蒸馏,单步超越教师模型的图像生成方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱四:生成式动作 (Generative Motion)
关键词: 图像生成 对抗学习 蒸馏训练 扩散模型 无数据学习
📋 核心要点
- 现有SiD方法依赖预训练扩散模型,但其生成质量受限于模型捕获真实数据分数的准确性。
- SiDA通过引入真实图像和对抗损失,利用生成器编码器作为判别器,提升生成质量和蒸馏效率。
- 实验表明,SiDA在ImageNet数据集上显著超越现有方法,单步生成即可达到更低的FID分数。
📝 摘要(中文)
Score identity Distillation (SiD) 是一种数据无关的方法,它仅利用预训练的扩散模型即可在图像生成方面实现 SOTA 性能,而无需任何训练数据。然而,其最终性能受到预训练模型在扩散过程的不同阶段捕获真实数据分数准确性的限制。本文介绍 SiDA (SiD with Adversarial Loss),它不仅提高了生成质量,还通过结合真实图像和对抗损失来提高蒸馏效率。SiDA 利用生成器分数网络中的编码器作为判别器,使其能够区分真实图像和 SiD 生成的图像。对抗损失在每个 GPU 内进行批归一化,然后与原始 SiD 损失相结合。这种集成有效地将每个 GPU 批次的平均“伪造性”纳入基于像素的 SiD 损失中,从而使 SiDA 能够蒸馏单步生成器。从头开始蒸馏时,SiDA 的收敛速度明显快于其前身,并且在从预蒸馏的 SiD 生成器进行微调时,可以迅速提高原始模型的性能。这种单步对抗蒸馏方法在蒸馏 EDM 扩散模型时建立了新的生成性能基准,在 ImageNet 64x64 上实现了 1.110 的 FID 分数。在蒸馏在 ImageNet 512x512 上训练的 EDM2 模型时,我们的 SiDA 方法甚至超越了最大的教师模型 EDM2-XXL,该模型使用无分类器指导 (CFG) 和 63 个生成步骤实现了 1.81 的 FID。相比之下,SiDA 在 XS 尺寸下实现了 2.156 的 FID 分数,S 尺寸下为 1.669,M 尺寸下为 1.488,L 尺寸下为 1.413,XL 尺寸下为 1.379,XXL 尺寸下为 1.366,所有这些都无需 CFG 且仅需一个生成步骤。这些结果突出了所有模型尺寸的显着改进。
🔬 方法详解
问题定义:现有的 Score identity Distillation (SiD) 方法虽然在图像生成领域取得了不错的成果,但其性能上限受到预训练扩散模型质量的限制。具体来说,如果预训练模型不能准确地捕捉真实数据在扩散过程中的分数,那么蒸馏得到的生成器性能也会受到影响。此外,SiD的蒸馏过程可能需要较长的训练时间才能达到理想效果。
核心思路:SiDA 的核心思路是通过引入对抗学习机制来提升蒸馏效果。具体来说,SiDA 将生成器的编码器部分用作判别器,用于区分真实图像和生成图像。通过对抗损失,可以促使生成器生成更逼真的图像,从而提高蒸馏的效率和最终生成质量。这种方法相当于在像素级别的 SiD 损失中加入了对生成图像“真实性”的约束。
技术框架:SiDA 的整体框架可以概括为以下几个步骤:1. 使用预训练的扩散模型作为教师模型。2. 初始化一个生成器网络,其编码器部分将作为判别器。3. 使用 SiD 损失来训练生成器,使其能够模仿教师模型的行为。4. 同时,使用对抗损失来训练生成器和判别器,促使生成器生成更逼真的图像。5. 将 SiD 损失和对抗损失结合起来,共同优化生成器。
关键创新:SiDA 的关键创新在于将对抗学习引入到 Score identity Distillation 框架中。通过对抗损失,可以有效地提高生成图像的质量,并加速蒸馏过程。与传统的 SiD 方法相比,SiDA 不需要依赖于完美的教师模型,而是可以通过对抗学习来纠正教师模型的不足。此外,SiDA 实现了单步生成,大大提高了生成效率。
关键设计:SiDA 的关键设计包括:1. 使用生成器的编码器作为判别器,简化了网络结构。2. 在每个 GPU 上进行批归一化,以稳定训练过程。3. 将对抗损失与 SiD 损失相结合,平衡了生成器的模仿能力和生成质量。4. 使用合适的对抗损失函数,例如 hinge loss 或 LSGAN loss,以获得更好的生成效果。具体的损失函数权重需要根据实验进行调整。
🖼️ 关键图片

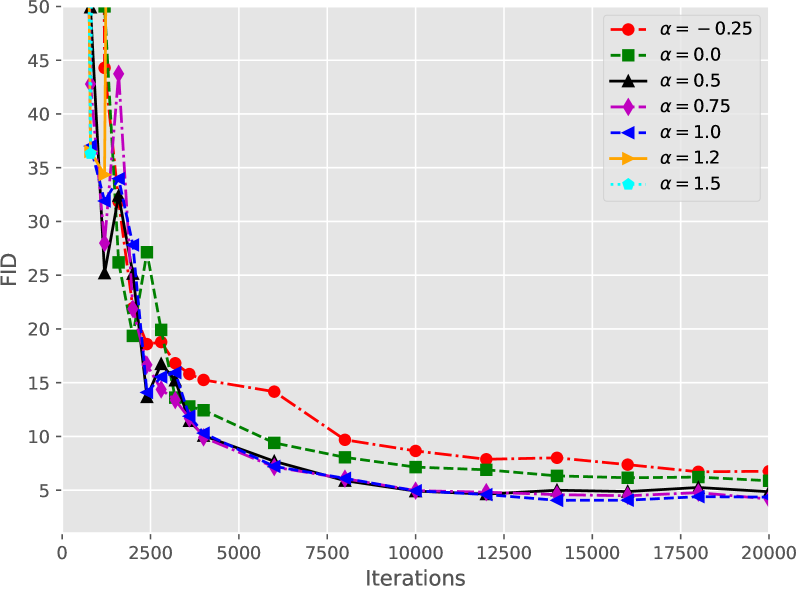
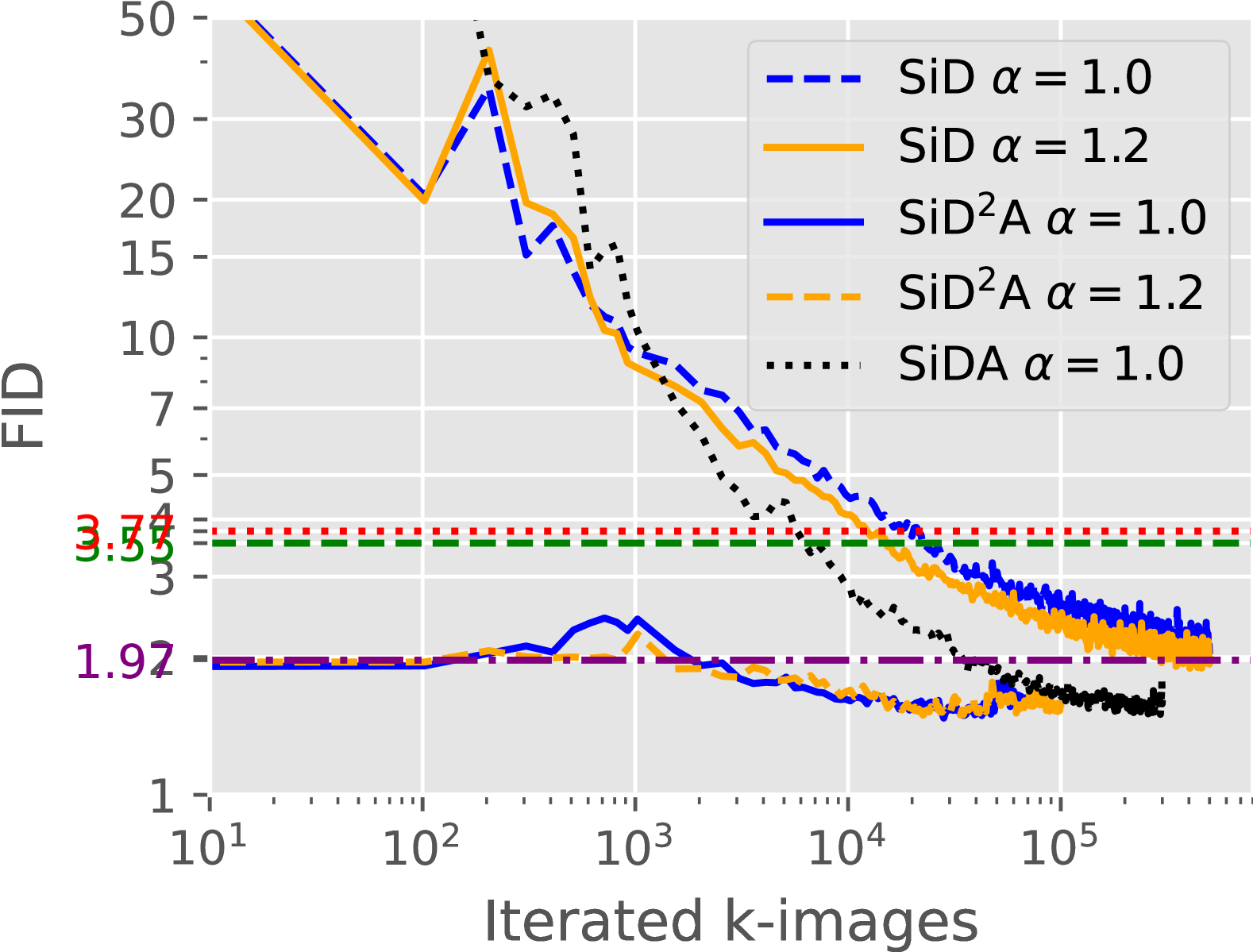
📊 实验亮点
SiDA 在 ImageNet 数据集上取得了显著的性能提升。在 ImageNet 64x64 上,SiDA 实现了 1.110 的 FID 分数,超越了现有的 SOTA 方法。更重要的是,在 ImageNet 512x512 上,SiDA 甚至超越了最大的教师模型 EDM2-XXL,在各种模型尺寸下均取得了更低的 FID 分数,例如 XXL 尺寸下达到了 1.366 的 FID 分数,而 EDM2-XXL 的 FID 分数为 1.81。所有这些结果都是在单步生成且不使用 CFG 的情况下获得的。
🎯 应用场景
SiDA 的潜在应用领域包括图像生成、图像编辑、图像修复等。该方法可以用于快速生成高质量的图像,无需大量的训练数据。此外,SiDA 还可以用于个性化图像生成,例如根据用户的偏好生成特定的图像风格。未来,SiDA 有望在游戏开发、虚拟现实、广告设计等领域发挥重要作用。
📄 摘要(原文)
Score identity Distillation (SiD) is a data-free method that has achieved SOTA performance in image generation by leveraging only a pretrained diffusion model, without requiring any training data. However, its ultimate performance is constrained by how accurate the pretrained model captures the true data scores at different stages of the diffusion process. In this paper, we introduce SiDA (SiD with Adversarial Loss), which not only enhances generation quality but also improves distillation efficiency by incorporating real images and adversarial loss. SiDA utilizes the encoder from the generator's score network as a discriminator, allowing it to distinguish between real images and those generated by SiD. The adversarial loss is batch-normalized within each GPU and then combined with the original SiD loss. This integration effectively incorporates the average "fakeness" per GPU batch into the pixel-based SiD loss, enabling SiDA to distill a single-step generator. SiDA converges significantly faster than its predecessor when distilled from scratch, and swiftly improves upon the original model's performance during fine-tuning from a pre-distilled SiD generator. This one-step adversarial distillation method establishes new benchmarks in generation performance when distilling EDM diffusion models, achieving FID scores of 1.110 on ImageNet 64x64. When distilling EDM2 models trained on ImageNet 512x512, our SiDA method surpasses even the largest teacher model, EDM2-XXL, which achieved an FID of 1.81 using classifier-free guidance (CFG) and 63 generation steps. In contrast, SiDA achieves FID scores of 2.156 for size XS, 1.669 for S, 1.488 for M, 1.413 for L, 1.379 for XL, and 1.366 for XXL, all without CFG and in a single generation step. These results highlight substantial improvements across all model sizes. Our code is available at https://github.com/mingyuanzhou/SiD/tree/sida.